Motion-prior Contrast Maximization for Dense Continuous-Time Motion Estimation
作者: Friedhelm Hamann, Ziyun Wang, Ioannis Asmanis, Kenneth Chaney, Guillermo Gallego, Kostas Daniilidis
分类: cs.CV, cs.LG, cs.RO
发布日期: 2024-07-15
备注: 24 pages, 8 figures, 8 tables, Project Page: https://github.com/tub-rip/MotionPriorCMax
期刊: European Conference on Computer Vision (ECCV), Milan, 2024
DOI: 10.1007/978-3-031-72646-0_2
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于运动先验对比最大化的密集连续时间运动估计方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 事件相机 运动估计 对比学习 自监督学习 光流估计
📋 核心要点
- 现有光流和点跟踪方法依赖大量合成数据,难以适应真实场景,尤其是在事件相机数据上。
- 该论文提出一种自监督损失,结合对比最大化和非线性运动先验,用于事件相机的运动估计。
- 实验表明,该方法在EVIMO2数据集上零样本性能提升29%,并在DSEC光流基准上达到SOTA。
📝 摘要(中文)
当前的光流和点跟踪方法严重依赖合成数据集。事件相机是一种新型视觉传感器,在具有挑战性的视觉条件下具有优势,但由于当前事件模拟器的局限性,最先进的基于帧的方法无法轻易地适应事件数据。我们提出了一种新的自监督损失,将对比最大化框架与非线性运动先验(以像素级轨迹的形式)相结合,并提出了一种有效的解决方案来解决非线性轨迹和事件之间的高维分配问题。在两种场景中证明了其有效性:在密集连续时间运动估计中,我们的方法将合成训练模型在真实世界数据集EVIMO2上的零样本性能提高了29%。在光流估计中,我们的方法提升了一个简单的UNet,在DSEC光流基准测试中实现了自监督方法中的最先进性能。我们的代码可在https://github.com/tub-rip/MotionPriorCMax获得。
🔬 方法详解
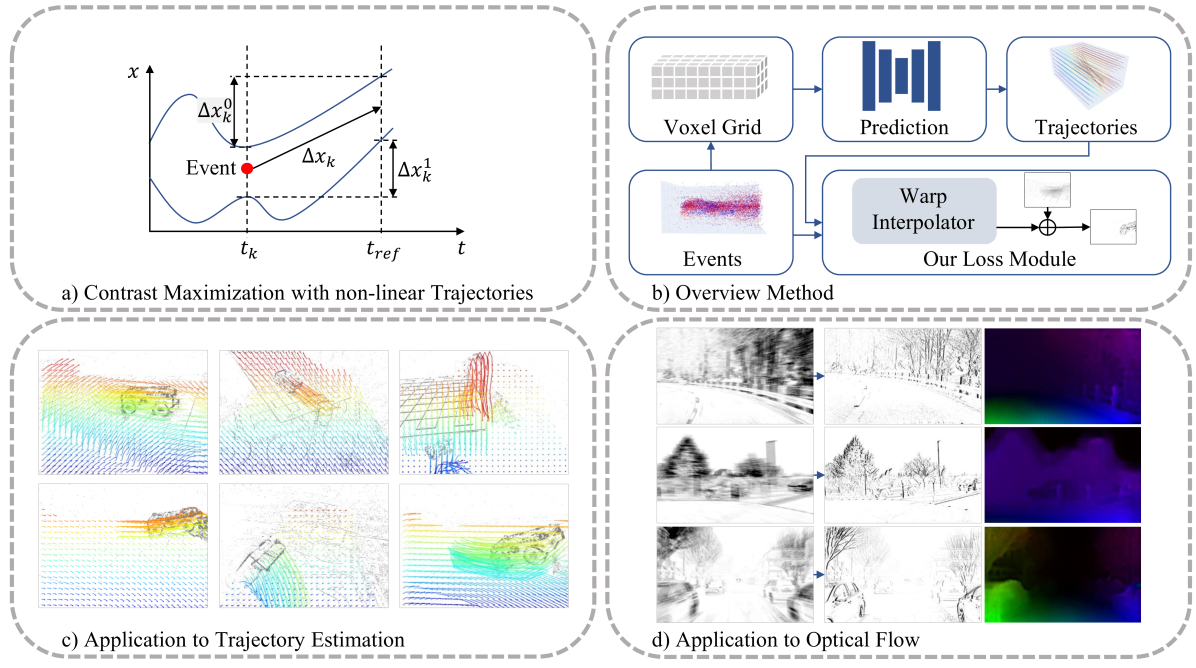
问题定义:现有光流和点跟踪方法过度依赖合成数据进行训练,导致在真实场景,特别是事件相机数据上的泛化能力不足。事件相机数据具有异步、高动态范围等特点,传统基于帧的方法难以直接应用,而现有的事件相机模拟器又存在局限性,无法生成足够逼真的训练数据。因此,如何利用真实事件数据进行自监督学习,提升模型在真实场景下的运动估计性能,是一个亟待解决的问题。
核心思路:该论文的核心思路是将对比最大化框架与非线性运动先验相结合,构建一个自监督学习框架。对比最大化旨在拉近相似特征,推远不相似特征,从而学习到更具区分性的表示。运动先验则利用像素级轨迹来约束运动估计,提高估计的准确性和鲁棒性。通过将这两种思想结合,模型可以在没有人工标注的情况下,从事件数据中学习到有效的运动信息。
技术框架:整体框架包含以下几个主要模块:1) 事件数据输入;2) 特征提取网络(例如UNet);3) 运动先验模块,用于生成像素级轨迹;4) 对比最大化损失计算模块,该模块基于运动先验,计算事件特征之间的对比损失;5) 优化器,用于更新网络参数。整个流程是:首先,事件数据经过特征提取网络得到特征表示;然后,运动先验模块生成像素级轨迹;接着,对比最大化损失计算模块根据轨迹信息,计算事件特征之间的对比损失;最后,优化器根据损失值更新网络参数,从而实现自监督学习。
