PD-APE: A Parallel Decoding Framework with Adaptive Position Encoding for 3D Visual Grounding
作者: Chenshu Hou, Liang Peng, Xiaopei Wu, Xiaofei He, Wenxiao Wang
分类: cs.CV
发布日期: 2024-07-19 (更新: 2024-09-02)
💡 一句话要点
PD-APE:一种用于3D视觉定位的自适应位置编码并行解码框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 点云 自然语言处理 双分支解码 自适应位置编码 Transformer 多模态融合
📋 核心要点
- 现有3D视觉定位方法难以兼顾目标对象属性和周围环境布局,容易造成注意力分散。
- PD-APE采用双分支解码结构,分别处理目标对象和周围环境信息,实现更精准的定位。
- 实验结果表明,PD-APE在ScanRefer和Nr3D数据集上均超越了现有最佳方法。
📝 摘要(中文)
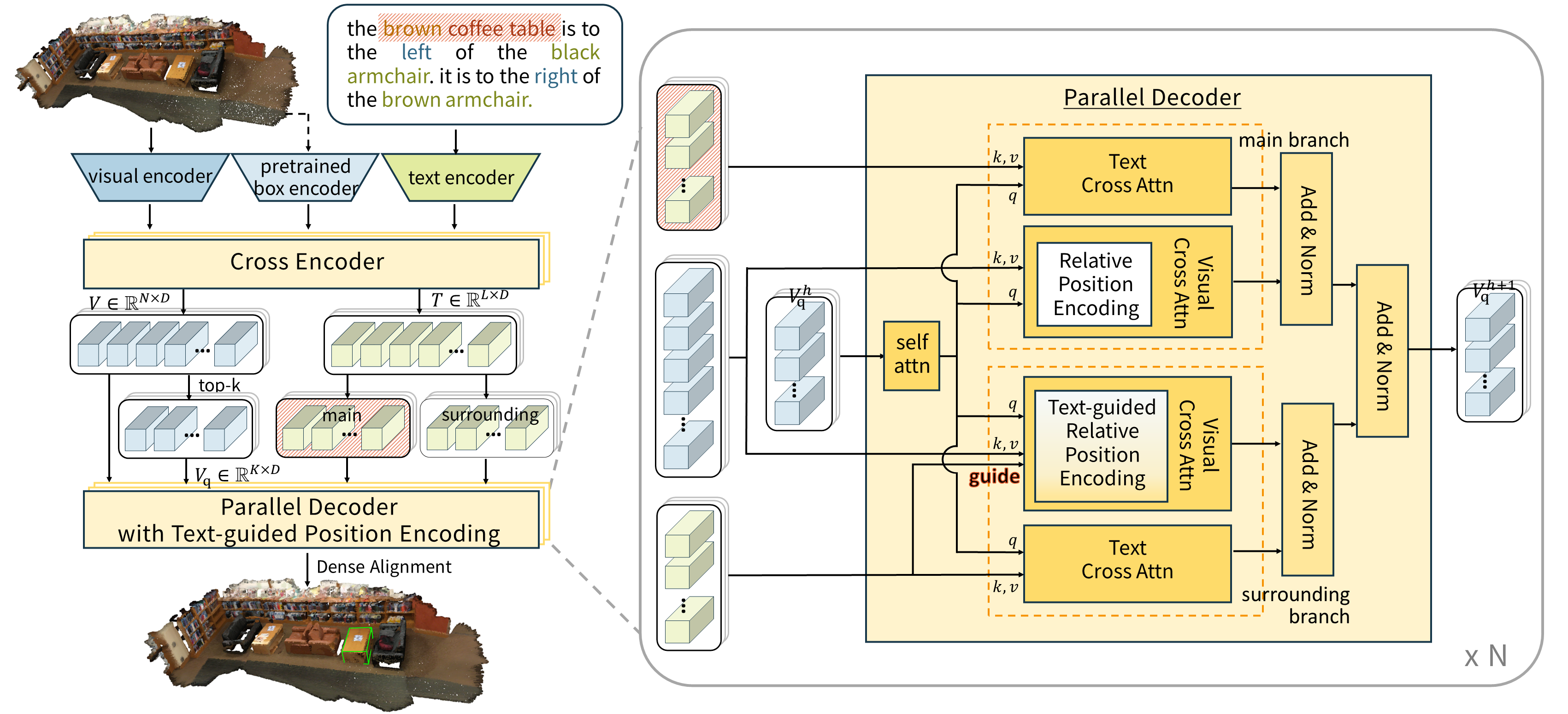
本文提出了一种用于3D视觉定位的并行解码框架PD-APE,旨在解决现有方法在同时处理目标对象属性和周围环境布局时容易分散注意力的问题。PD-APE采用双分支解码结构,分别解码目标对象属性和周围环境布局。目标对象分支处理描述目标对象特征的文本token,引导查询关注目标对象本身;周围环境分支则与携带周围环境信息的文本token对齐,使注意力图准确捕捉文本描述的布局。此外,针对每个分支分别设计了自适应位置编码方法。在目标对象分支中,位置编码依赖于种子点和预测3D框之间的相对位置;在周围环境分支中,注意力图还受到视觉和文本特征之间置信度的引导,使查询能够关注具有有价值布局信息的点。在ScanRefer和Nr3D两个数据集上的大量实验表明,该方法超越了现有技术水平。
🔬 方法详解
问题定义:3D视觉定位旨在识别点云场景中与自然语言描述相匹配的对象。现有方法通常在一个模块中同时处理目标对象属性和周围环境布局,容易导致注意力分散,影响定位精度。
核心思路:PD-APE的核心思路是采用双分支解码结构,将目标对象属性和周围环境布局的解码过程分离。通过这种方式,每个分支可以专注于其特定的目标,避免注意力分散,从而提高定位精度。
技术框架:PD-APE框架包含两个主要分支:目标对象分支和周围环境分支。目标对象分支接收描述目标对象特征的文本token,并引导查询关注目标对象本身。周围环境分支接收携带周围环境信息的文本token,并使注意力图准确捕捉文本描述的布局。每个分支都使用自适应位置编码方法来增强特征表示。
