ProDepth: Boosting Self-Supervised Multi-Frame Monocular Depth with Probabilistic Fusion
作者: Sungmin Woo, Wonjoon Lee, Woo Jin Kim, Dogyoon Lee, Sangyoun Lee
分类: cs.CV
发布日期: 2024-07-12
备注: Accepted by ECCV 2024. Project Page: https://sungmin-woo.github.io/prodepth/
💡 一句话要点
ProDepth:利用概率融合提升自监督多帧单目深度估计
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting)
关键词: 自监督学习 深度估计 多帧单目 动态场景 概率融合 代价体调制
📋 核心要点
- 现有自监督多帧深度估计方法在动态场景中,由于移动物体导致几何一致性假设失效,产生特征匹配错误。
- ProDepth通过引入概率方法,估计场景动态性不确定性,并利用该不确定性校正代价体和调整损失权重。
- 实验结果表明,ProDepth在Cityscapes、KITTI和Waymo Open数据集上均优于现有方法,具有更好的泛化性。
📝 摘要(中文)
自监督多帧单目深度估计依赖于连续帧之间的几何一致性,并假设场景是静态的。然而,动态场景中移动物体的存在会引入不可避免的不一致性,导致多帧特征匹配错位,并在训练期间产生误导性的自监督。本文提出了一种名为ProDepth的新框架,该框架使用概率方法有效地解决了由动态对象引起的不匹配问题。我们首先通过采用辅助解码器来推断与静态场景假设相关的不确定性。该解码器分析嵌入在代价体中的不一致性,推断区域为动态的概率。然后,我们通过概率代价体调制(PCVM)模块直接校正动态区域的错误代价体。具体来说,我们从单帧和多帧线索中推导出深度候选的概率分布,通过基于推断的不确定性自适应地融合这些分布来调制代价体。此外,我们提出了一种自监督损失重加权策略,该策略不仅屏蔽掉具有高不确定性的不正确监督,而且根据概率减轻剩余可能动态区域的风险。我们提出的方法在Cityscapes和KITTI数据集的所有指标上都优于最先进的方法,并在Waymo Open数据集上展示了卓越的泛化能力。
🔬 方法详解
问题定义:自监督多帧单目深度估计在静态场景下表现良好,但当场景中存在移动物体时,静态场景假设不再成立,导致连续帧之间的几何一致性被破坏。这会引起特征匹配错误,进而影响深度估计的准确性。现有方法难以有效处理这种由动态物体引起的不一致性,导致深度估计性能下降。
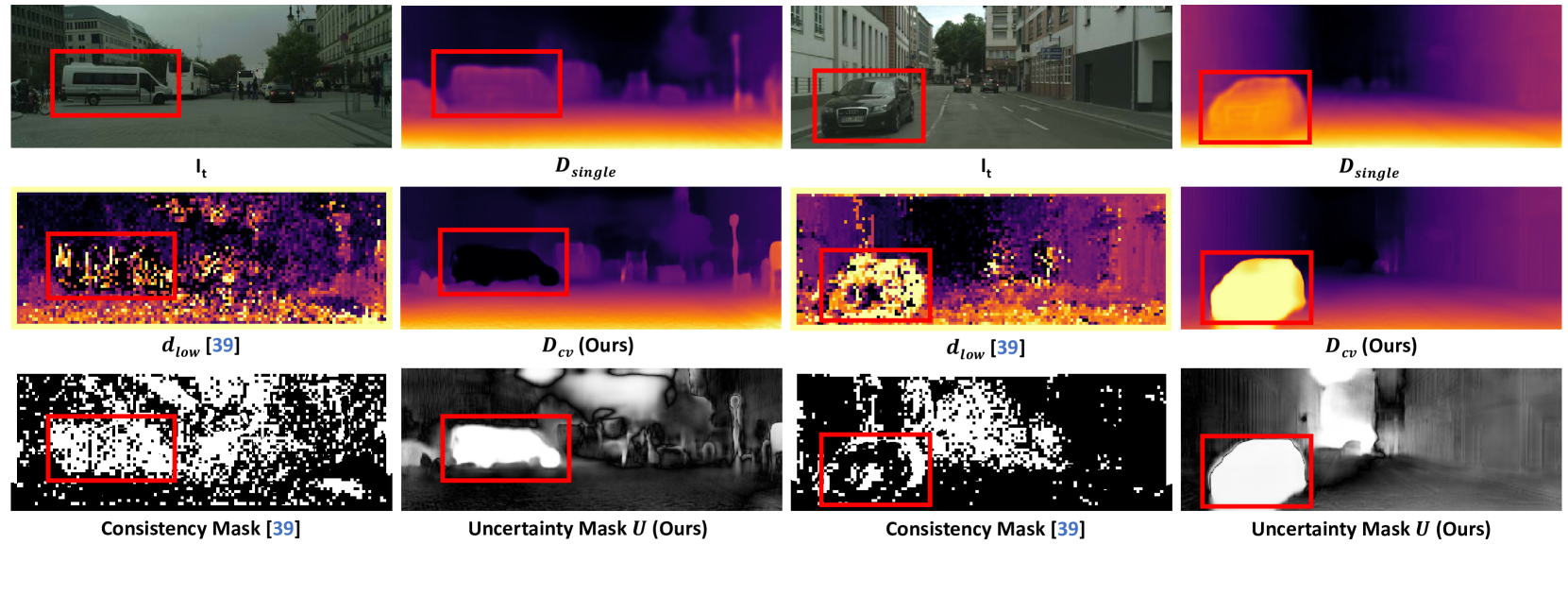
核心思路:ProDepth的核心思路是利用概率方法来建模场景的动态性不确定性。通过分析代价体中的不一致性,估计每个区域是动态的概率。然后,利用这个概率信息来校正代价体,并调整自监督损失的权重。这样可以减少动态物体对深度估计的影响,提高模型的鲁棒性。
