ColorMAE: Exploring data-independent masking strategies in Masked AutoEncoders
作者: Carlos Hinojosa, Shuming Liu, Bernard Ghanem
分类: cs.CV, cs.AI, cs.LG, eess.IV
发布日期: 2024-07-17
备注: Work Accepted for Publication at ECCV 2024
💡 一句话要点
ColorMAE:探索掩码自编码器中数据无关的掩码策略,提升语义分割性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 掩码自编码器 自监督学习 数据无关掩码 彩色噪声 语义分割 图像表示学习 视觉预训练
📋 核心要点
- 现有MAE方法依赖数据相关的复杂掩码策略,增加了计算成本和模型复杂度。
- ColorMAE通过过滤随机噪声生成掩码,无需额外参数或计算,引入空间和语义先验。
- 实验表明,ColorMAE在下游任务中优于随机掩码,语义分割mIoU提升2.72。
📝 摘要(中文)
掩码自编码器(MAE)已成为一种强大的自监督框架,在各种下游任务中表现出色。为了增加预训练任务的难度并学习更丰富的视觉表示,现有工作主要集中于用更复杂的策略(如对抗引导和教师引导掩码)来代替标准的随机掩码。然而,这些策略依赖于输入数据,因此通常会增加模型复杂性,并需要额外的计算来生成掩码模式。本文提出了一种简单而有效的数据无关方法,称为ColorMAE,它通过过滤随机噪声来生成不同的二元掩码模式。从图像处理中的彩色噪声中获得灵感,探索了四种类型的滤波器,以产生具有不同空间和语义先验的掩码模式。ColorMAE不需要额外的可学习参数或网络中的计算开销,但它显着增强了学习到的表示。我们提供了一个全面的经验评估,证明了我们的策略在下游任务中优于随机掩码。值得注意的是,相对于基线MAE实现,我们在语义分割任务中报告了2.72 mIoU的改进。
🔬 方法详解
问题定义:现有Masked Autoencoder (MAE) 方法为了提升性能,通常采用数据驱动的掩码策略,例如对抗引导或教师引导。这些方法虽然有效,但增加了计算复杂度,并且依赖于输入数据,限制了其通用性和效率。论文旨在解决如何在不增加计算负担和不依赖输入数据的情况下,提升MAE的性能。
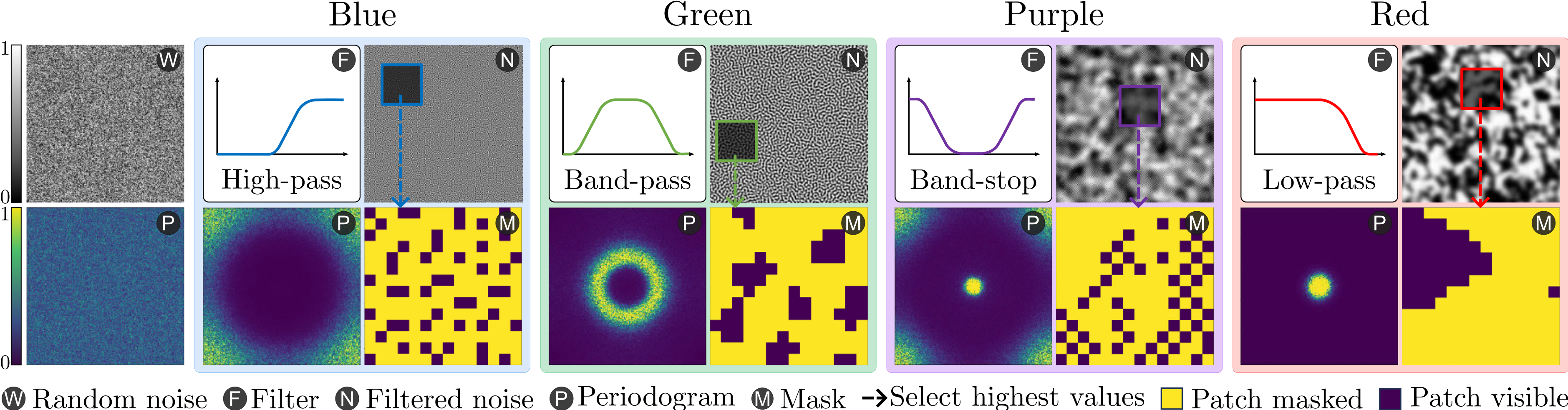
核心思路:ColorMAE的核心思想是利用数据无关的滤波器处理随机噪声,生成具有特定空间和语义先验的掩码模式。通过模拟图像处理中的彩色噪声,利用不同类型的滤波器来控制掩码的结构和分布,从而引导模型学习更有意义的视觉特征。这种方法既简单又高效,避免了数据依赖的复杂计算。
技术框架:ColorMAE的整体框架与标准的MAE类似,主要包括编码器和解码器。不同之处在于掩码生成的方式。ColorMAE首先生成随机噪声,然后使用预定义的滤波器(如高斯滤波器、带阻滤波器等)对噪声进行滤波,生成二元掩码。编码器接收被掩码的图像,提取特征,解码器重建原始图像。整个过程无需额外的学习参数。
关键创新:ColorMAE的关键创新在于提出了数据无关的掩码生成方法,通过滤波器处理随机噪声来引入空间和语义先验。与现有方法相比,ColorMAE不需要额外的计算或数据依赖性,同时能够有效提升模型性能。这种方法简化了掩码生成过程,并为MAE的改进提供了一种新的思路。
关键设计:ColorMAE的关键设计在于滤波器的选择和参数设置。论文探索了四种类型的滤波器:高斯滤波器、带阻滤波器、高通滤波器和低通滤波器。不同的滤波器会产生不同的掩码模式,从而影响模型的学习效果。论文通过实验分析了不同滤波器的性能,并给出了相应的建议。此外,掩码比例也是一个重要的参数,需要根据具体任务进行调整。
🖼️ 关键图片


📊 实验亮点
