MAVIS: Mathematical Visual Instruction Tuning with an Automatic Data Engine
作者: Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Shicheng Li, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Bin Wei, Shanghang Zhang, Peng Gao, Chunyuan Li, Hongsheng Li
分类: cs.CV
发布日期: 2024-07-11 (更新: 2024-11-01)
备注: WData and Models will be released at https://github.com/ZrrSkywalker/MAVIS
🔗 代码/项目: GITHUB
💡 一句话要点
MAVIS:利用自动数据引擎进行数学视觉指令调优,提升多模态大模型数学能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大模型 数学视觉 指令调优 自动数据引擎 思维链推理
📋 核心要点
- 现有的多模态大模型在数学图表的视觉编码、图文对齐和思维链推理方面存在不足,限制了其数学能力。
- MAVIS通过自动数据引擎生成大规模数学视觉数据集,并提出四阶段训练流程,无需人工干预或GPT API,保证数据质量。
- 实验表明,MAVIS能够有效提升多模态大模型在数学问题上的表现,尤其是在思维链推理方面。
📝 摘要(中文)
多模态大型语言模型(MLLM)的数学能力仍有待探索,尤其是在数学图表的视觉编码、图文对齐和思维链(CoT)推理三个方面。这迫切需要一种有效的训练范式和一个大规模、全面的数据集,其中包含详细的CoT原理,而这些数据的收集和手动标注成本高昂。为了解决这个问题,我们提出了MAVIS,一个用于MLLM的数学视觉指令调优流程,它具有一个自动数据引擎,可以高效地创建数学视觉数据集。我们设计的数据生成过程完全独立于人工干预或GPT API的使用,同时确保图文对应、问题答案的正确性和CoT推理质量。通过这种方法,我们整理了两个数据集,MAVIS-Caption(558K图文对)和MAVIS-Instruct(834K带有CoT原理的视觉数学问题),并提出了从头开始训练MLLM的四个渐进阶段。首先,我们利用MAVIS-Caption通过对比学习来微调一个数学特定的视觉编码器(CLIP-Math),专门用于改进图表视觉编码。其次,我们还利用MAVIS-Caption通过投影层将CLIP-Math与大型语言模型(LLM)对齐,从而增强数学领域中的视觉-语言对齐。第三,我们采用MAVIS-Instruct进行指令调优,以获得强大的问题解决能力,并将生成的模型称为MAVIS-7B。第四,我们应用直接偏好优化(DPO)来增强我们模型的CoT能力,进一步完善其逐步推理性能。
