Which objects help me to act effectively? Reasoning about physically-grounded affordances
作者: Anne Kemmeren, Gertjan Burghouts, Michael van Bekkum, Wouter Meijer, Jelle van Mil
分类: cs.CV, cs.RO
发布日期: 2024-07-18
备注: 10 pages
期刊: Robotics: Science and Systems. Semantic Reasoning and Goal Understanding in Robotics 2024
💡 一句话要点
提出基于LLM和VLM对话的具身可供性推理方法,提升机器人与环境交互的有效性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可供性推理 大型语言模型 视觉-语言模型 具身智能 机器人交互
📋 核心要点
- 现有方法在开放世界中进行可供性推理时,难以有效结合机器人自身特性和物体物理属性。
- 利用LLM和VLM的对话机制,根据动作和效果描述,在物理世界中寻找具有相应可供性的物体。
- 实验表明,该方法能根据机器人具身性和预期效果选择合适物体,微调VLM可进一步提升性能。
📝 摘要(中文)
为了与开放世界进行有效的交互,机器人应该理解与已知和新物体的交互如何帮助它们实现目标。这种理解的关键在于检测物体的可供性,即可供性代表通过各种方式操纵物体可以实现的潜在效果。本文提出了一种利用大型语言模型(LLM)和视觉-语言模型(VLM)对话的方法来实现开放世界的可供性检测。给定预期动作和效果的开放词汇描述,可以找到环境中有用的对象。通过将系统置于物理世界中,考虑了机器人的具身性和它遇到的物体的内在属性。实验表明,该方法能够根据不同的具身性或预期效果生成定制的输出,并能够从一组干扰物中选择有用的对象。对VLM进行物理属性的微调提高了整体性能。这些结果强调了将可供性搜索置于物理世界中的重要性,即考虑到机器人的具身性和物体的物理属性。
🔬 方法详解
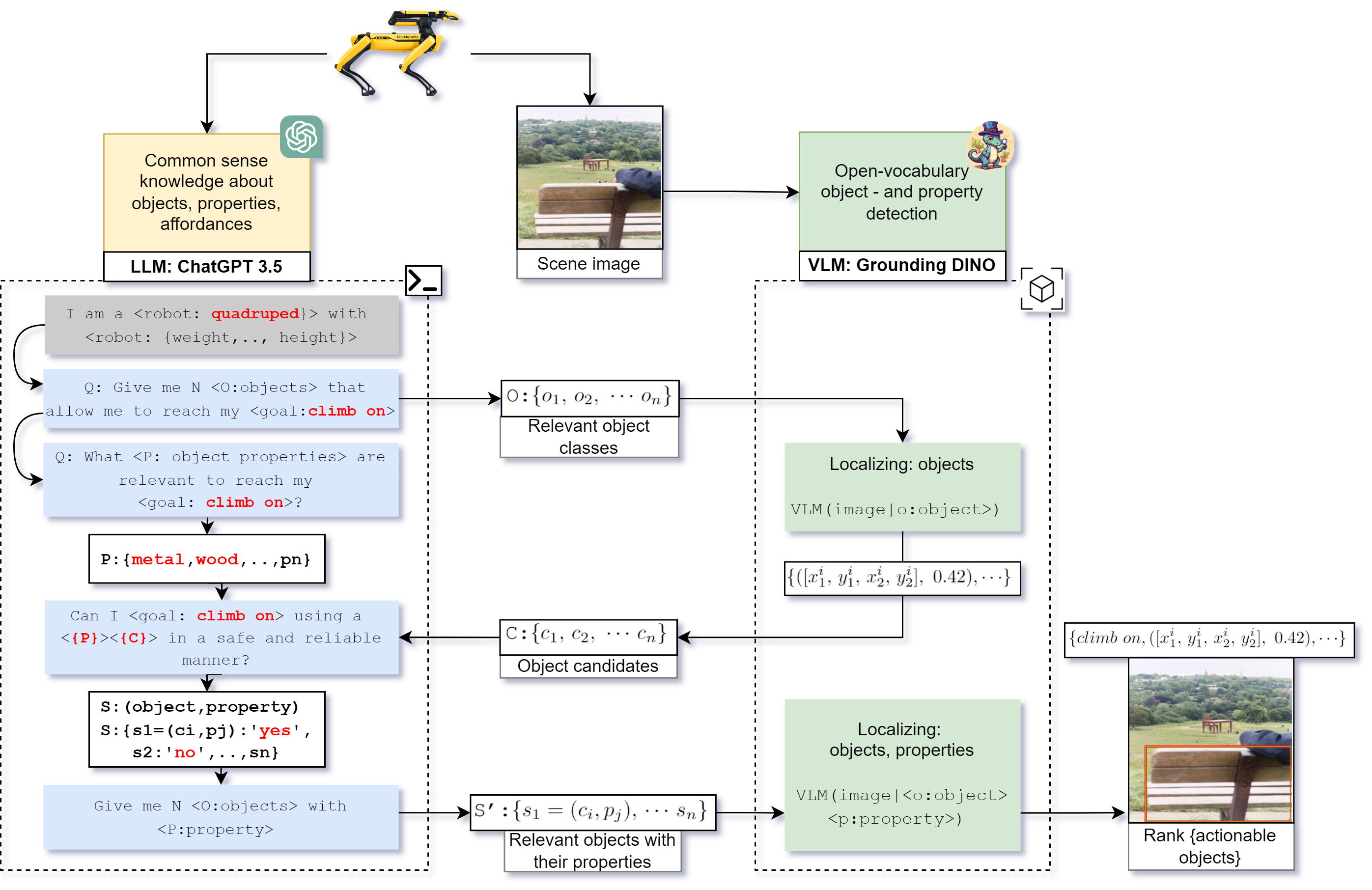
问题定义:论文旨在解决机器人如何在开放世界中,根据自身能力和任务目标,有效地识别和利用环境中物体的可供性。现有方法通常难以将机器人的具身性(embodiment)和物体的物理属性纳入考虑,导致推理结果不够准确或实用。
核心思路:论文的核心思路是利用大型语言模型(LLM)和视觉-语言模型(VLM)的强大能力,构建一个对话系统,通过自然语言描述任务目标和预期效果,并结合VLM对环境物体的视觉感知,推理出哪些物体具有满足任务需求的可供性。这种方法将可供性搜索置于物理世界中,考虑了机器人的具身性和物体的物理属性。
技术框架:该方法的技术框架主要包含以下几个阶段:1) 任务描述:使用自然语言描述机器人的任务目标和预期效果。2) LLM推理:LLM根据任务描述,生成关于所需物体属性和功能的假设。3) VLM视觉感知:VLM对环境中的物体进行视觉感知,提取物体的视觉特征和物理属性。4) 可供性评估:结合LLM的推理结果和VLM的视觉感知,评估环境中哪些物体具有满足任务需求的可供性。5) 物体选择:选择具有最高可供性评分的物体。
关键创新:该方法最重要的技术创新点在于将LLM和VLM结合起来,构建了一个对话式的可供性推理系统。与传统方法相比,该方法能够更好地理解任务目标,并结合视觉信息和物理属性进行推理,从而更准确地识别出具有所需可供性的物体。此外,通过对VLM进行物理属性的微调,可以进一步提高系统的性能。