关键创新:该论文的关键创新在于将对比最大化框架与非线性运动先验相结合,并提出了一种有效的解决方案来解决非线性轨迹和事件之间的高维分配问题。具体来说,传统的对比最大化方法通常基于图像块或像素之间的相似性进行计算,而该论文则利用运动先验信息,将像素级轨迹作为对比学习的约束,从而更好地利用了事件数据的时空信息。此外,该论文还提出了一种高效的算法来解决轨迹和事件之间的高维分配问题,使得该方法能够应用于大规模事件数据。
关键设计:在损失函数设计方面,该论文采用了对比损失函数,旨在拉近同一轨迹上的事件特征,推远不同轨迹上的事件特征。具体来说,对于每个事件,模型会根据运动先验找到其对应的轨迹,并将该轨迹上的其他事件作为正样本,将其他轨迹上的事件作为负样本。然后,模型会计算该事件与正样本和负样本之间的相似度,并根据相似度计算对比损失。在网络结构方面,该论文采用了UNet作为特征提取网络,并根据事件数据的特点进行了一些修改。此外,该论文还对运动先验模块进行了一些优化,使其能够更准确地生成像素级轨迹。
🖼️ 关键图片


📊 实验亮点
该方法在EVIMO2数据集上实现了显著的性能提升,零样本性能提高了29%,表明了其在真实场景下的泛化能力。此外,该方法还在DSEC光流基准测试中取得了自监督方法中的SOTA性能,超越了其他自监督光流估计方法,验证了其有效性。这些实验结果表明,该方法能够有效地利用事件数据进行自监督学习,并提高运动估计的准确性和鲁棒性。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、无人机等领域。通过利用事件相机数据进行自监督学习,可以提高这些系统在光照变化剧烈、高速运动等挑战性环境下的感知能力。此外,该方法还可以用于视频监控、运动分析等领域,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Current optical flow and point-tracking methods rely heavily on synthetic datasets. Event cameras are novel vision sensors with advantages in challenging visual conditions, but state-of-the-art frame-based methods cannot be easily adapted to event data due to the limitations of current event simulators. We introduce a novel self-supervised loss combining the Contrast Maximization framework with a non-linear motion prior in the form of pixel-level trajectories and propose an efficient solution to solve the high-dimensional assignment problem between non-linear trajectories and events. Their effectiveness is demonstrated in two scenarios: In dense continuous-time motion estimation, our method improves the zero-shot performance of a synthetically trained model on the real-world dataset EVIMO2 by 29%. In optical flow estimation, our method elevates a simple UNet to achieve state-of-the-art performance among self-supervised methods on the DSEC optical flow benchmark. Our code is available at https://github.com/tub-rip/MotionPriorCMax.