VisMin: Visual Minimal-Change Understanding
作者: Rabiul Awal, Saba Ahmadi, Le Zhang, Aishwarya Agrawal
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-07-23 (更新: 2025-01-22)
备注: Accepted at NeurIPS 2024. Project URL at https://vismin.net/
💡 一句话要点
提出VisMin基准,用于评估视觉语言模型在细粒度视觉理解上的能力
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 细粒度理解 基准测试 最小变化 空间关系
📋 核心要点
- 现有视觉语言模型(VLM)基准测试主要评估模型区分相似描述文字的能力,缺乏对细粒度视觉理解的深入考察。
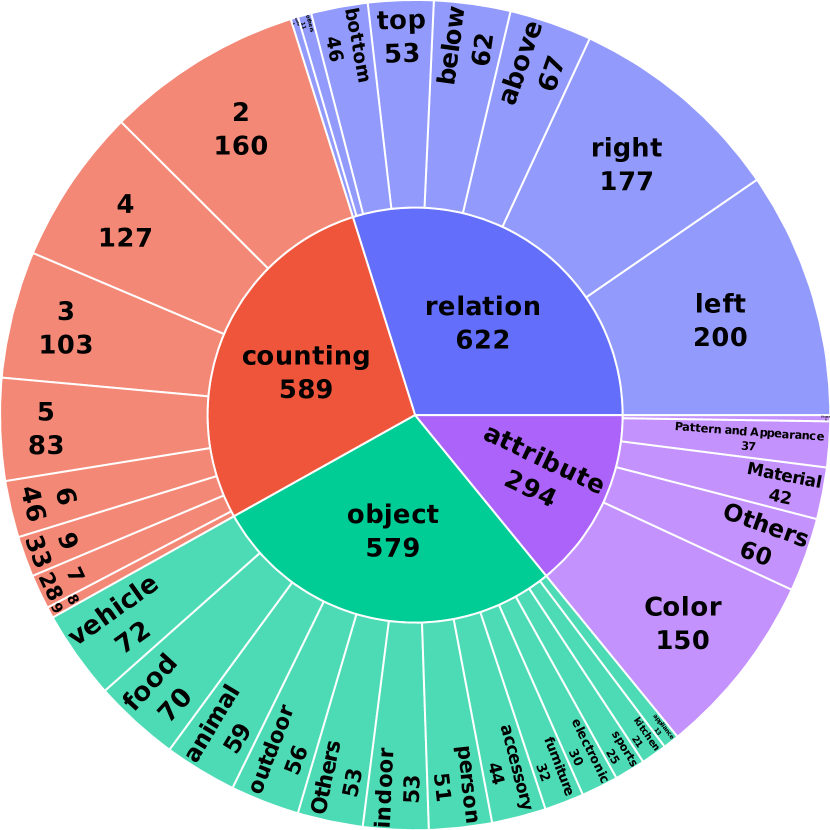
- VisMin基准通过最小化图像和文本的变化,聚焦于对象、属性、计数和空间关系等细粒度视觉元素的理解。
- 实验表明现有VLM在空间关系和计数方面存在不足,通过VisMin训练数据微调CLIP和Idefics2可显著提升性能。
📝 摘要(中文)
本文提出了一个新的、具有挑战性的基准测试,名为视觉最小变化理解(VisMin),旨在评估视觉语言模型(VLMs)在细粒度理解上的能力。该基准要求模型预测给定两张图像和两段描述文字中正确的图像-文字匹配。图像对和文字对包含最小的变化,即每次只改变一个方面,包括对象、属性、计数和空间关系。这些变化测试了模型对对象、属性(如颜色、材料、形状)、计数以及对象之间空间关系的理解。我们构建了一个使用大型语言模型和扩散模型的自动框架,然后由人工标注者进行严格的四步验证过程。实验结果表明,当前的VLMs在理解空间关系和计数能力方面存在明显的不足。我们还生成了一个大规模的训练数据集来微调CLIP和Idefics2,从而在各个基准测试中显著提高了细粒度理解能力,并提升了CLIP的通用图像-文本对齐能力。我们发布了所有资源,包括基准、训练数据和微调后的模型检查点。
🔬 方法详解
问题定义:现有视觉语言模型评估基准主要集中在区分非常相似的文本描述,而忽略了对图像中细粒度视觉元素(如对象属性、数量和空间关系)的深入理解。因此,现有方法难以有效评估模型在这些方面的能力,限制了模型在需要精细视觉理解任务中的应用。
核心思路:VisMin基准的核心思路是通过构造包含最小变化的图像和文本对,迫使模型关注图像中细微的视觉差异。通过控制每次只改变一个视觉元素(对象、属性、数量、空间关系),可以更精确地评估模型对特定视觉概念的理解能力。这种设计使得基准测试更具挑战性,更能反映模型在实际应用中的表现。
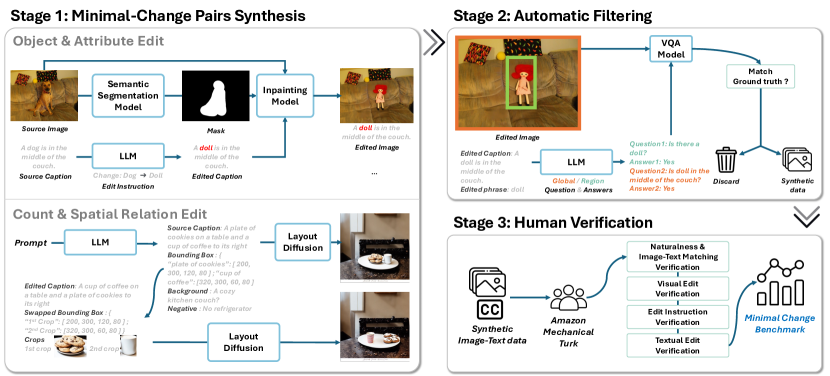
技术框架:VisMin的构建包含以下几个主要阶段:1) 使用大型语言模型(LLM)生成候选图像和文本对;2) 使用扩散模型生成对应的图像;3) 通过人工标注进行四步验证,确保图像和文本对的质量和一致性;4) 构建大规模训练数据集,用于微调现有VLM模型。整个流程旨在自动化生成高质量的细粒度视觉理解数据集。
关键创新:VisMin基准的关键创新在于其对“最小变化”的严格控制。通过每次只改变一个视觉元素,可以更精确地评估模型对该元素的理解能力。此外,VisMin还提供了一个大规模的训练数据集,可以用于微调现有VLM模型,从而提高其在细粒度视觉理解方面的性能。这种训练数据与评估基准的结合,为VLM的研究和发展提供了有力的支持。
关键设计:VisMin基准的关键设计包括:1) 使用LLM生成多样化的候选图像和文本对;2) 使用扩散模型生成高质量的图像,保证图像的真实性和多样性;3) 采用四步人工验证流程,确保数据集的质量和一致性,包括图像和文本的相关性、最小变化的准确性等;4) 提供大规模训练数据集,包含多种视觉元素的变化,用于微调VLM模型。此外,还提供了微调后的模型检查点,方便研究人员使用。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有VLM在VisMin基准上表现不佳,尤其是在空间关系和计数方面。例如,模型在理解“在桌子上的苹果”和“在桌子下的苹果”之间的差异时存在困难。通过使用VisMin训练数据微调CLIP和Idefics2,模型在VisMin基准以及其他基准测试中都取得了显著的性能提升,证明了VisMin数据集的有效性。CLIP在VisMin基准上提升了超过10%。