关键设计:在VLM微调方面,论文可能使用了对比学习或回归学习等方法,以提高VLM对物体物理属性的感知能力。具体的损失函数和网络结构细节未知。LLM和VLM之间的交互方式也至关重要,可能采用了某种形式的注意力机制或知识融合技术,以实现信息的有效传递和整合。具体的参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法能够根据不同的机器人具身性和预期效果生成定制的输出,并能够从一组干扰物中选择有用的对象。对VLM进行物理属性的微调提高了整体性能,验证了将可供性搜索置于物理世界中的重要性。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于各种机器人应用场景,例如家庭服务机器人、工业机器人、搜索救援机器人等。通过理解物体的可供性,机器人可以更有效地完成各种任务,例如物体抓取、组装、清洁等。此外,该研究还可以促进人机交互的发展,使机器人能够更好地理解人类的意图,并提供更自然、更智能的服务。
📄 摘要(原文)
For effective interactions with the open world, robots should understand how interactions with known and novel objects help them towards their goal. A key aspect of this understanding lies in detecting an object's affordances, which represent the potential effects that can be achieved by manipulating the object in various ways. Our approach leverages a dialogue of large language models (LLMs) and vision-language models (VLMs) to achieve open-world affordance detection. Given open-vocabulary descriptions of intended actions and effects, the useful objects in the environment are found. By grounding our system in the physical world, we account for the robot's embodiment and the intrinsic properties of the objects it encounters. In our experiments, we have shown that our method produces tailored outputs based on different embodiments or intended effects. The method was able to select a useful object from a set of distractors. Finetuning the VLM for physical properties improved overall performance. These results underline the importance of grounding the affordance search in the physical world, by taking into account robot embodiment and the physical properties of objects.