EchoSight: Advancing Visual-Language Models with Wiki Knowledge
作者: Yibin Yan, Weidi Xie
分类: cs.CV
发布日期: 2024-07-17 (更新: 2024-12-02)
备注: Accepted by EMNLP 2024 findings; Project Page: https://go2heart.github.io/echosight
DOI: 10.18653/v1/2024.findings-emnlp.83
💡 一句话要点
EchoSight:利用维基知识增强视觉-语言模型,提升知识型VQA性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 知识图谱 检索增强生成 多模态学习 大型语言模型
📋 核心要点
- 现有KVQA方法在集成外部知识方面存在不足,限制了生成模型在需要细粒度百科知识的任务中的表现。
- EchoSight提出一种多模态RAG框架,通过视觉信息引导的维基百科文章检索和重排序,增强知识集成。
- 实验表明,EchoSight在Encyclopedic VQA和InfoSeek数据集上取得了SOTA结果,显著提升了知识型VQA的准确率。
📝 摘要(中文)
知识型视觉问答(KVQA)任务需要利用广泛的背景知识来回答关于图像的问题。尽管取得了显著进展,但由于外部知识集成有限,生成模型通常难以胜任这些任务。本文提出了EchoSight,一种新颖的多模态检索增强生成(RAG)框架,使大型语言模型(LLM)能够回答需要细粒度百科知识的视觉问题。为了实现高性能检索,EchoSight首先仅使用视觉信息搜索维基百科文章,然后根据这些候选文章与组合的文本-图像查询的相关性对其进行重新排序。这种方法显著提高了多模态知识的集成,从而改善了检索结果并提高了VQA响应的准确性。在Encyclopedic VQA和InfoSeek数据集上的实验结果表明,EchoSight在知识型VQA中建立了新的最先进水平,在Encyclopedic VQA上实现了41.8%的准确率,在InfoSeek上实现了31.3%的准确率。
🔬 方法详解
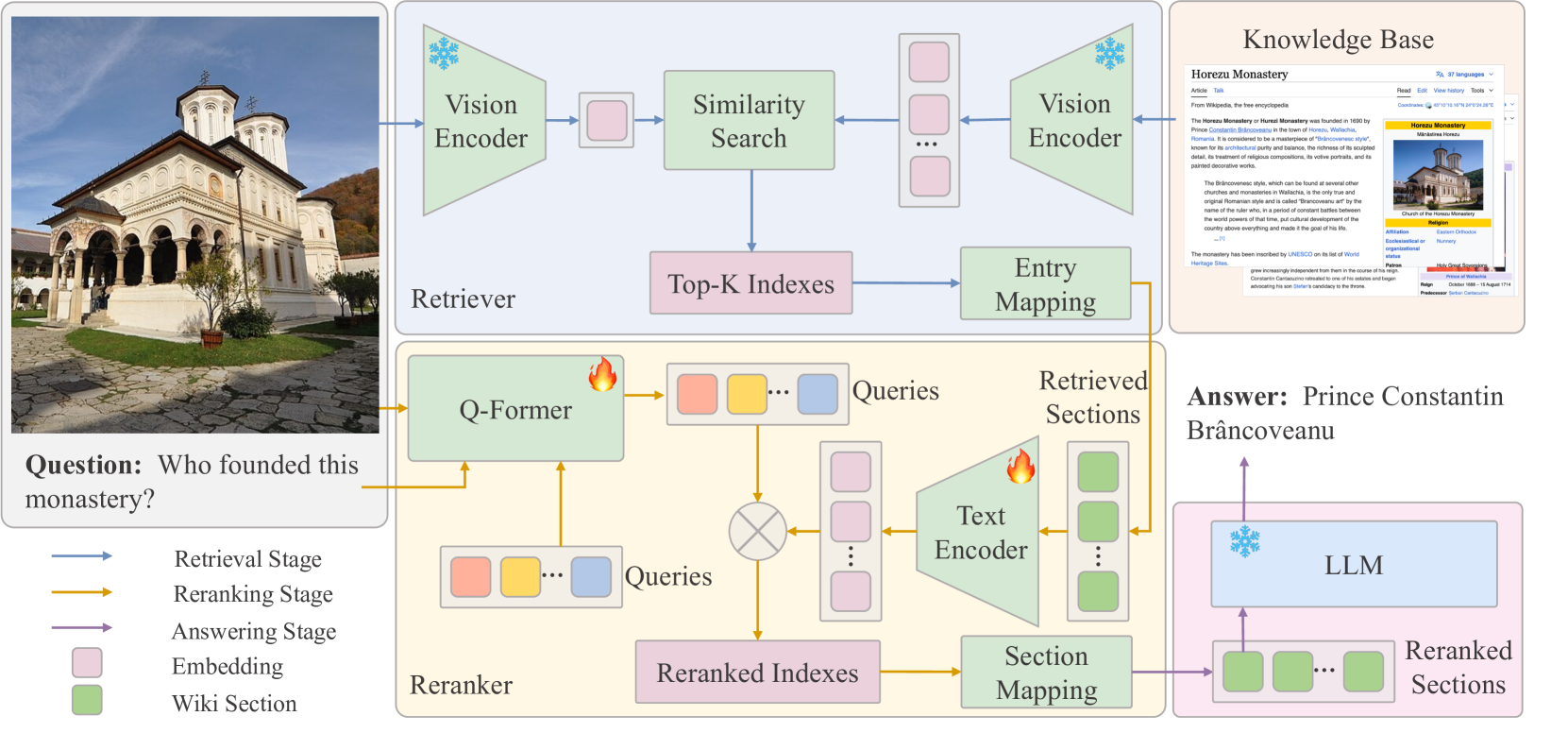
问题定义:论文旨在解决知识型视觉问答(KVQA)任务中,现有方法难以有效利用外部知识的问题。现有方法通常难以准确检索到与图像和问题都相关的知识,导致回答准确率不高。痛点在于如何更好地将视觉信息与文本信息结合,从而更精确地检索和利用外部知识。
核心思路:EchoSight的核心思路是利用视觉信息作为初始检索的引导,先通过视觉信息筛选出相关的维基百科文章,然后再结合文本信息对这些文章进行重排序,从而提高检索的准确性。这种两阶段的检索策略能够更有效地利用多模态信息,从而提升VQA的性能。
技术框架:EchoSight的整体框架是一个多模态检索增强生成(RAG)流程。它包含以下几个主要阶段:1) 视觉信息编码:使用视觉模型提取图像的特征。2) 初始检索:利用视觉特征在维基百科文章库中进行检索,得到候选文章。3) 多模态重排序:结合图像和文本信息,对候选文章进行重排序,选择最相关的文章。4) 答案生成:利用大型语言模型(LLM),结合图像、问题和检索到的知识生成答案。
关键创新:EchoSight的关键创新在于其两阶段的检索策略,即先使用视觉信息进行初始检索,再使用多模态信息进行重排序。这种策略能够更有效地利用视觉信息,避免了文本信息在初始检索阶段的干扰,从而提高了检索的准确性。与现有方法相比,EchoSight更注重视觉信息在知识检索中的作用。
