Reinforcement Learning Meets Visual Odometry
作者: Nico Messikommer, Giovanni Cioffi, Mathias Gehrig, Davide Scaramuzza
分类: cs.CV, cs.RO
发布日期: 2024-07-22
期刊: European Conference on Computer Vision (ECCV 2024)
💡 一句话要点
提出基于强化学习的视觉里程计框架,自适应优化关键参数,提升精度与鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉里程计 强化学习 序列决策 参数优化 机器人定位
📋 核心要点
- 现有视觉里程计方法依赖人工启发式设计和耗时调参,难以保证通用性和鲁棒性。
- 将视觉里程计建模为序列决策过程,利用强化学习动态优化关键帧选择和网格尺寸等参数。
- 实验表明,该方法在精度和鲁棒性方面均有提升,验证了其在不同场景下的泛化能力。
📝 摘要(中文)
视觉里程计(VO)对于移动机器人和增强/虚拟现实任务至关重要。尽管最近取得了进展,现有的VO方法仍然依赖于启发式设计选择,需要人类专家花费数周时间进行超参数调整,这限制了泛化性和鲁棒性。我们通过将VO重新定义为序列决策任务,并应用强化学习(RL)来动态调整VO过程,从而应对这些挑战。我们的方法引入了一个神经网络,作为VO管道中的代理,根据实时条件做出诸如关键帧和网格大小选择等决策。我们的方法使用基于姿态误差、运行时间和其它指标的奖励函数来指导系统,从而最大限度地减少对启发式选择的依赖。我们的RL框架将VO系统和图像序列视为环境,代理接收来自关键点、地图统计信息和先前姿态的观察。使用经典VO方法和公共基准的实验结果表明,精度和鲁棒性得到了提高,验证了我们RL增强的VO方法对不同场景的通用性。我们相信这种范式转变通过消除对启发式算法进行耗时参数调整的需求,从而推进了VO技术。
🔬 方法详解
问题定义:现有视觉里程计方法依赖于人工设计的启发式规则和大量的超参数调整,这使得它们在面对不同环境和场景时难以保持良好的性能。人工调参过程耗时且需要专业知识,限制了VO系统的通用性和鲁棒性。因此,需要一种能够自适应调整参数,从而提高VO系统性能的方法。
核心思路:论文的核心思路是将视觉里程计问题建模为一个序列决策问题,并利用强化学习来训练一个智能体(agent),该智能体能够根据当前环境的状态(例如,图像特征、地图统计信息等)动态地调整VO系统的参数,例如关键帧的选择和网格尺寸的设置。通过这种方式,VO系统可以根据实际情况进行自适应优化,从而提高其性能。
技术框架:该方法的技术框架主要包括以下几个部分:1) VO系统:使用现有的经典VO方法作为基础;2) 强化学习智能体:一个神经网络,负责根据环境状态做出决策;3) 环境:VO系统和图像序列,提供状态信息和接收智能体的动作;4) 奖励函数:用于评估智能体行为的指标,包括姿态误差、运行时间等。智能体通过与环境交互,不断学习和优化其决策策略。
关键创新:该方法最重要的技术创新点在于将强化学习引入到视觉里程计中,实现了VO系统参数的自适应优化。与传统的VO方法相比,该方法不再依赖于人工设计的启发式规则和大量的超参数调整,而是通过强化学习自动学习最优的参数配置。这种方法可以提高VO系统的通用性和鲁棒性,使其能够更好地适应不同的环境和场景。
关键设计:奖励函数的设计是关键。论文中,奖励函数综合考虑了姿态误差、运行时间等因素,旨在引导智能体学习到既准确又高效的VO策略。智能体的网络结构也需要精心设计,以能够有效地提取环境状态的特征,并做出合理的决策。具体的网络结构和参数设置在论文中可能有所描述,但此处无法得知具体细节。