🎯 应用场景
VisMin基准的潜在应用领域包括:视觉问答、图像编辑、机器人导航、自动驾驶等。通过提高模型对细粒度视觉元素的理解能力,可以提升这些应用在复杂环境中的性能和可靠性。例如,在机器人导航中,模型需要准确理解物体之间的空间关系才能做出正确的决策。VisMin的研究成果有助于推动视觉语言模型在实际场景中的应用。
📄 摘要(原文)
Fine-grained understanding of objects, attributes, and relationships between objects is crucial for visual-language models (VLMs). Existing benchmarks primarily focus on evaluating VLMs' capability to distinguish between two very similar captions given an image. In this paper, we introduce a new, challenging benchmark termed Visual Minimal-Change Understanding (VisMin), which requires models to predict the correct image-caption match given two images and two captions. The image pair and caption pair contain minimal changes, i.e., only one aspect changes at a time from among the following: object, attribute, count, and spatial relation. These changes test the models' understanding of objects, attributes (such as color, material, shape), counts, and spatial relationships between objects. We built an automatic framework using large language models and diffusion models, followed by a rigorous 4-step verification process by human annotators. Empirical experiments reveal that current VLMs exhibit notable deficiencies in understanding spatial relationships and counting abilities. We also generate a large-scale training dataset to finetune CLIP and Idefics2, showing significant improvements in fine-grained understanding across benchmarks and in CLIP's general image-text alignment. We release all resources, including the benchmark, training data, and finetuned model checkpoints, at https://vismin.net/.