Restore Anything Model via Efficient Degradation Adaptation
作者: Bin Ren, Eduard Zamfir, Zongwei Wu, Yawei Li, Yidi Li, Danda Pani Paudel, Radu Timofte, Ming-Hsuan Yang, Nicu Sebe
分类: cs.CV
发布日期: 2024-07-18 (更新: 2024-12-18)
备注: Efficient Any Image Restoration
💡 一句话要点
提出RAM:通过高效退化自适应实现通用图像修复,显著降低模型复杂度和计算量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像修复 退化自适应 联合嵌入 深度学习 计算机视觉
📋 核心要点
- 现有图像修复方法针对特定退化训练模型,效率低且冗余,或引入额外模块/跨模态迁移,增加模型复杂度。
- RAM利用不同退化间的相似性,通过联合嵌入和门控机制,实现高效且通用的图像修复,无需扩大模型。
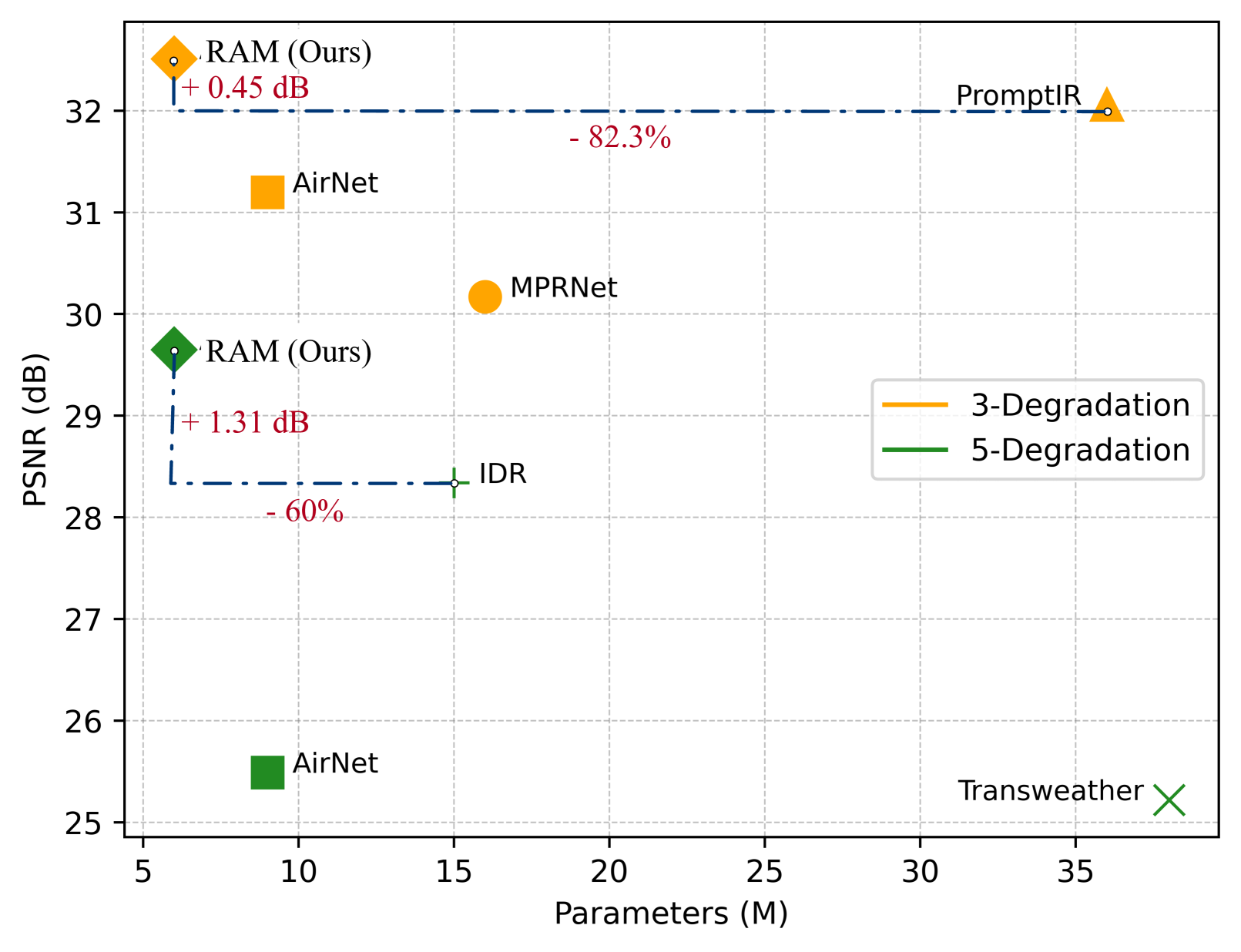
- 实验表明,RAM在通用图像修复任务上达到SOTA性能,同时显著降低了模型复杂度和计算量。
📝 摘要(中文)
随着移动设备的普及,对能够修复各种退化图像的高效模型的需求变得越来越重要。传统方法通常为每种特定退化训练专用模型,导致效率低下和冗余。最近的解决方案要么引入额外的模块来学习视觉提示,显著增加模型大小,要么结合来自在海量数据集上训练的大型语言模型的跨模态迁移,增加了系统架构的复杂性。相比之下,我们的方法(称为RAM)采用了一种统一的路径,利用各种退化之间的内在相似性,通过联合嵌入机制实现高效和全面的修复,而无需扩大模型或依赖大型多模态模型。具体来说,我们检查每个输入的子潜在空间,识别关键组件,并以门控方式重新加权。这种内在的退化感知与X形框架中的上下文注意力相结合,增强了局部-全局交互。在多合一修复设置中的广泛基准测试证实了RAM的SOTA性能,在可训练参数方面减少了约82%的模型复杂性,在FLOPs方面减少了85%。我们的代码和模型将公开发布。
