PartGLEE: A Foundation Model for Recognizing and Parsing Any Objects
作者: Junyi Li, Junfeng Wu, Weizhi Zhao, Song Bai, Xiang Bai
分类: cs.CV
发布日期: 2024-07-23
备注: Accepted by ECCV2024, homepage: https://provencestar.github.io/PartGLEE-Vision/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PartGLEE:用于识别和解析任意对象部件的部件级基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 部件级识别 基础模型 层级建模 Q-Former 开放世界 物体解析 视觉理解
📋 核心要点
- 现有方法在开放世界场景下,难以同时兼顾物体及其部件的检测、分割和语义关联。
- PartGLEE通过引入Q-Former构建物体和部件之间的层级关系,实现细粒度的部件解析和识别。
- 实验表明,PartGLEE在部件级任务上达到SOTA,并在物体级任务上具有竞争力,提升了层级认知能力。
📝 摘要(中文)
本文提出了PartGLEE,一个部件级别的基础模型,用于在图像中定位和识别物体及其部件。PartGLEE通过一个统一的框架,实现了在开放世界场景下对任意粒度的实例进行检测、分割和grounding。具体来说,我们提出了一个Q-Former来构建物体和部件之间的层级关系,将每个物体解析成相应的语义部件。通过整合大量的物体级别数据,层级关系可以被扩展,使得PartGLEE能够识别丰富的部件种类。我们进行了全面的研究来验证我们方法的有效性,PartGLEE在各种部件级别的任务上取得了最先进的性能,并在物体级别的任务上获得了有竞争力的结果。所提出的PartGLEE显著增强了层级建模能力和部件级别的感知能力,优于我们之前的GLEE模型。进一步的分析表明,PartGLEE的层级认知能力能够促进mLLM对图像的详细理解。
🔬 方法详解
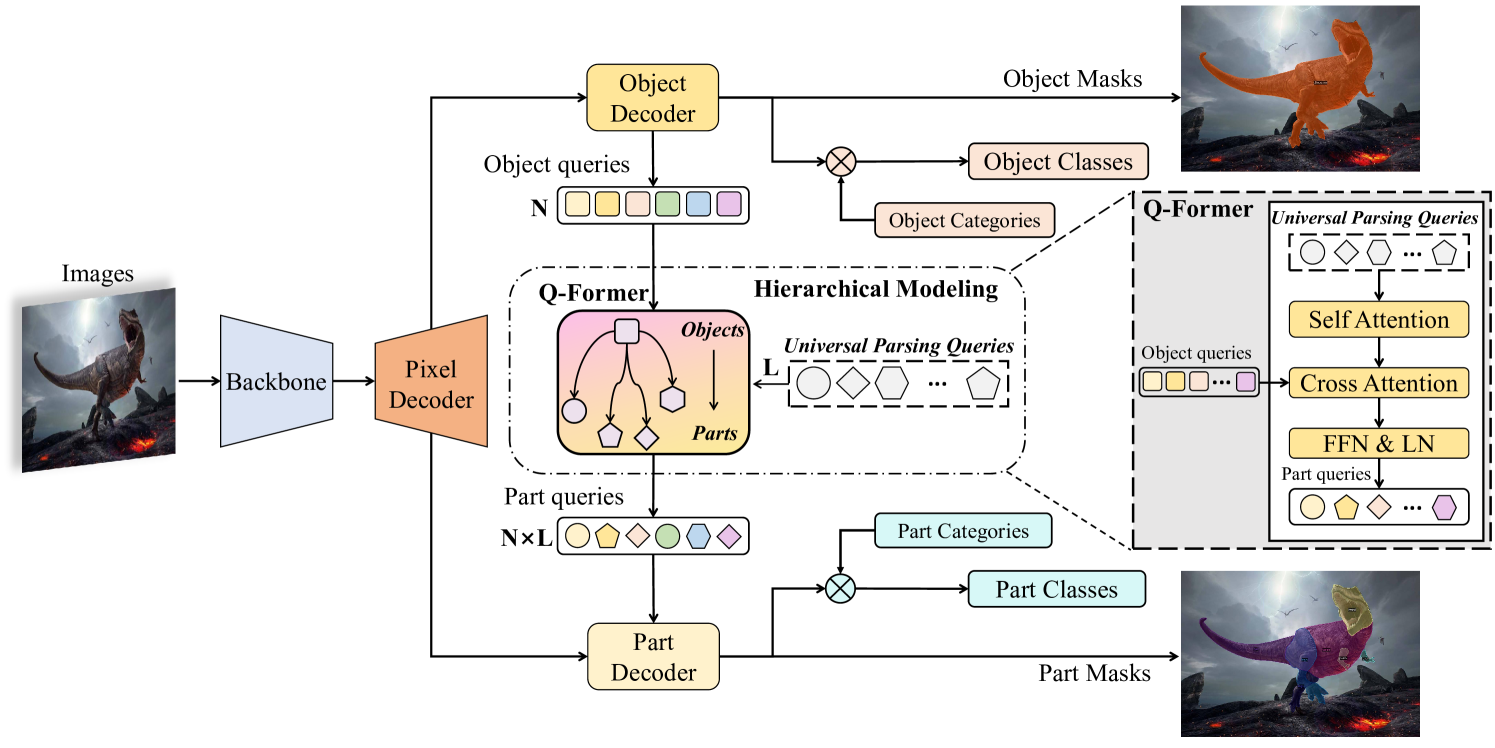
问题定义:现有方法在处理开放世界场景下的物体识别和解析任务时,往往难以同时兼顾物体及其部件的检测、分割和语义关联。尤其是在部件级别的理解上,现有模型的泛化能力和细粒度识别能力存在不足,难以应对复杂场景和多样化的物体结构。
核心思路:PartGLEE的核心思路是构建一个部件级别的基础模型,通过学习物体及其部件之间的层级关系,实现对图像中任意粒度的实例进行检测、分割和grounding。通过引入Q-Former,模型能够有效地解析物体,并将其分解为相应的语义部件,从而提升对图像内容的理解能力。
技术框架:PartGLEE的整体框架包含以下几个主要模块:1)图像输入模块,负责接收输入的图像数据;2)特征提取模块,用于提取图像的视觉特征;3)Q-Former模块,用于构建物体和部件之间的层级关系,并将物体解析为语义部件;4)检测、分割和grounding模块,基于学习到的层级关系,实现对物体及其部件的检测、分割和语义关联。整个流程旨在实现对图像内容的细粒度理解和解析。
关键创新:PartGLEE最重要的技术创新点在于引入了Q-Former来构建物体和部件之间的层级关系。与现有方法相比,PartGLEE能够更有效地解析物体,并将其分解为语义部件,从而提升了模型对图像内容的理解能力。此外,通过整合大量的物体级别数据,PartGLEE能够识别更丰富的部件种类,从而提升了模型的泛化能力。
