Img2CAD: Reverse Engineering 3D CAD Models from Images through VLM-Assisted Conditional Factorization
作者: Yang You, Mikaela Angelina Uy, Jiaqi Han, Rahul Thomas, Haotong Zhang, Yi Du, Hansheng Chen, Francis Engelmann, Suya You, Leonidas Guibas
分类: cs.CV, cs.GR
发布日期: 2024-07-19 (更新: 2025-09-19)
备注: Accepted to SIGGRAPH Asia 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于VLM辅助条件分解的Img2CAD方法,从图像逆向工程3D CAD模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像逆向工程 3D CAD模型 视觉-语言模型 条件分解 TrAssembler
📋 核心要点
- 现有方法难以应对CAD模型与图像之间巨大的表征差异,以及图像本身的光度变化和噪声。
- 论文核心思想是将逆向工程任务分解为离散结构预测和连续属性预测两个子问题,并利用VLM进行辅助。
- 论文构建了带注释的CAD数据集,并提出了TrAssembler模型,为CAD化真实图像提供了初步解决方案。
📝 摘要(中文)
本文提出了一种从图像逆向工程3D计算机辅助设计(CAD)模型的新方法。该任务对交互式编辑、制造、建筑和机器人等下游应用至关重要。任务的难点在于CAD输出和图像输入之间巨大的表征差异。CAD模型是精确的、程序化的结构,涉及将离散命令结构与连续属性相结合的顺序操作,这使得端到端学习和优化具有挑战性。同时,输入图像引入了光度变化和传感器噪声等固有挑战,使逆向工程过程复杂化。本文将任务有条件地分解为两个子问题。首先,利用视觉-语言基础模型(VLMs),一个微调的Llama3.2,来预测具有语义信息的全局离散基础结构。其次,提出TrAssembler,它以具有语义信息的离散结构为条件,预测连续属性值。为了支持TrAssembler的训练,进一步构建了一个来自ShapeNet的常见对象的带注释的CAD数据集。总而言之,该方法和数据证明了在CAD化真实图像方面迈出了重要的第一步。
🔬 方法详解
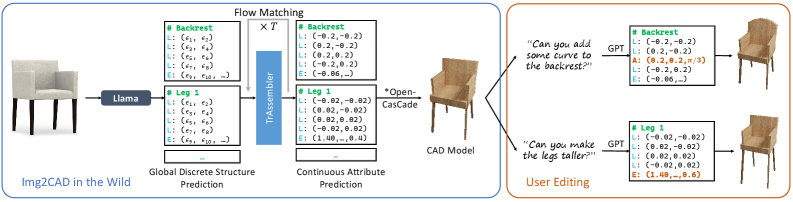
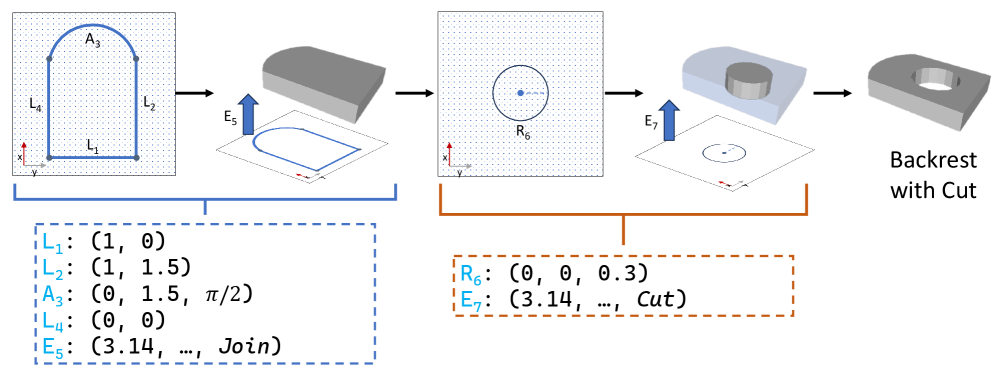
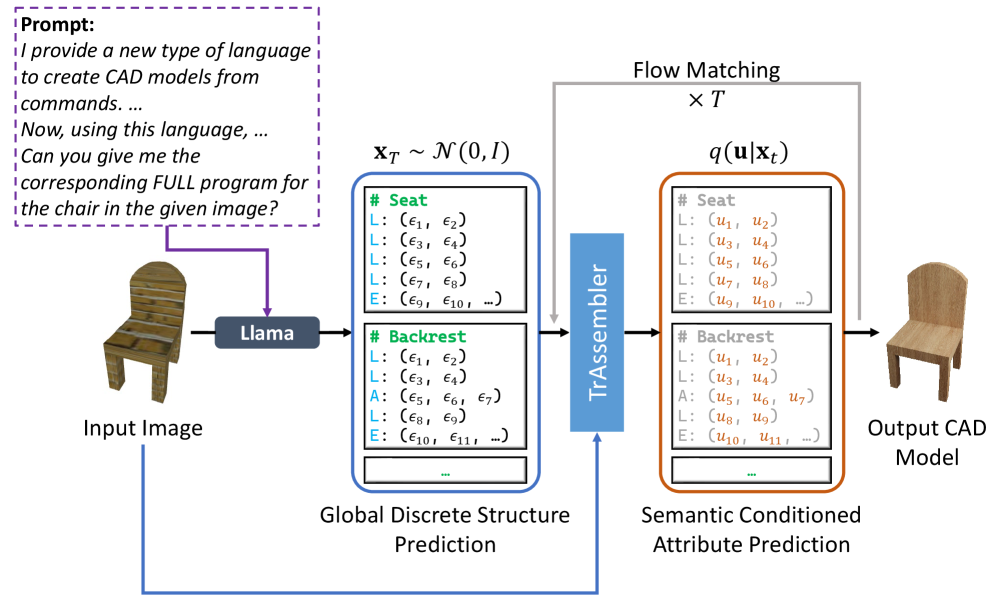
问题定义:论文旨在解决从单张图像中逆向工程出3D CAD模型的问题。现有方法难以处理CAD模型固有的复杂性(离散命令结构与连续属性的结合),以及图像输入带来的光度变化和噪声干扰,导致端到端学习和优化困难。
核心思路:论文的核心思路是将复杂的逆向工程任务分解为两个更易于处理的子问题:首先预测CAD模型的离散结构(例如,基本几何体的类型和连接关系),然后预测这些几何体的连续属性(例如,尺寸、位置和方向)。这种条件分解简化了学习过程,并允许利用不同的模型来处理不同类型的表示。
技术框架:整体框架包含两个主要模块:1) 基于视觉-语言模型(VLM)的离散结构预测模块,该模块以图像作为输入,预测CAD模型的全局离散基础结构,并赋予语义信息。2) TrAssembler模块,该模块以预测的离散结构和语义信息为条件,预测CAD模型的连续属性值。TrAssembler的训练依赖于一个新构建的带注释的CAD数据集。
关键创新:论文的关键创新在于有条件地分解了图像到CAD模型的逆向工程任务,并利用视觉-语言模型来预测CAD模型的离散结构。这种分解使得可以分别处理离散和连续的表示,从而简化了学习过程。此外,使用VLM赋予离散结构语义信息,有助于提高连续属性预测的准确性。
