Bidirectional Regression for Monocular 6DoF Head Pose Estimation and Reference System Alignment
作者: Sungho Chun, Boeun Kim, Hyung Jin Chang, Ju Yong Chang
分类: cs.CV
发布日期: 2024-07-19 (更新: 2025-10-31)
备注: This version extends the previously published preprint and has been submitted to Pattern Recognition
💡 一句话要点
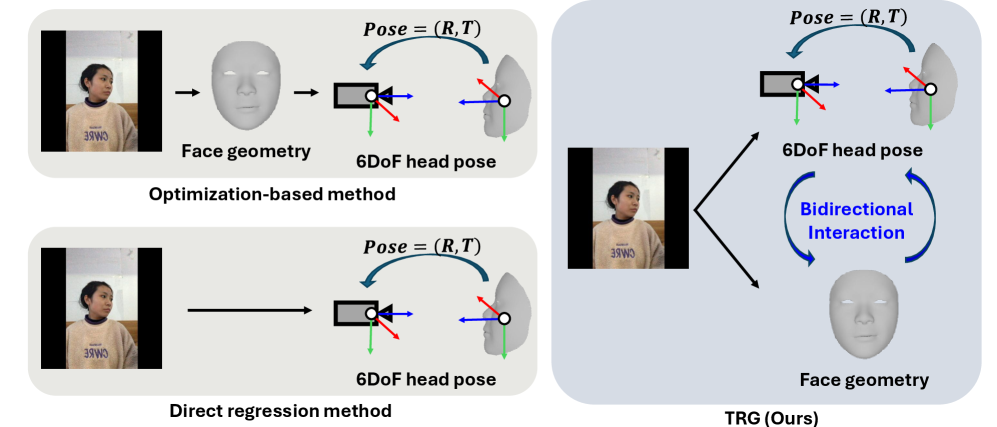
提出TRGv2网络,通过双向回归和参考系对齐提升单目6DoF头部姿态估计精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 头部姿态估计 6DoF姿态估计 单目视觉 人机交互 面部landmarks 深度估计 参考系对齐
📋 核心要点
- 现有单目6DoF头部姿态估计方法在鲁棒性方面存在不足,难以满足安全关键应用的需求。
- TRGv2通过显式建模面部几何与头部姿态的双向交互,并采用迭代细化循环来提升估计精度。
- 实验表明,TRGv2在多个数据集上超越了现有方法,并在准确性和效率上均有提升。
📝 摘要(中文)
精确的六自由度(6DoF)头部姿态估计对于安全关键应用和人机交互场景至关重要,但现有的单目方法在鲁棒的姿态估计方面仍然面临挑战。我们通过引入TRGv2来重新审视这个问题,TRGv2是我们之前的Translation, Rotation, and Geometry (TRG)网络的轻量级扩展,它显式地建模了面部几何和头部姿态之间的双向交互。TRGv2通过带有landmark-to-image投影的迭代细化循环联合推断面部landmarks和6DoF姿态,确保面部大小、旋转和深度之间的度量一致性。为了进一步提高对分布外数据的泛化能力,TRGv2回归校正参数而不是直接预测平移,并将它们与针孔相机模型结合用于解析深度估计。此外,我们发现由于不同数据集中头部中心定义不一致,导致了先前被忽视的跨数据集评估中的偏差来源。为了解决这个问题,我们提出了一种参考系对齐策略,该策略量化并校正平移偏差,从而实现跨数据集的公平比较。在ARKitFace、BIWI和具有挑战性的DD-Pose基准上的大量实验表明,TRGv2在准确性和效率方面均优于最先进的方法。代码和新注释的DD-Pose landmarks将公开提供。
🔬 方法详解
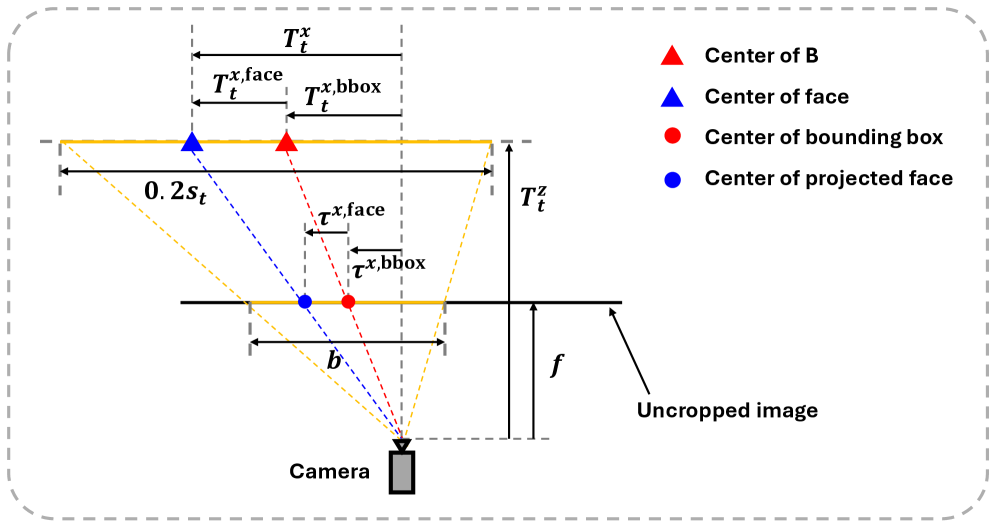
问题定义:论文旨在解决单目图像的精确6DoF头部姿态估计问题。现有方法,尤其是在跨数据集评估时,存在鲁棒性不足和数据集偏差的问题,导致泛化能力受限。此外,不同数据集对头部中心的定义不一致,进一步加剧了评估偏差。
核心思路:论文的核心思路是利用面部几何信息与头部姿态之间的双向关系,通过迭代优化来提升姿态估计的精度和鲁棒性。同时,通过回归校正参数而非直接预测平移,并结合针孔相机模型进行深度估计,增强模型的泛化能力。此外,引入参考系对齐策略,消除跨数据集评估中的偏差。
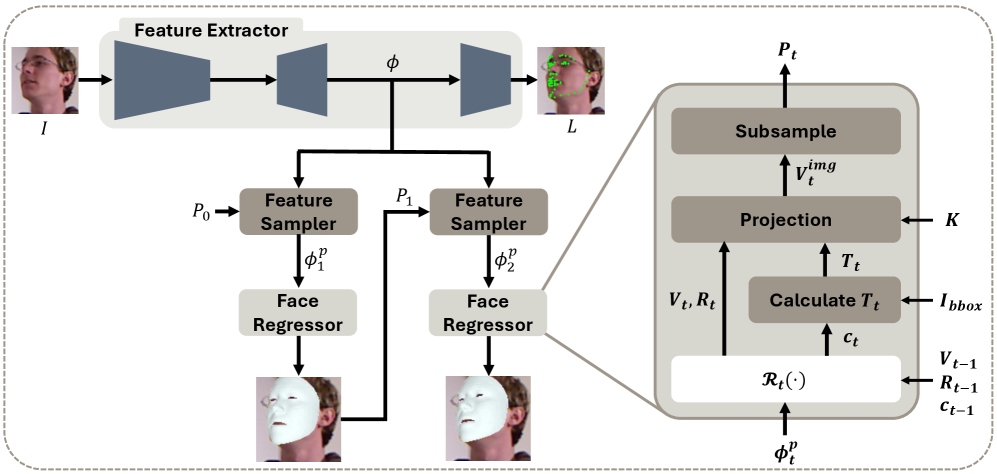
技术框架:TRGv2网络是整体框架的核心。它包含以下主要模块:1) 面部landmarks检测模块;2) 6DoF姿态估计模块;3) landmark-to-image投影模块,用于实现landmark和姿态之间的迭代优化;4) 参考系对齐模块,用于校正跨数据集的平移偏差。整个流程通过迭代细化循环,不断优化landmarks和姿态估计结果。
关键创新:论文的关键创新点包括:1) 显式建模面部几何与头部姿态的双向交互,实现更精确的姿态估计;2) 采用回归校正参数的方式进行深度估计,提高模型的泛化能力;3) 提出参考系对齐策略,有效消除跨数据集评估中的偏差。
