Visual Text Generation in the Wild
作者: Yuanzhi Zhu, Jiawei Liu, Feiyu Gao, Wenyu Liu, Xinggang Wang, Peng Wang, Fei Huang, Cong Yao, Zhibo Yang
分类: cs.CV
发布日期: 2024-07-19 (更新: 2024-11-03)
备注: Accepted to ECCV 2024
💡 一句话要点
提出SceneVTG,一种在复杂场景下生成高质量、实用文本图像的视觉文本生成器。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉文本生成 多模态大语言模型 条件扩散模型 场景理解 文本检测 文本识别 图像生成
📋 核心要点
- 现有视觉文本生成方法难以兼顾保真度、合理性和实用性,限制了其在真实场景中的应用。
- SceneVTG利用多模态大语言模型推荐文本区域和内容,并结合条件扩散模型生成高质量文本图像。
- 实验表明,SceneVTG在保真度和合理性方面优于现有方法,并提升了文本检测和识别任务的性能。
📝 摘要(中文)
近年来,生成模型发展迅速,视觉文本生成领域也取得了显著进展。然而,在真实场景中生成高质量的文本图像仍然具有挑战性,需要满足三个关键标准:(1) 保真度:生成的文本图像应具有照片级的真实感,并且内容应与给定条件一致;(2) 合理性:生成的文本区域和内容应与场景相符;(3) 实用性:生成的文本图像应有助于相关任务(例如,文本检测和识别)。通过研究发现,现有的基于渲染或基于扩散的方法难以同时满足所有这些方面,限制了其应用范围。因此,本文提出了一种视觉文本生成器(SceneVTG),可以在复杂场景中生成高质量的文本图像。SceneVTG采用两阶段范式,利用多模态大型语言模型来推荐多个尺度和级别的合理文本区域和内容,并将其作为条件扩散模型的条件来生成文本图像。大量实验表明,所提出的SceneVTG在保真度和合理性方面显著优于传统的基于渲染的方法和最新的基于扩散的方法。此外,生成的图像为涉及文本检测和文本识别的任务提供了卓越的实用性。
🔬 方法详解
问题定义:论文旨在解决在复杂场景下生成高质量、合理且实用的文本图像的问题。现有方法,无论是基于渲染的还是基于扩散的,都难以同时满足保真度(图像真实感)、合理性(文本与场景一致性)和实用性(辅助下游任务)这三个关键标准。例如,基于渲染的方法可能难以生成逼真的光照和阴影效果,而基于扩散的方法可能无法保证生成文本的合理性和与场景的协调性。
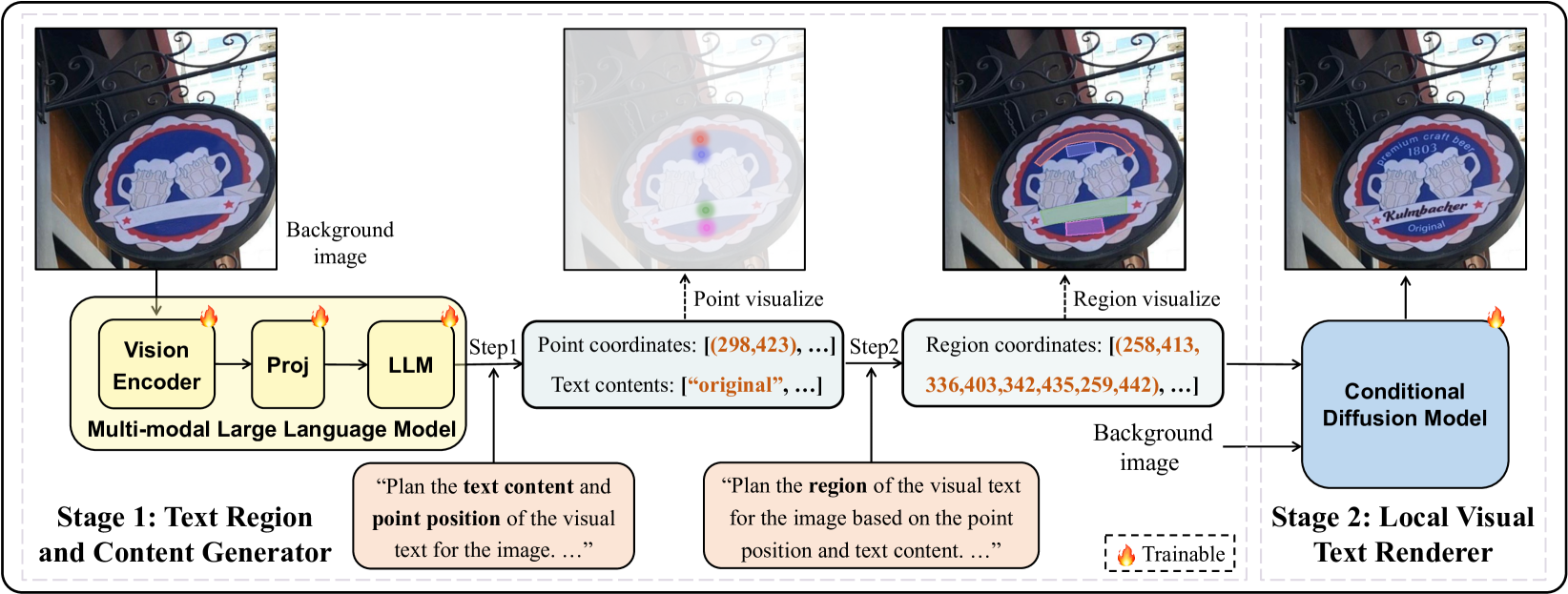
核心思路:论文的核心思路是利用多模态大型语言模型(Multimodal Large Language Model, MLLM)的强大推理能力,为条件扩散模型提供更合理、更符合场景的文本区域和内容建议。通过MLLM,模型可以更好地理解场景上下文,从而生成更逼真、更合理的文本图像。这种两阶段的方法将文本生成任务分解为文本区域/内容推荐和图像生成两个子任务,从而降低了生成难度。
技术框架:SceneVTG采用两阶段的生成框架。第一阶段是文本区域和内容推荐阶段,使用多模态大型语言模型(MLLM)根据输入场景图像,推荐多个尺度和级别的合理文本区域和内容。第二阶段是图像生成阶段,使用条件扩散模型,以场景图像和MLLM推荐的文本区域/内容作为条件,生成最终的文本图像。
关键创新:论文的关键创新在于将多模态大型语言模型引入到视觉文本生成任务中,利用其强大的上下文理解和推理能力,为扩散模型提供更合理的文本区域和内容建议。这与以往的方法不同,以往的方法通常直接使用场景图像作为条件,或者使用简单的文本描述作为条件,而忽略了场景的复杂性和文本与场景的关联性。
关键设计:论文中关于MLLM的具体选择、prompt设计以及扩散模型的条件输入方式等细节未知。损失函数和网络结构等技术细节也未在摘要中提及,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SceneVTG在保真度和合理性方面显著优于传统的基于渲染的方法和最新的基于扩散的方法。此外,使用SceneVTG生成的图像能够显著提升文本检测和文本识别任务的性能,表明其具有很高的实用价值。具体的性能数据和提升幅度需要在论文全文中查找。
