Decomposed Vector-Quantized Variational Autoencoder for Human Grasp Generation
作者: Zhe Zhao, Mengshi Qi, Huadong Ma
分类: cs.CV
发布日期: 2024-07-19
备注: To be published in The 18th European Conference on Computer Vision ECCV 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出分解向量量化变分自编码器以解决人类抓取生成问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion)
关键词: 人类抓取 变分自编码器 向量量化 机器人技术 计算机图形学 物体交互 深度学习
📋 核心要点
- 现有方法在生成细致逼真的人类抓取时存在局限,难以确保所有手指有效与物体交互。
- 本文提出DVQ-VAE,通过将手分解为多个部分进行独立编码,改善手与物体的交互管理。
- 实验结果显示,模型在四个基准测试中相较于现有方法提升了约14.1%的质量指数。
📝 摘要(中文)
生成逼真的人类抓取是计算机图形学和机器人领域中涉及物体操作的重要且具有挑战性的任务。现有方法往往难以生成细致的、逼真的人类抓取,因其通常将手的整体表示进行编码,并在单一步骤中估计手的姿态和位置。本文提出了一种新颖的分解向量量化变分自编码器(DVQ-VAE),通过将手分解为多个独立部分并分别编码,来解决这一局限性。这种部分感知的分解架构有助于更精确地管理手与物体之间每个组件的交互,增强生成的人类抓取的整体真实感。此外,我们设计了一种新的双阶段解码策略,首先在骨骼物理约束下确定抓取类型,然后识别抓取位置,从而大大提高模型对未见手-物体交互的逼真性和适应性。在实验中,我们的模型在四个广泛采用的基准测试中,相较于最先进的方法实现了约14.1%的质量指数相对提升。
🔬 方法详解
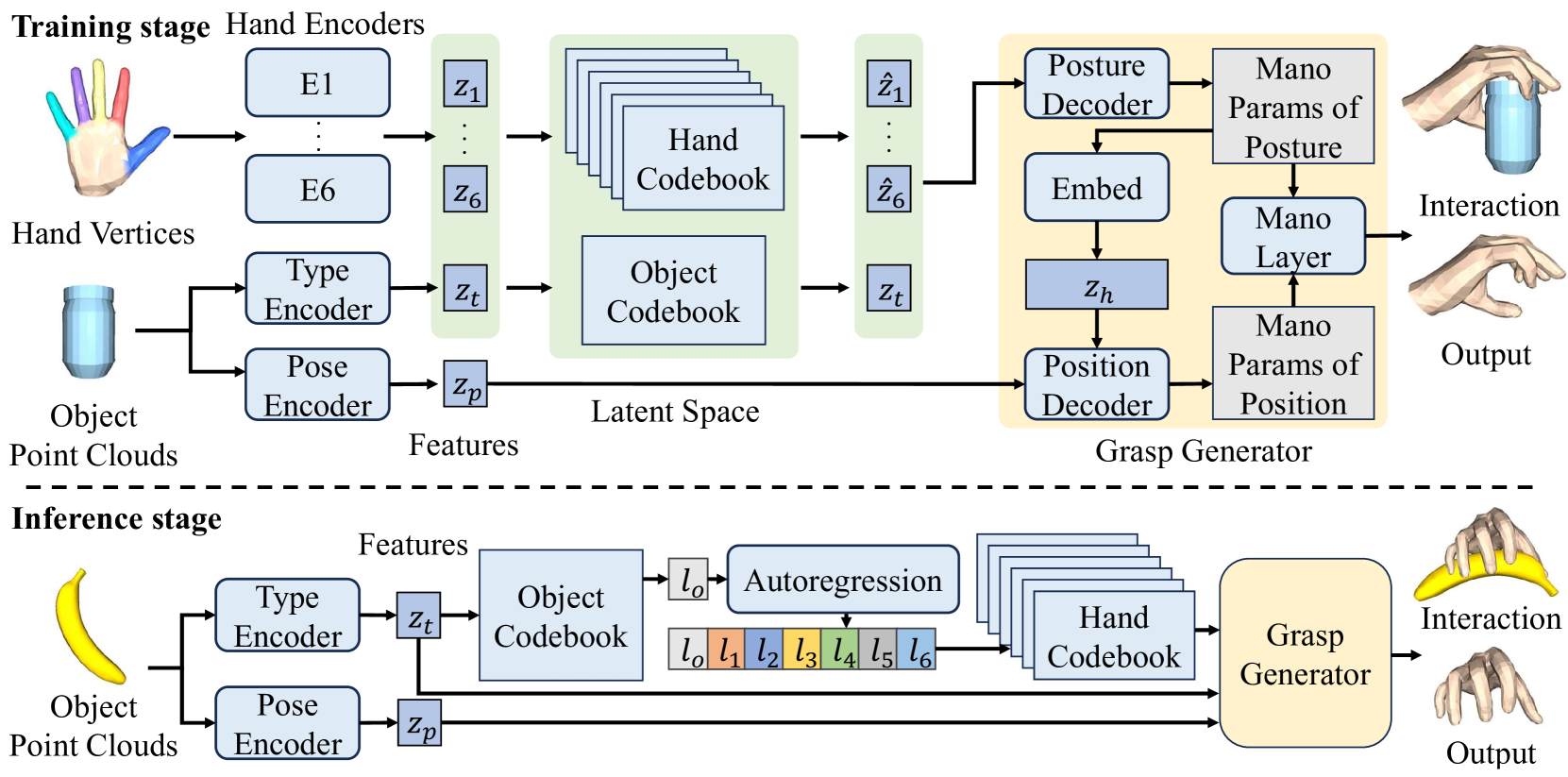
问题定义:本文旨在解决生成逼真的人类抓取的挑战,现有方法往往无法有效处理手指与物体的细致交互,导致抓取效果不理想。
核心思路:提出的DVQ-VAE通过将手分解为多个独立部分进行编码,允许更精确地管理手的各个组件与物体的交互,从而提高抓取的真实感。
技术框架:该方法的整体架构包括两个主要阶段:首先是对手的各个部分进行独立编码,接着是双阶段解码策略,首先确定抓取类型,然后识别抓取位置。
关键创新:最重要的创新在于部分感知的分解架构和双阶段解码策略,这与现有方法的整体编码-解码流程形成鲜明对比,显著提升了模型的适应性和真实感。
关键设计:在模型设计中,采用了特定的损失函数以优化各部分的交互,同时在网络结构上进行了调整,以支持分解编码和双阶段解码的流程。具体的参数设置和网络架构细节在实验部分进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DVQ-VAE模型在四个广泛采用的基准测试中,相较于最先进的方法实现了约14.1%的质量指数相对提升,显示出其在生成逼真抓取方面的显著优势。
🎯 应用场景
该研究的潜在应用领域包括机器人抓取、虚拟现实中的手势交互以及计算机动画等。通过生成更真实的抓取动作,能够提升人机交互的自然性和流畅性,进而推动相关技术的发展与应用。
📄 摘要(原文)
Generating realistic human grasps is a crucial yet challenging task for applications involving object manipulation in computer graphics and robotics. Existing methods often struggle with generating fine-grained realistic human grasps that ensure all fingers effectively interact with objects, as they focus on encoding hand with the whole representation and then estimating both hand posture and position in a single step. In this paper, we propose a novel Decomposed Vector-Quantized Variational Autoencoder (DVQ-VAE) to address this limitation by decomposing hand into several distinct parts and encoding them separately. This part-aware decomposed architecture facilitates more precise management of the interaction between each component of hand and object, enhancing the overall reality of generated human grasps. Furthermore, we design a newly dual-stage decoding strategy, by first determining the type of grasping under skeletal physical constraints, and then identifying the location of the grasp, which can greatly improve the verisimilitude as well as adaptability of the model to unseen hand-object interaction. In experiments, our model achieved about 14.1% relative improvement in the quality index compared to the state-of-the-art methods in four widely-adopted benchmarks. Our source code is available at https://github.com/florasion/D-VQVAE.