关键设计:TRGv2网络是TRG网络的扩展,采用了轻量级设计以提高效率。损失函数的设计考虑了landmarks和姿态估计的精度,以及landmark-to-image投影的误差。迭代细化循环的迭代次数是一个关键参数,需要在精度和效率之间进行权衡。参考系对齐策略通过计算不同数据集头部中心之间的平移向量来实现。
🖼️ 关键图片
📊 实验亮点
TRGv2在ARKitFace、BIWI和DD-Pose等多个数据集上进行了评估,实验结果表明,TRGv2在准确性和效率方面均优于现有最先进的方法。特别是在具有挑战性的DD-Pose数据集上,TRGv2取得了显著的性能提升,验证了其在复杂场景下的鲁棒性。
🎯 应用场景
该研究成果可应用于人机交互、虚拟现实/增强现实、驾驶员疲劳检测、安全监控等领域。精确的头部姿态估计能够提升用户体验,改善系统性能,并为相关应用提供更可靠的数据支持。未来,该技术有望在智能座舱、远程医疗、教育等领域发挥重要作用。
📄 摘要(原文)
Precise six-degree-of-freedom (6DoF) head pose estimation is crucial for safety-critical applications and human-computer interaction scenarios, yet existing monocular methods still struggle with robust pose estimation. We revisit this problem by introducing TRGv2, a lightweight extension of our previous Translation, Rotation, and Geometry (TRG) network, which explicitly models the bidirectional interaction between facial geometry and head pose. TRGv2 jointly infers facial landmarks and 6DoF pose through an iterative refinement loop with landmark-to-image projection, ensuring metric consistency among face size, rotation, and depth. To further improve generalization to out-of-distribution data, TRGv2 regresses correction parameters instead of directly predicting translation, combining them with a pinhole camera model for analytic depth estimation. In addition, we identify a previously overlooked source of bias in cross-dataset evaluations due to inconsistent head center definitions across different datasets. To address this, we propose a reference system alignment strategy that quantifies and corrects translation bias, enabling fair comparisons across datasets. Extensive experiments on ARKitFace, BIWI, and the challenging DD-Pose benchmarks demonstrate that TRGv2 outperforms state-of-the-art methods in both accuracy and efficiency. Code and newly annotated landmarks for DD-Pose will be publicly available.