ColorMAE在语义分割任务中取得了显著的性能提升。在ADE20K数据集上,ColorMAE相对于基线MAE实现了2.72 mIoU的提升。此外,ColorMAE在图像分类和目标检测等任务中也表现出优越的性能,证明了其有效性和通用性。实验结果表明,ColorMAE是一种简单而有效的MAE改进方法。
🎯 应用场景
ColorMAE具有广泛的应用前景,可用于图像分类、目标检测、语义分割等各种计算机视觉任务。其数据无关的特性使其易于部署和应用,尤其适用于资源受限的场景。未来,ColorMAE可以进一步扩展到视频处理、3D数据分析等领域,为自监督学习提供更强大的支持。
📄 摘要(原文)
Masked AutoEncoders (MAE) have emerged as a robust self-supervised framework, offering remarkable performance across a wide range of downstream tasks. To increase the difficulty of the pretext task and learn richer visual representations, existing works have focused on replacing standard random masking with more sophisticated strategies, such as adversarial-guided and teacher-guided masking. However, these strategies depend on the input data thus commonly increasing the model complexity and requiring additional calculations to generate the mask patterns. This raises the question: Can we enhance MAE performance beyond random masking without relying on input data or incurring additional computational costs? In this work, we introduce a simple yet effective data-independent method, termed ColorMAE, which generates different binary mask patterns by filtering random noise. Drawing inspiration from color noise in image processing, we explore four types of filters to yield mask patterns with different spatial and semantic priors. ColorMAE requires no additional learnable parameters or computational overhead in the network, yet it significantly enhances the learned representations. We provide a comprehensive empirical evaluation, demonstrating our strategy's superiority in downstream tasks compared to random masking. Notably, we report an improvement of 2.72 in mIoU in semantic segmentation tasks relative to baseline MAE implementations.