🔬 方法详解
问题定义:论文旨在解决通用图像修复问题,即如何使用一个模型有效地修复各种退化类型的图像。现有方法主要存在两个痛点:一是针对每种退化类型训练单独的模型,导致模型数量庞大且冗余;二是引入额外的模块(如视觉提示学习)或跨模态迁移(如利用大型语言模型),增加了模型的复杂度和计算成本。
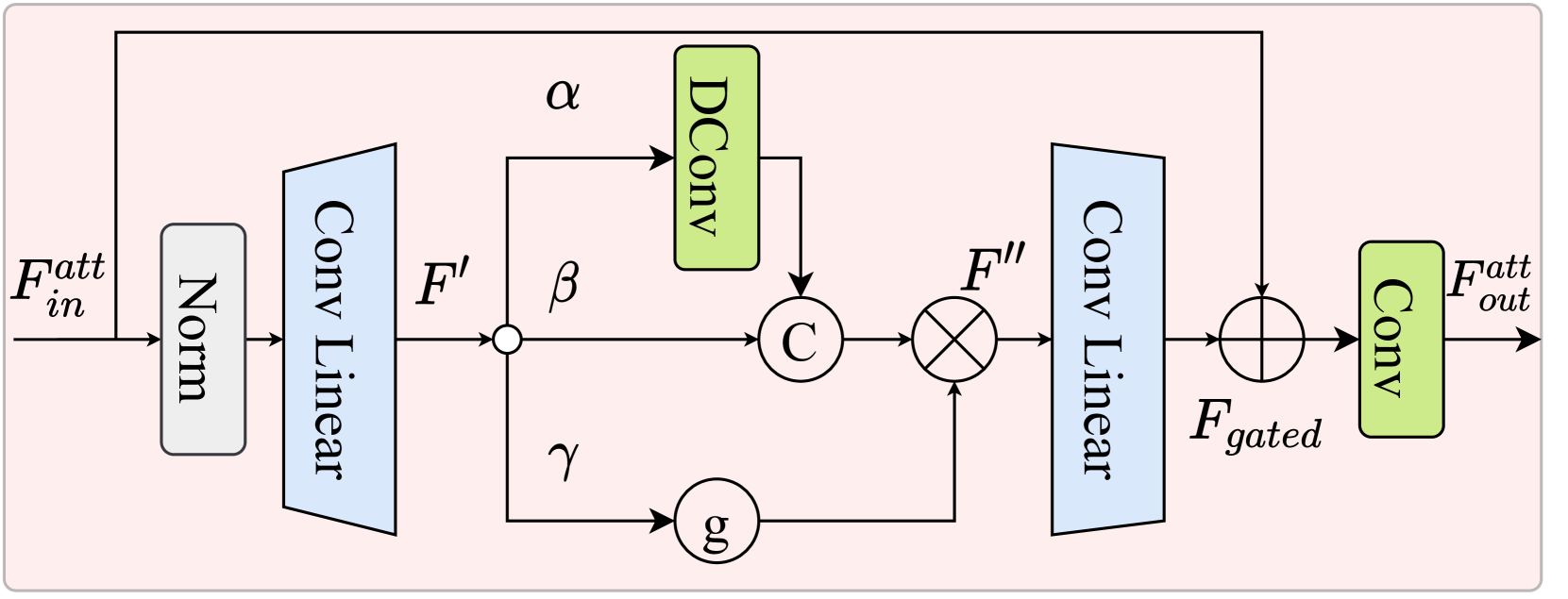
核心思路:论文的核心思路是利用不同退化类型之间的内在相似性,通过学习一个共享的嵌入空间,使得模型能够自适应地处理各种退化。具体来说,模型会识别输入图像的子潜在空间中的关键组件,并根据其重要性进行重新加权,从而实现对不同退化的感知。
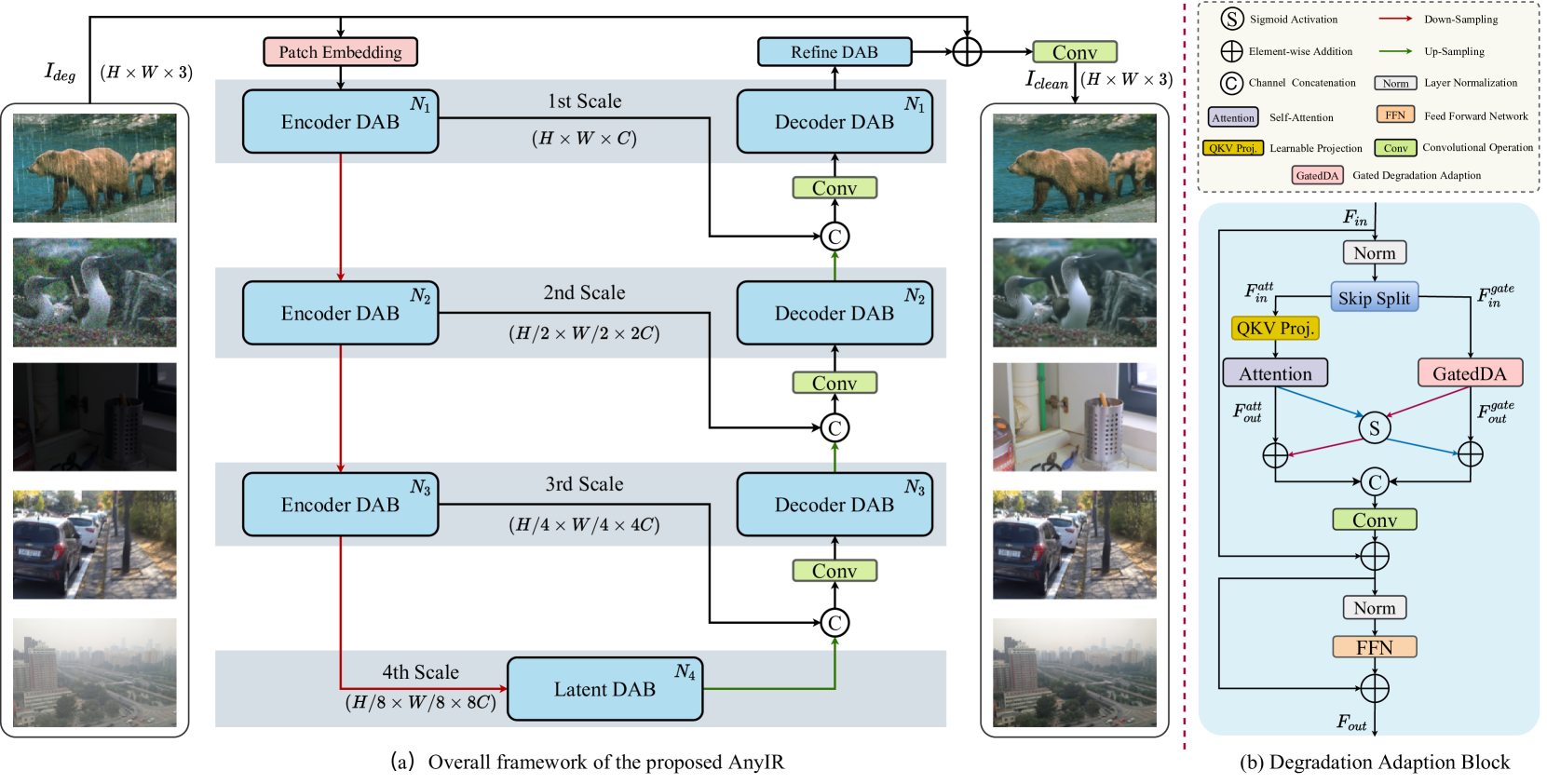
技术框架:RAM采用X形框架,主要包含两个关键模块:一是退化感知模块,用于识别和重新加权输入图像的子潜在空间中的关键组件;二是上下文注意力模块,用于增强局部和全局信息之间的交互。整个框架通过联合嵌入机制,将不同退化类型的图像映射到同一个嵌入空间,从而实现通用的图像修复。
关键创新:RAM的关键创新在于其退化自适应能力,即模型能够自动识别输入图像的退化类型,并根据退化类型调整修复策略。这种自适应能力是通过学习一个共享的嵌入空间和使用门控机制来实现的。与现有方法相比,RAM无需针对每种退化类型训练单独的模型,也无需引入额外的模块或跨模态迁移,从而显著降低了模型的复杂度和计算成本。
关键设计:RAM的关键设计包括:1) 使用子潜在空间分析来识别关键组件;2) 使用门控机制来重新加权这些组件,实现退化感知;3) 使用X形框架来增强局部和全局信息之间的交互;4) 损失函数的设计可能包含重建损失和对抗损失等,以保证修复图像的质量和真实感。(具体参数设置和损失函数细节未知,需参考论文)
