ScaleFlow++: Robust and Accurate Estimation of 3D Motion from Video
作者: Han Ling, Quansen Sun
分类: cs.CV
发布日期: 2024-07-13 (更新: 2024-10-16)
备注: 14 pages; Previously this version appeared as arXiv:2409.12202 which was submitted as a new work by accident
🔗 代码/项目: GITHUB
💡 一句话要点
提出ScaleFlow++以解决3D运动估计不准确的问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D运动估计 光流估计 深度学习 跨尺度匹配 自动驾驶 机器人技术 运动预测
📋 核心要点
- 现有方法通常直接从RGB帧或光流回归深度运动(MID),导致估计结果不准确且不稳定。
- ScaleFlow++通过跨尺度匹配提取深层运动线索,并将光流和MID估计集成到统一架构中,采用端到端特征匹配。
- 在KITTI数据集上,ScaleFlow++的单目场景流估计性能最佳,SF-all指标显著降低,同时在刚性和非刚性场景中展现出优异的零-shot泛化能力。
📝 摘要(中文)
感知和理解3D运动是自动驾驶、机器人和运动预测等领域的核心技术。本文提出了一种名为ScaleFlow++的3D运动感知方法,具有良好的泛化能力。仅通过一对RGB图像,ScaleFlow++能够稳健地估计光流和深度运动(MID)。现有方法通常直接从两帧RGB图像或光流回归MID,导致结果不准确且不稳定。我们的关键见解是跨尺度匹配,通过在不同尺度下匹配图像中的物体来提取深层运动线索。与之前的方法不同,ScaleFlow++将光流和MID估计集成到统一架构中,基于特征匹配端到端地进行估计。此外,我们还提出了全局初始化网络、全局迭代优化器和混合训练管道等模块,以整合全局运动信息,减少迭代次数,并防止训练过程中的过拟合。在KITTI数据集上,ScaleFlow++在单目场景流估计性能上达到了最佳,SF-all从6.21降低至5.79,MID的评估甚至超过了基于RGBD的方法。此外,ScaleFlow++在刚性和非刚性场景中实现了惊人的零-shot泛化性能。代码可在https://github.com/HanLingsgjk/CSCV获取。
🔬 方法详解
问题定义:本文旨在解决从视频中准确估计3D运动的问题。现有方法往往依赖于直接回归,导致估计结果的不准确和不稳定性。
核心思路:ScaleFlow++的核心思路是通过跨尺度匹配提取深层运动线索,进而实现光流和MID的联合估计。这种设计使得模型能够更好地理解不同尺度下的运动信息。
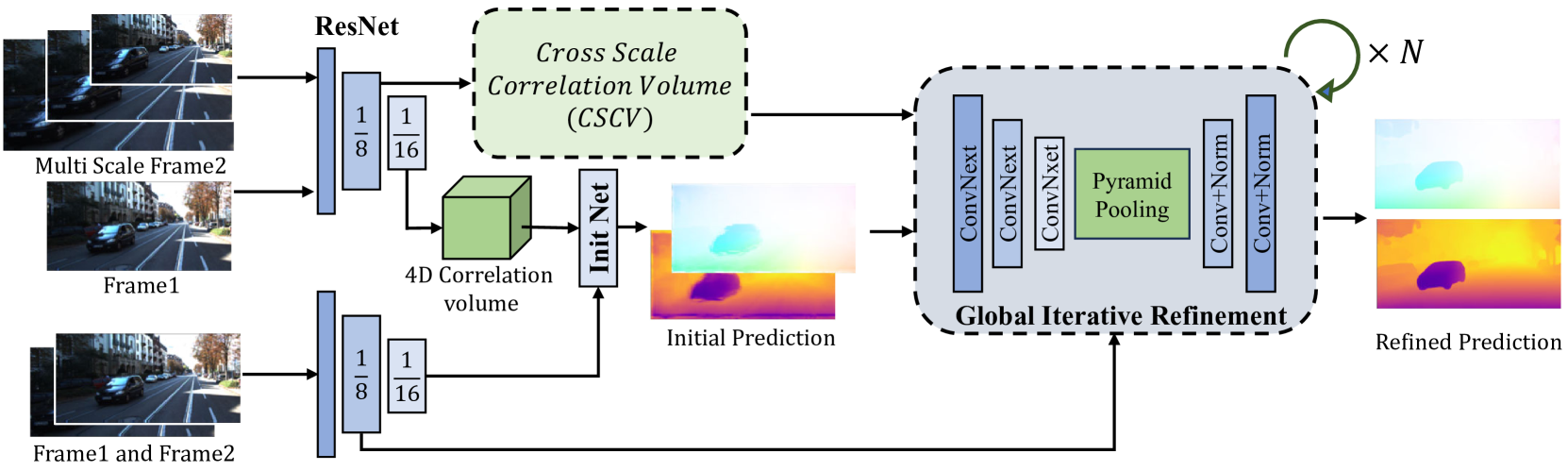
技术框架:ScaleFlow++的整体架构包括多个模块:全局初始化网络用于初始运动估计,全局迭代优化器用于优化运动参数,以及混合训练管道用于整合全局运动信息和防止过拟合。
关键创新:ScaleFlow++的主要创新在于将光流和MID估计集成到一个统一的框架中,并通过跨尺度匹配来增强运动线索的提取能力。这与现有方法的分离估计方式形成了明显的对比。
关键设计:在模型设计中,采用了特征匹配的端到端训练方式,优化了损失函数以提高估计精度,同时通过全局信息的整合来减少训练过程中的迭代次数。
🖼️ 关键图片


📊 实验亮点
在KITTI数据集上,ScaleFlow++实现了最佳的单目场景流估计性能,SF-all指标从6.21降低至5.79,显示出显著的性能提升。此外,其在MID评估中的表现超越了传统的RGBD方法,展现出优越的估计能力。
🎯 应用场景
ScaleFlow++在自动驾驶、机器人导航和运动预测等领域具有广泛的应用潜力。其准确的3D运动估计能力可以为自主系统提供更可靠的环境感知,进而提升决策和控制的有效性。未来,该方法可能在智能交通、无人机飞行和人机交互等场景中发挥重要作用。
📄 摘要(原文)
Perceiving and understanding 3D motion is a core technology in fields such as autonomous driving, robots, and motion prediction. This paper proposes a 3D motion perception method called ScaleFlow++ that is easy to generalize. With just a pair of RGB images, ScaleFlow++ can robustly estimate optical flow and motion-in-depth (MID). Most existing methods directly regress MID from two RGB frames or optical flow, resulting in inaccurate and unstable results. Our key insight is cross-scale matching, which extracts deep motion clues by matching objects in pairs of images at different scales. Unlike previous methods, ScaleFlow++ integrates optical flow and MID estimation into a unified architecture, estimating optical flow and MID end-to-end based on feature matching. Moreover, we also proposed modules such as global initialization network, global iterative optimizer, and hybrid training pipeline to integrate global motion information, reduce the number of iterations, and prevent overfitting during training. On KITTI, ScaleFlow++ achieved the best monocular scene flow estimation performance, reducing SF-all from 6.21 to 5.79. The evaluation of MID even surpasses RGBD-based methods. In addition, ScaleFlow++ has achieved stunning zero-shot generalization performance in both rigid and nonrigid scenes. Code is available at \url{https://github.com/HanLingsgjk/CSCV}.