🎯 应用场景
SceneVTG在多个领域具有广泛的应用前景,例如自动驾驶(生成路标和交通标志)、增强现实(在真实场景中添加虚拟文本)、广告设计(生成具有特定文本的广告图像)以及文档修复(恢复破损文档中的文本)。该研究能够提升相关任务的性能,并为视觉内容创作提供新的可能性。
📄 摘要(原文)
Recently, with the rapid advancements of generative models, the field of visual text generation has witnessed significant progress. However, it is still challenging to render high-quality text images in real-world scenarios, as three critical criteria should be satisfied: (1) Fidelity: the generated text images should be photo-realistic and the contents are expected to be the same as specified in the given conditions; (2) Reasonability: the regions and contents of the generated text should cohere with the scene; (3) Utility: the generated text images can facilitate related tasks (e.g., text detection and recognition). Upon investigation, we find that existing methods, either rendering-based or diffusion-based, can hardly meet all these aspects simultaneously, limiting their application range. Therefore, we propose in this paper a visual text generator (termed SceneVTG), which can produce high-quality text images in the wild. Following a two-stage paradigm, SceneVTG leverages a Multimodal Large Language Model to recommend reasonable text regions and contents across multiple scales and levels, which are used by a conditional diffusion model as conditions to generate text images. Extensive experiments demonstrate that the proposed SceneVTG significantly outperforms traditional rendering-based methods and recent diffusion-based methods in terms of fidelity and reasonability. Besides, the generated images provide superior utility for tasks involving text detection and text recognition. Code and datasets are available at AdvancedLiterateMachinery.