🖼️ 关键图片


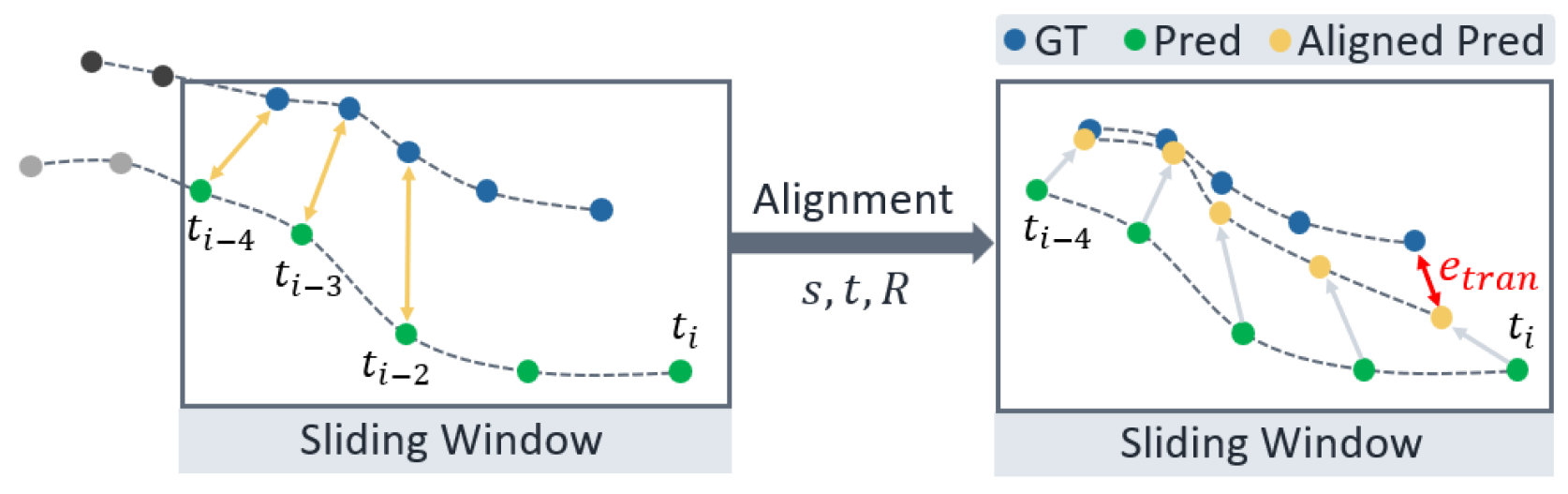
📊 实验亮点
论文通过实验验证了该方法的有效性,在公共数据集上,与传统的VO方法相比,该方法在精度和鲁棒性方面均有提升。具体的性能数据(例如,姿态误差的降低幅度)和对比基线在论文中应该有详细描述,但此处未知。
🎯 应用场景
该研究成果可广泛应用于移动机器人、增强现实、虚拟现实等领域。通过自适应优化视觉里程计参数,可以提高定位精度和鲁棒性,从而提升相关应用的用户体验和可靠性。例如,在无人驾驶汽车中,可以利用该方法提高车辆的定位精度,从而提高行驶安全性。在AR/VR应用中,可以提高虚拟物体的定位精度,增强沉浸感。
📄 摘要(原文)
Visual Odometry (VO) is essential to downstream mobile robotics and augmented/virtual reality tasks. Despite recent advances, existing VO methods still rely on heuristic design choices that require several weeks of hyperparameter tuning by human experts, hindering generalizability and robustness. We address these challenges by reframing VO as a sequential decision-making task and applying Reinforcement Learning (RL) to adapt the VO process dynamically. Our approach introduces a neural network, operating as an agent within the VO pipeline, to make decisions such as keyframe and grid-size selection based on real-time conditions. Our method minimizes reliance on heuristic choices using a reward function based on pose error, runtime, and other metrics to guide the system. Our RL framework treats the VO system and the image sequence as an environment, with the agent receiving observations from keypoints, map statistics, and prior poses. Experimental results using classical VO methods and public benchmarks demonstrate improvements in accuracy and robustness, validating the generalizability of our RL-enhanced VO approach to different scenarios. We believe this paradigm shift advances VO technology by eliminating the need for time-intensive parameter tuning of heuristics.