关键设计:论文使用微调的Llama3.2作为视觉-语言模型,用于预测离散结构。TrAssembler的具体网络结构未知(论文中未详细描述)。论文构建了一个新的CAD数据集,用于训练TrAssembler。损失函数和具体的参数设置在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文构建了一个新的带注释的CAD数据集,并提出了TrAssembler模型。虽然论文中没有给出具体的性能数据和对比基线,但作者声称该方法和数据证明了在CAD化真实图像方面迈出了重要的第一步。具体的性能提升幅度未知。
🎯 应用场景
该研究成果可应用于交互式编辑、制造、建筑、机器人等领域。例如,用户可以通过拍摄一张物体照片,快速生成其对应的3D CAD模型,从而方便进行设计、制造和仿真。该技术还有助于机器人理解和操作真实世界中的物体,以及在建筑设计中快速创建和修改3D模型。
📄 摘要(原文)
Reverse engineering 3D computer-aided design (CAD) models from images is an important task for many downstream applications including interactive editing, manufacturing, architecture, robotics, etc. The difficulty of the task lies in vast representational disparities between the CAD output and the image input. CAD models are precise, programmatic constructs that involve sequential operations combining discrete command structure with continuous attributes, making it challenging to learn and optimize in an end-to-end fashion. Concurrently, input images introduce inherent challenges such as photometric variability and sensor noise, complicating the reverse engineering process. In this work, we introduce a novel approach that conditionally factorizes the task into two sub-problems. First, we leverage vision-language foundation models (VLMs), a finetuned Llama3.2, to predict the global discrete base structure with semantic information. Second, we propose TrAssembler that, conditioned on the discrete structure with semantics, predicts the continuous attribute values. To support the training of our TrAssembler, we further constructed an annotated CAD dataset of common objects from ShapeNet. Putting all together, our approach and data demonstrate significant first steps towards CAD-ifying images in the wild. Code and data can be found in https://github.com/qq456cvb/Img2CAD.