关键创新:PD-APE的关键创新在于双分支解码结构和自适应位置编码方法。双分支结构允许模型分别处理目标对象和周围环境信息,避免注意力分散。自适应位置编码方法则根据不同分支的特点,动态调整位置编码方式,提高特征表示的有效性。
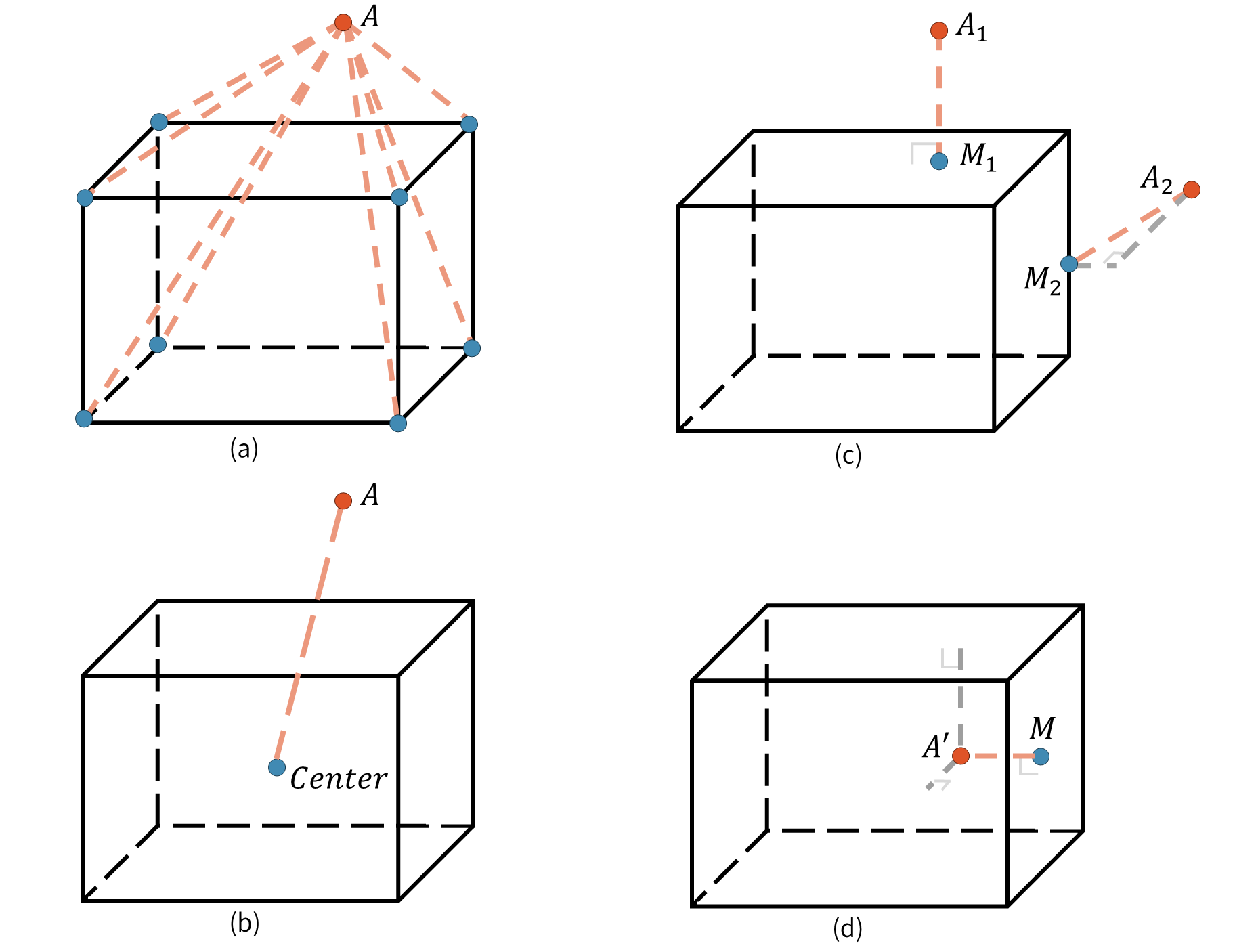
关键设计:在目标对象分支中,位置编码依赖于种子点和预测3D框之间的相对位置。在周围环境分支中,注意力图还受到视觉和文本特征之间置信度的引导。损失函数的设计也考虑了两个分支的特点,分别优化目标对象属性和周围环境布局的预测。
🖼️ 关键图片
📊 实验亮点
PD-APE在ScanRefer和Nr3D两个广泛使用的3D视觉定位数据集上取得了显著的性能提升。具体而言,PD-APE在两个数据集上均超越了现有最佳方法,证明了其有效性。实验结果表明,双分支解码结构和自适应位置编码方法能够有效提高3D视觉定位的精度。
🎯 应用场景
PD-APE在机器人导航、自动驾驶、虚拟现实等领域具有广泛的应用前景。例如,在机器人导航中,PD-APE可以帮助机器人理解人类指令,准确识别目标对象并规划行动路径。在自动驾驶中,PD-APE可以用于识别交通标志、行人等,提高驾驶安全性。在虚拟现实中,PD-APE可以增强用户与虚拟环境的交互体验。
📄 摘要(原文)
3D visual grounding aims to identify objects in 3D point cloud scenes that match specific natural language descriptions. This requires the model to not only focus on the target object itself but also to consider the surrounding environment to determine whether the descriptions are met. Most previous works attempt to accomplish both tasks within the same module, which can easily lead to a distraction of attention. To this end, we propose PD-APE, a dual-branch decoding framework that separately decodes target object attributes and surrounding layouts. Specifically, in the target object branch, the decoder processes text tokens that describe features of the target object (e.g., category and color), guiding the queries to pay attention to the target object itself. In the surrounding branch, the queries align with other text tokens that carry surrounding environment information, making the attention maps accurately capture the layout described in the text. Benefiting from the proposed dual-branch design, the queries are allowed to focus on points relevant to each branch's specific objective. Moreover, we design an adaptive position encoding method for each branch respectively. In the target object branch, the position encoding relies on the relative positions between seed points and predicted 3D boxes. In the surrounding branch, the attention map is additionally guided by the confidence between visual and text features, enabling the queries to focus on points that have valuable layout information. Extensive experiments demonstrate that we surpass the state-of-the-art on two widely adopted 3D visual grounding datasets, ScanRefer and Nr3D.