Scaling Up Single Image Dehazing Algorithm by Cross-Data Vision Alignment for Richer Representation Learning and Beyond
作者: Yukai Shi, Zhipeng Weng, Yupei Lin, Cidan Shi, Xiaojun Yang, Liang Lin
分类: cs.CV, cs.AI, cs.LG, cs.MM, eess.IV
发布日期: 2024-07-20 (更新: 2025-03-20)
备注: A cross-dataset vision alignment and augmentation technology is proposed to boost generalizable feature learning in the de-hazing task
💡 一句话要点
提出基于跨数据视觉对齐的单图像去雾算法,提升表征学习能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 单图像去雾 跨数据学习 视觉对齐 领域自适应 表征学习 深度学习 图像增强
📋 核心要点
- 现有去雾方法忽略了不同数据集间的领域差异,直接使用多数据集训练效果不佳。
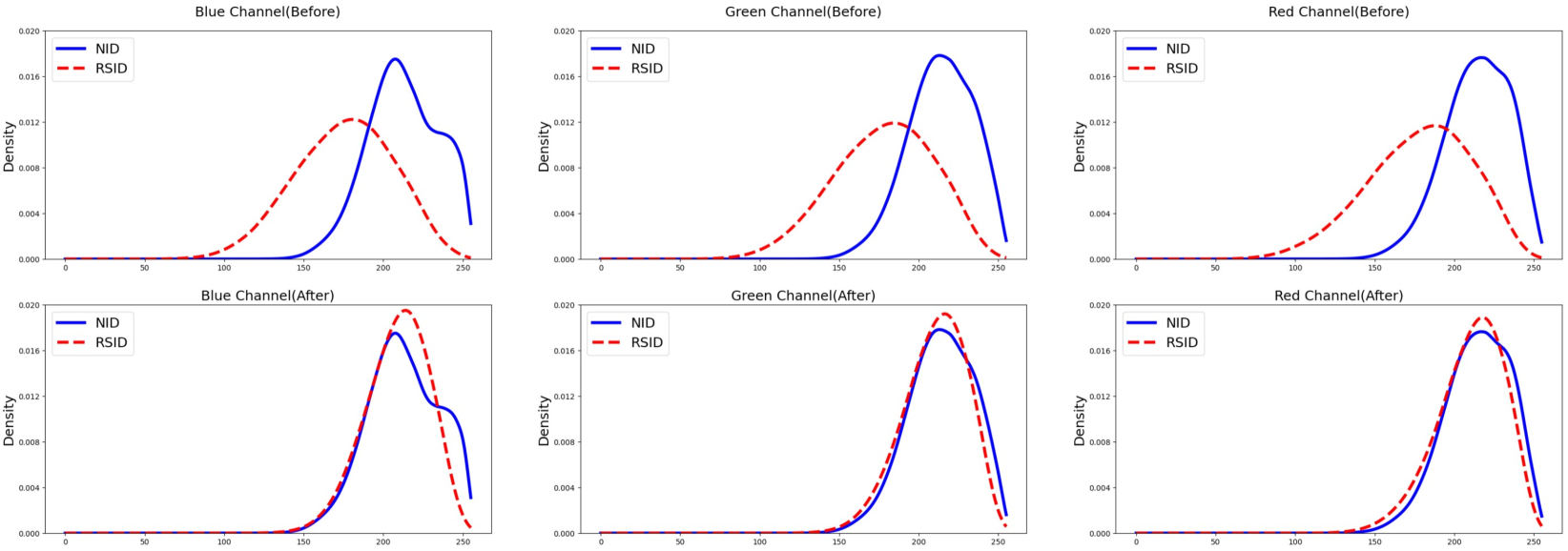
- 提出跨数据视觉对齐方法,通过自监督学习对齐内外知识,弥补领域差距。
- 实验表明,该方法有效解决了领域差距,并在去雾效果上优于其他先进方法。
📝 摘要(中文)
近年来,深度神经网络任务越来越依赖于高质量的图像输入。随着高分辨率表征学习的发展,图像去雾任务受到了广泛关注。以往的方法通常收集各种图像数据进行大规模训练,以提高在目标场景上的性能。然而,这些方法忽略了不同数据之间的领域差距,简单地采用多个数据集进行显式的大规模训练,这往往会适得其反。为了解决这个问题,我们提出了一种新颖的跨数据视觉对齐方法,用于更丰富的表征学习,从而改进现有的去雾方法。具体来说,我们呼吁以自监督的方式进一步调整内部和外部知识,以填补领域差距。通过使用跨数据外部对齐,数据集继承了来自不同领域的样本,这些样本被牢固地对齐,使模型能够学习更鲁棒和更具泛化性的特征。通过使用内部增强方法,模型可以充分利用图像内的局部信息,从而获得更多的图像细节。为了证明我们提出的方法的有效性,我们在自然图像数据集(NID)上进行了训练。实验结果表明,我们的方法清楚地解决了不同去雾数据集中的领域差距,并为去雾任务中的大规模训练提供了一个新的流程。我们的方法明显优于其他先进的去雾方法,并生成最接近真实无雾图像的去雾图像。
🔬 方法详解
问题定义:论文旨在解决单图像去雾任务中,由于不同数据集之间存在领域差异,导致模型在单一数据集上训练后泛化能力不足的问题。现有方法简单地混合多个数据集进行训练,忽略了数据分布的差异,导致模型性能下降。
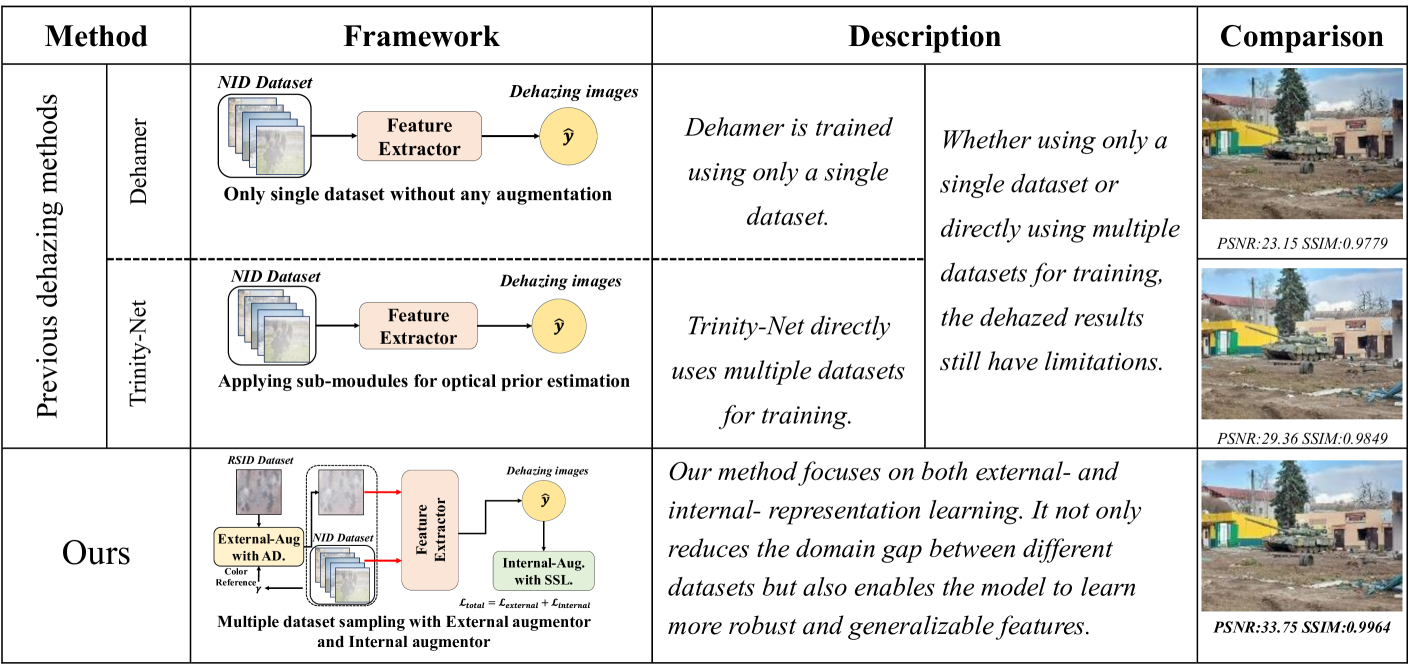
核心思路:论文的核心思路是通过跨数据视觉对齐,使得模型能够学习到更鲁棒和更具泛化性的特征。具体来说,通过外部对齐,将来自不同领域的样本进行对齐,减少领域差异;通过内部增强,充分利用图像内的局部信息,提取更多细节。
技术框架:该方法主要包含两个关键模块:跨数据外部对齐和内部增强。跨数据外部对齐旨在对齐不同数据集的特征分布,减少领域差异。内部增强则侧重于挖掘单张图像内部的局部信息,提升细节恢复能力。整体流程是先进行跨数据外部对齐,再进行内部增强,最后进行去雾模型的训练。
关键创新:该方法最重要的创新点在于提出了跨数据视觉对齐的思想,通过外部对齐和内部增强相结合的方式,有效地解决了不同数据集之间的领域差异问题。与现有方法直接混合数据集训练不同,该方法更加注重数据的对齐和信息的挖掘。
关键设计:论文中,跨数据外部对齐的具体实现方式未知,需要查阅论文细节。内部增强方法也需要进一步了解具体实现。损失函数的设计可能包含重建损失、对抗损失等,以保证去雾效果和图像质量。网络结构的选择也至关重要,可能采用U-Net或其他先进的去雾网络结构。
🖼️ 关键图片

📊 实验亮点