关键设计:PartGLEE的关键设计包括:1)Q-Former的具体结构和参数设置,例如Transformer的层数、注意力头的数量等;2)损失函数的设计,用于指导模型学习物体和部件之间的层级关系;3)训练数据的选择和预处理方法,以保证模型能够学习到有效的特征表示。
🖼️ 关键图片


📊 实验亮点
PartGLEE在多个部件级别的任务上取得了state-of-the-art的性能,例如在细粒度图像分类和部件分割任务上,PartGLEE的性能显著优于现有方法。此外,PartGLEE在物体级别的任务上也取得了有竞争力的结果,表明其具有良好的泛化能力。实验结果表明,PartGLEE能够有效地提升层级建模能力和部件级别的感知能力。
🎯 应用场景
PartGLEE在机器人视觉、自动驾驶、图像编辑和智能标注等领域具有广泛的应用前景。例如,在机器人视觉中,PartGLEE可以帮助机器人理解物体的结构和功能,从而实现更智能的交互。在自动驾驶中,PartGLEE可以帮助车辆识别交通标志和行人,从而提高驾驶安全性。在图像编辑和智能标注中,PartGLEE可以自动识别图像中的物体及其部件,从而提高编辑和标注效率。
📄 摘要(原文)
We present PartGLEE, a part-level foundation model for locating and identifying both objects and parts in images. Through a unified framework, PartGLEE accomplishes detection, segmentation, and grounding of instances at any granularity in the open world scenario. Specifically, we propose a Q-Former to construct the hierarchical relationship between objects and parts, parsing every object into corresponding semantic parts. By incorporating a large amount of object-level data, the hierarchical relationships can be extended, enabling PartGLEE to recognize a rich variety of parts. We conduct comprehensive studies to validate the effectiveness of our method, PartGLEE achieves the state-of-the-art performance across various part-level tasks and obtain competitive results on object-level tasks. The proposed PartGLEE significantly enhances hierarchical modeling capabilities and part-level perception over our previous GLEE model. Further analysis indicates that the hierarchical cognitive ability of PartGLEE is able to facilitate a detailed comprehension in images for mLLMs. The model and code will be released at https://provencestar.github.io/PartGLEE-Vision/ .