On Pre-training of Multimodal Language Models Customized for Chart Understanding
作者: Wan-Cyuan Fan, Yen-Chun Chen, Mengchen Liu, Lu Yuan, Leonid Sigal
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-07-19 (更新: 2025-07-17)
备注: NeurIPS 2024 Workshop on Adaptive Foundation Models
💡 一句话要点
提出CHOPINLLM,定制多模态大语言模型以提升图表理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 图表理解 预训练 微调 视觉指令调整 数值提取 数据可视化
📋 核心要点
- 现有MLLM在图表理解方面表现不足,主要原因是自然图像预训练数据与图表数据的差异,尤其在数值提取能力上。
- 论文核心思想是通过改进预训练和微调策略,使MLLM更好地理解和解释图表,包括数值提取和推理。
- 论文提出了CHOPINLLM,并在新基准上验证了其在带注释和未注释图表理解方面的优越性能,提升了图表理解的准确性。
📝 摘要(中文)
最近的研究表明,为特定领域定制多模态大语言模型(MLLM)已取得可喜的成果,尤其是在科学图表理解领域。这些研究通常利用带有专门数据集的视觉指令调整来提高图表领域的问答(QA)准确性。然而,它们常常忽略了自然图像-标题预训练数据与数字图表图像-QA数据之间的根本差异,特别是在模型从图表中提取底层数值的能力方面。本文通过探索改进MLLM图表理解能力所需的训练过程来解决这一疏忽。我们提出了三个关键发现:(1)在对齐预训练中加入原始数据值可以显著提高对图表数据的理解。(2)在端到端微调期间,随机用文本表示替换图像,可以将语言推理能力转移到图表解释技能。(3)要求模型首先提取底层图表数据,然后在微调中回答问题,可以进一步提高准确性。因此,我们推出了CHOPINLLM,这是一种为深入图表理解而定制的MLLM。CHOPINLLM有效地解释各种类型的图表,包括未注释的图表,同时保持强大的推理能力。此外,我们建立了一个新的基准来评估MLLM对各种理解水平的不同图表类型的理解。实验结果表明,CHOPINLLM在理解各种类型的带注释和未注释图表方面表现出强大的性能。
🔬 方法详解
问题定义:现有MLLM在图表理解任务中,特别是从图表中提取数值信息方面存在不足。这是因为它们通常在自然图像和文本数据上进行预训练,而这些数据与图表数据的特性存在显著差异。现有方法忽略了这种差异,导致模型难以准确理解和推理图表信息。
核心思路:论文的核心思路是通过定制化的预训练和微调策略,弥合自然图像数据和图表数据之间的差距。具体来说,通过在预训练阶段引入原始数据值,并结合文本替换图像的微调方法,使模型能够更好地理解图表的数值信息和结构。
技术框架:CHOPINLLM的训练框架主要包含两个阶段:对齐预训练和端到端微调。在对齐预训练阶段,模型学习将图像特征与文本描述对齐,特别强调对图表数值信息的理解。在端到端微调阶段,采用文本替换图像的策略,并要求模型先提取图表数据再回答问题,进一步提升模型的图表理解能力。
关键创新:论文的关键创新在于提出了针对图表理解的定制化预训练和微调策略。具体包括:1) 在预训练阶段引入原始数据值,增强模型对数值信息的感知;2) 在微调阶段采用文本替换图像的策略,将语言推理能力迁移到图表解释;3) 提出先提取图表数据再回答问题的微调方式,提升准确性。
关键设计:在预训练阶段,将原始数据值与图表图像和文本描述一起输入模型,通过对比学习或其他损失函数,使模型学习到数值信息与图像特征之间的对应关系。在微调阶段,随机将图像替换为文本描述,迫使模型更多地依赖文本信息进行推理。此外,设计了一个两阶段的微调过程,首先要求模型提取图表数据,然后基于提取的数据回答问题。
🖼️ 关键图片
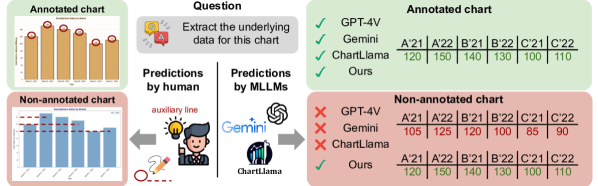


📊 实验亮点
CHOPINLLM在新的图表理解基准测试中表现出色,能够有效理解各种类型的带注释和未注释图表。实验结果表明,通过引入原始数据值进行预训练,并结合文本替换图像的微调策略,可以显著提升MLLM在图表理解任务中的性能。具体提升幅度未知,但论文强调了其在多种图表类型上的泛化能力。
🎯 应用场景
该研究成果可广泛应用于数据分析、商业智能、科学研究等领域。通过提升机器对图表的理解能力,可以自动化地从大量图表中提取信息,辅助决策,加速知识发现。未来,该技术有望应用于智能报表生成、数据可视化分析等场景。
📄 摘要(原文)
Recent studies customizing Multimodal Large Language Models (MLLMs) for domain-specific tasks have yielded promising results, especially in the field of scientific chart comprehension. These studies generally utilize visual instruction tuning with specialized datasets to enhance question and answer (QA) accuracy within the chart domain. However, they often neglect the fundamental discrepancy between natural image-caption pre-training data and digital chart image-QA data, particularly in the models' capacity to extract underlying numeric values from charts. This paper tackles this oversight by exploring the training processes necessary to improve MLLMs' comprehension of charts. We present three key findings: (1) Incorporating raw data values in alignment pre-training markedly improves comprehension of chart data. (2) Replacing images with their textual representation randomly during end-to-end fine-tuning transfer the language reasoning capability to chart interpretation skills. (3) Requiring the model to first extract the underlying chart data and then answer the question in the fine-tuning can further improve the accuracy. Consequently, we introduce CHOPINLLM, an MLLM tailored for in-depth chart comprehension. CHOPINLLM effectively interprets various types of charts, including unannotated ones, while maintaining robust reasoning abilities. Furthermore, we establish a new benchmark to evaluate MLLMs' understanding of different chart types across various comprehension levels. Experimental results show that CHOPINLLM exhibits strong performance in understanding both annotated and unannotated charts across a wide range of types.