关键设计:在初始检索阶段,可以使用预训练的视觉模型(如CLIP)提取图像特征,并使用向量相似度搜索维基百科文章。在多模态重排序阶段,可以使用交叉注意力机制融合图像和文本信息,并训练一个排序模型来预测文章的相关性。损失函数可以使用pairwise ranking loss,优化目标是使相关文章的得分高于不相关文章。
🖼️ 关键图片


📊 实验亮点
EchoSight在Encyclopedic VQA数据集上取得了41.8%的准确率,在InfoSeek数据集上取得了31.3%的准确率,均达到了新的SOTA水平。相较于之前的最佳方法,EchoSight在两个数据集上均有显著提升,证明了其在知识型VQA任务中的有效性。
🎯 应用场景
EchoSight具有广泛的应用前景,例如智能客服、教育辅助、医疗诊断等领域。它可以帮助用户更准确地理解图像内容,并利用外部知识回答相关问题。未来,该技术可以应用于更复杂的场景,例如自动驾驶、机器人导航等,为人工智能的发展提供更强大的支持。
📄 摘要(原文)
Knowledge-based Visual Question Answering (KVQA) tasks require answering questions about images using extensive background knowledge. Despite significant advancements, generative models often struggle with these tasks due to the limited integration of external knowledge. In this paper, we introduce EchoSight, a novel multimodal Retrieval-Augmented Generation (RAG) framework that enables large language models (LLMs) to answer visual questions requiring fine-grained encyclopedic knowledge. To strive for high-performing retrieval, EchoSight first searches wiki articles by using visual-only information, subsequently, these candidate articles are further reranked according to their relevance to the combined text-image query. This approach significantly improves the integration of multimodal knowledge, leading to enhanced retrieval outcomes and more accurate VQA responses. Our experimental results on the Encyclopedic VQA and InfoSeek datasets demonstrate that EchoSight establishes new state-of-the-art results in knowledge-based VQA, achieving an accuracy of 41.8% on Encyclopedic VQA and 31.3% on InfoSeek.