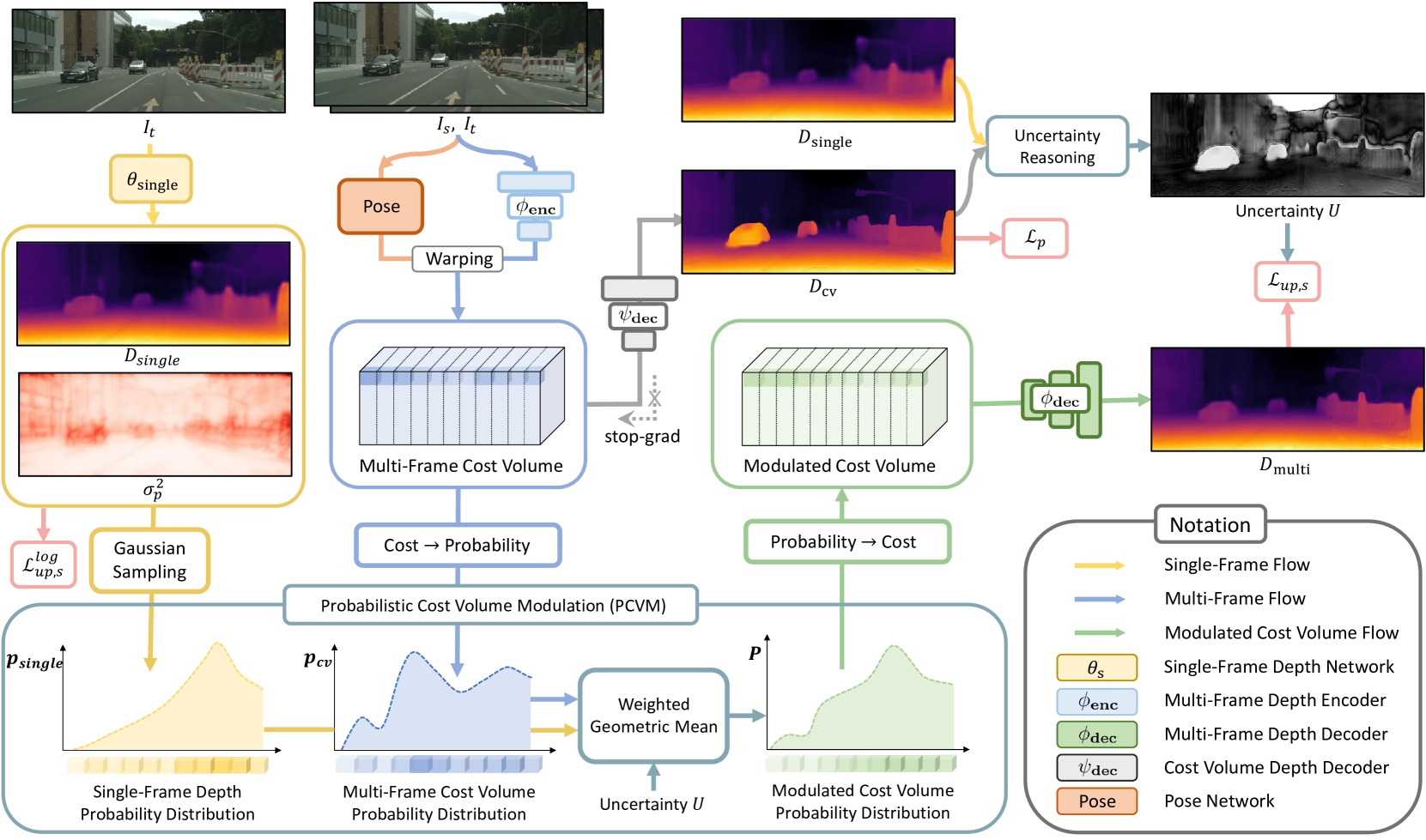
技术框架:ProDepth的整体框架包括以下几个主要模块:1) 特征提取网络:用于提取输入图像的特征。2) 代价体构建:基于多帧特征构建代价体,用于衡量不同深度假设下的匹配程度。3) 辅助解码器:分析代价体中的不一致性,估计每个区域是动态的概率。4) 概率代价体调制(PCVM):利用动态概率信息,自适应地融合单帧和多帧深度候选的概率分布,校正代价体。5) 深度估计网络:基于校正后的代价体估计深度图。6) 自监督损失重加权:根据动态概率信息,调整自监督损失的权重。
关键创新:ProDepth的关键创新在于引入了概率方法来建模场景的动态性不确定性,并利用该不确定性来校正代价体和调整损失权重。与现有方法相比,ProDepth能够更有效地处理动态场景中的不一致性,提高深度估计的准确性和鲁棒性。PCVM模块是另一个创新点,它通过自适应地融合单帧和多帧深度候选的概率分布,可以更准确地估计深度。
关键设计:辅助解码器的设计至关重要,它需要能够有效地分析代价体中的不一致性,并准确地估计动态概率。PCVM模块中的融合策略需要能够根据不确定性自适应地调整单帧和多帧深度候选的权重。自监督损失重加权策略需要能够有效地屏蔽掉不正确的监督,并减轻剩余可能动态区域的风险。具体的损失函数设计和网络结构细节在论文中有详细描述,但此处无法完全复述。
🖼️ 关键图片

📊 实验亮点
ProDepth在Cityscapes和KITTI数据集上取得了显著的性能提升,在所有指标上均优于现有最先进的方法。此外,ProDepth在Waymo Open数据集上展示了卓越的泛化能力,表明其在不同场景下具有良好的鲁棒性。这些实验结果充分证明了ProDepth的有效性和优越性。
🎯 应用场景
ProDepth在自动驾驶、机器人导航、增强现实等领域具有广泛的应用前景。准确的深度估计是这些应用的关键组成部分。通过提高在动态场景下的深度估计精度,ProDepth可以提升自动驾驶系统的安全性,增强机器人对环境的感知能力,并改善增强现实体验。该研究对于提升计算机视觉系统在复杂真实环境中的性能具有重要意义。
📄 摘要(原文)
Self-supervised multi-frame monocular depth estimation relies on the geometric consistency between successive frames under the assumption of a static scene. However, the presence of moving objects in dynamic scenes introduces inevitable inconsistencies, causing misaligned multi-frame feature matching and misleading self-supervision during training. In this paper, we propose a novel framework called ProDepth, which effectively addresses the mismatch problem caused by dynamic objects using a probabilistic approach. We initially deduce the uncertainty associated with static scene assumption by adopting an auxiliary decoder. This decoder analyzes inconsistencies embedded in the cost volume, inferring the probability of areas being dynamic. We then directly rectify the erroneous cost volume for dynamic areas through a Probabilistic Cost Volume Modulation (PCVM) module. Specifically, we derive probability distributions of depth candidates from both single-frame and multi-frame cues, modulating the cost volume by adaptively fusing those distributions based on the inferred uncertainty. Additionally, we present a self-supervision loss reweighting strategy that not only masks out incorrect supervision with high uncertainty but also mitigates the risks in remaining possible dynamic areas in accordance with the probability. Our proposed method excels over state-of-the-art approaches in all metrics on both Cityscapes and KITTI datasets, and demonstrates superior generalization ability on the Waymo Open dataset.