论文在自然图像数据集(NID)上进行了实验,结果表明该方法能够有效解决不同去雾数据集中的领域差距,并在去雾效果上明显优于其他先进方法。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于智能交通、安防监控、遥感图像处理等领域。在这些场景中,图像常常受到雾霾影响,导致图像质量下降,影响后续分析和识别。该方法能够有效去除雾霾,提高图像清晰度,提升相关应用的性能和可靠性,具有重要的实际应用价值。
📄 摘要(原文)
In recent years, deep neural networks tasks have increasingly relied on high-quality image inputs. With the development of high-resolution representation learning, the task of image dehazing has received significant attention. Previously, many methods collect diverse image data for large-scale training to boost the performance on a target scene. Ignoring the domain gap between different data, former de-hazing methods simply adopt multiple datasets for explicit large-scale training, which often makes the methods themselves be violated. To address this problem, we propose a novel method of cross-data vision alignment for richer representation learning to improve the existing dehazing methodology. Specifically, we call for the internal- and external knowledge should be further adapted with a self-supervised manner to fill up the domain gap. By using cross-data external alignment, the datasets inherit samples from different domains that are firmly aligned, making the model learn more robust and generalizable features. By using the internal augmentation method, the model can fully exploit local information within the images, and then obtaining more image details. To demonstrate the effectiveness of our proposed method, we conduct training on the Natural Image Dataset (NID). Experimental results show that our method clearly resolves the domain gap in different dehazing datasets and presents a new pipeline for large-scale training in the dehazing task. Our approach significantly outperforms other advanced methods in dehazing and produces dehazed images that are closest to real haze-free images.