🖼️ 关键图片
📊 实验亮点
RAM在通用图像修复任务上取得了SOTA性能,同时显著降低了模型复杂度和计算量。具体来说,RAM在可训练参数方面减少了约82%,在FLOPs方面减少了85%。这意味着RAM可以在更少的计算资源下实现更好的修复效果,具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于移动设备上的图像增强、老照片修复、视频监控图像修复等领域。通过降低模型复杂度和计算量,RAM有望在资源受限的设备上实现高效的图像修复,提升用户体验。未来,该技术还可扩展到其他图像处理任务,如图像超分辨率、图像去噪等。
📄 摘要(原文)
With the proliferation of mobile devices, the need for an efficient model to restore any degraded image has become increasingly significant and impactful. Traditional approaches typically involve training dedicated models for each specific degradation, resulting in inefficiency and redundancy. More recent solutions either introduce additional modules to learn visual prompts significantly increasing model size or incorporate cross-modal transfer from large language models trained on vast datasets, adding complexity to the system architecture. In contrast, our approach, termed RAM, takes a unified path that leverages inherent similarities across various degradations to enable both efficient and comprehensive restoration through a joint embedding mechanism without scaling up the model or relying on large multimodal models. Specifically, we examine the sub-latent space of each input, identifying key components and reweighting them in a gated manner. This intrinsic degradation awareness is further combined with contextualized attention in an X-shaped framework, enhancing local-global interactions. Extensive benchmarking in an all-in-one restoration setting confirms RAM's SOTA performance, reducing model complexity by approximately 82% in trainable parameters and 85% in FLOPs. Our code and models will be publicly available.