🔬 方法详解
问题定义:多模态大语言模型在处理包含图表的数学问题时,面临着视觉信息编码不准确、图文信息对齐困难以及缺乏有效的思维链推理能力等问题。现有的方法依赖于人工标注数据或使用GPT等API生成数据,成本高昂且难以保证数据质量。
核心思路:MAVIS的核心思路是构建一个自动数据引擎,能够高效、低成本地生成高质量的数学视觉数据集,包括图文对和带有思维链推理的问题解答。通过在该数据集上进行多阶段训练,提升多模态大语言模型在数学领域的视觉理解和推理能力。
技术框架:MAVIS的整体框架包含数据生成和模型训练两个主要部分。数据生成部分,自动数据引擎负责生成MAVIS-Caption和MAVIS-Instruct两个数据集。模型训练部分,首先使用MAVIS-Caption通过对比学习微调视觉编码器CLIP-Math,然后将CLIP-Math与LLM对齐。接着,使用MAVIS-Instruct进行指令调优,最后使用DPO优化模型的CoT能力。
关键创新:MAVIS的关键创新在于其自动数据引擎,该引擎能够独立生成高质量的数学视觉数据集,无需人工干预或依赖GPT API。此外,四阶段训练流程,包括视觉编码器微调、视觉-语言对齐、指令调优和DPO优化,也为提升多模态大语言模型的数学能力提供了有效的策略。
关键设计:在数据生成方面,设计了特定的规则和算法来保证图文对应、答案正确和CoT推理质量。在模型训练方面,CLIP-Math的微调采用了对比学习损失,视觉-语言对齐使用了投影层,指令调优采用了标准的多模态指令学习方法,DPO优化则使用了奖励模型来指导模型的CoT推理。
🖼️ 关键图片
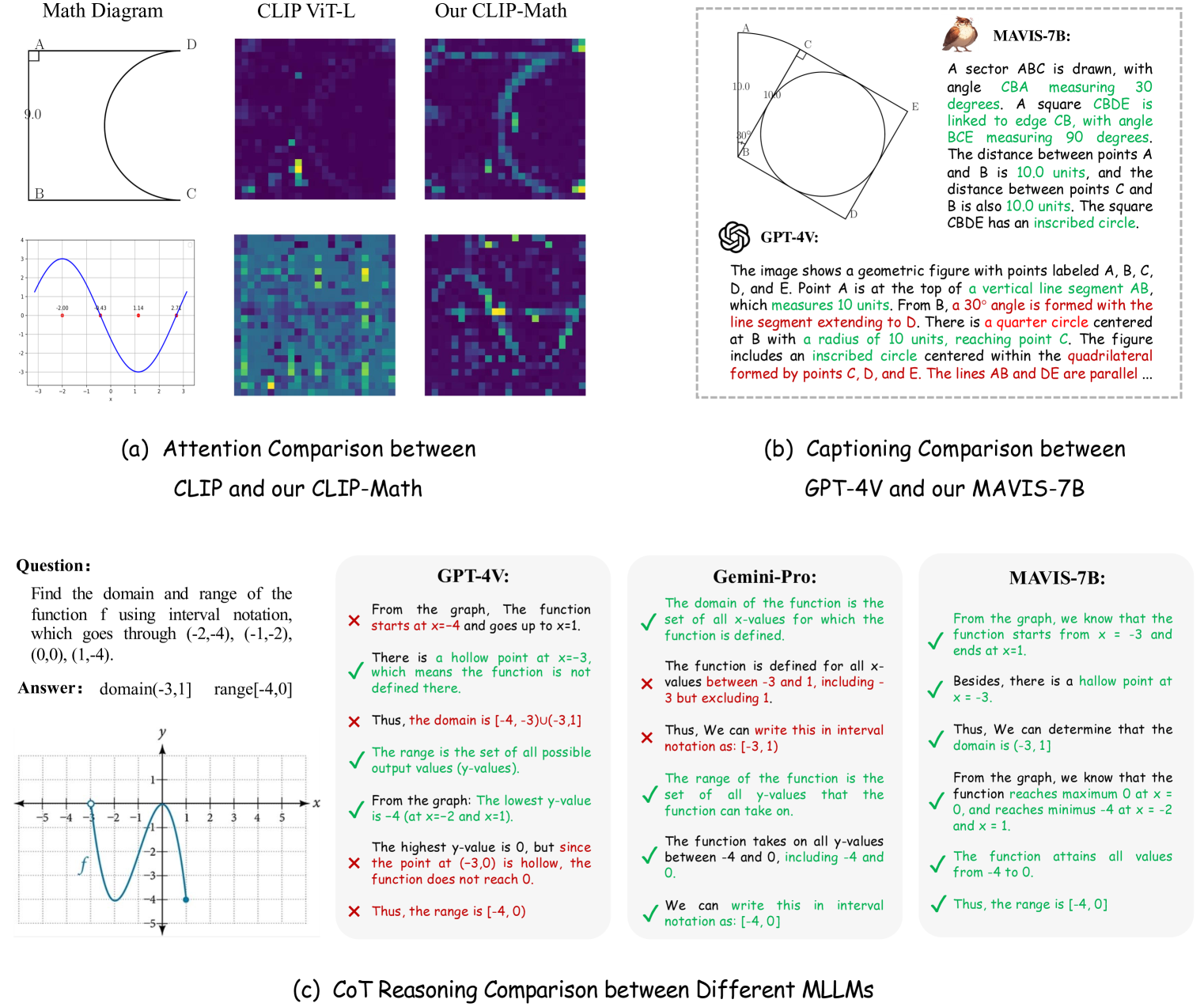

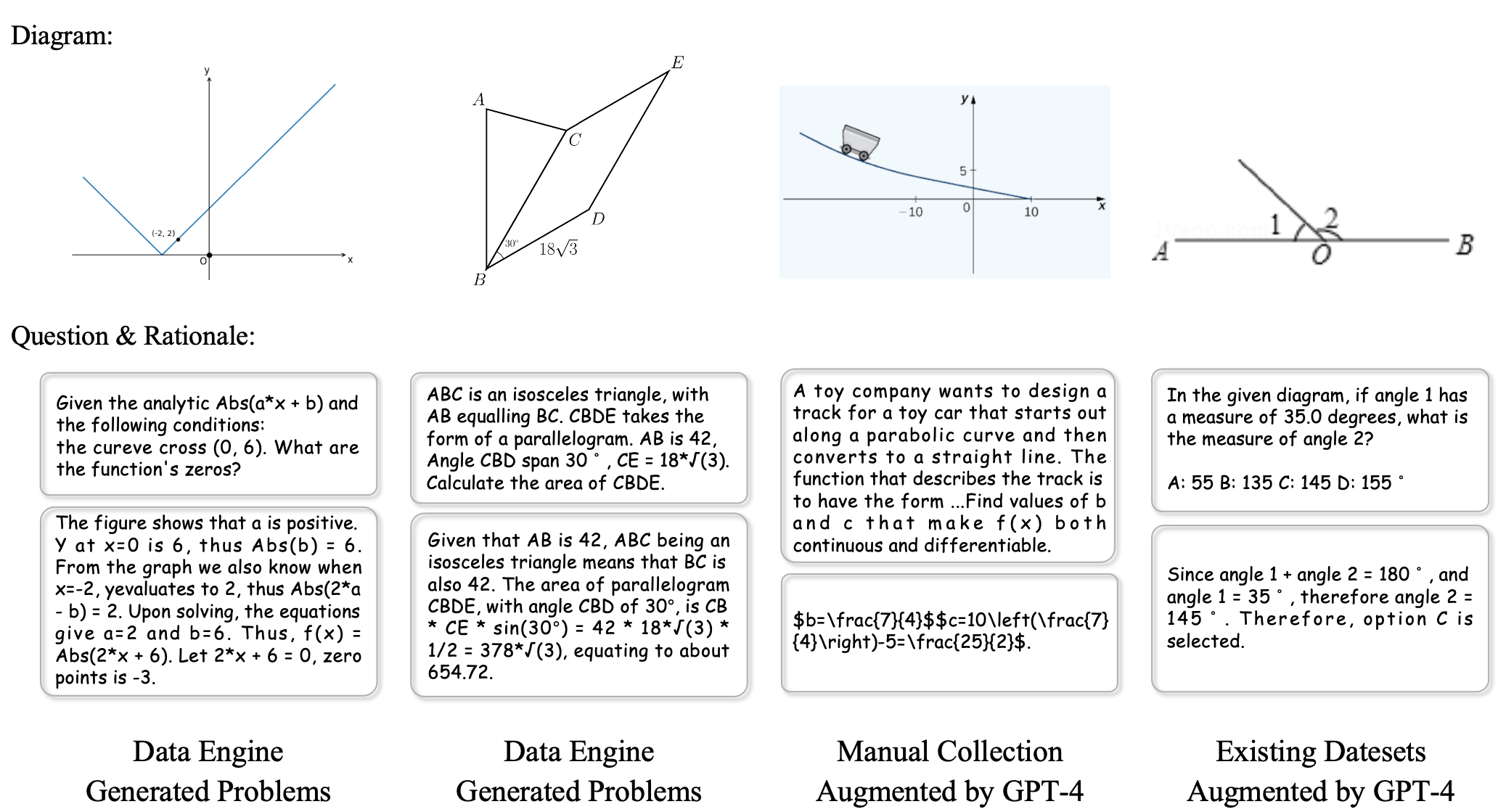
📊 实验亮点
MAVIS通过自动数据引擎生成了大规模的MAVIS-Caption (558K) 和 MAVIS-Instruct (834K) 数据集。实验结果表明,经过MAVIS训练的模型在数学问题解决能力上取得了显著提升,尤其是在思维链推理方面,相较于基线模型有明显的性能优势。具体性能数据未知。
🎯 应用场景
MAVIS的研究成果可应用于教育领域,例如开发智能辅导系统,帮助学生理解和解决数学问题。此外,该技术还可以应用于科学研究领域,例如自动分析科学图表和数据,辅助科研人员进行数据分析和知识发现。未来,MAVIS有望推动多模态大模型在更广泛的科学计算领域的应用。
📄 摘要(原文)
The mathematical capabilities of Multi-modal Large Language Models (MLLMs) remain under-explored with three areas to be improved: visual encoding of math diagrams, diagram-language alignment, and chain-of-thought (CoT) reasoning. This draws forth an urgent demand for an effective training paradigm and a large-scale, comprehensive dataset with detailed CoT rationales, which is challenging to collect and costly to annotate manually. To tackle this issue, we propose MAVIS, a MAthematical VISual instruction tuning pipeline for MLLMs, featuring an automatic data engine to efficiently create mathematical visual datasets. We design the data generation process to be entirely independent of human intervention or GPT API usage, while ensuring the diagram-caption correspondence, question-answer correctness, and CoT reasoning quality. With this approach, we curate two datasets, MAVIS-Caption (558K diagram-caption pairs) and MAVIS-Instruct (834K visual math problems with CoT rationales), and propose four progressive stages for training MLLMs from scratch. First, we utilize MAVIS-Caption to fine-tune a math-specific vision encoder (CLIP-Math) through contrastive learning, tailored for improved diagram visual encoding. Second, we also leverage MAVIS-Caption to align the CLIP-Math with a large language model (LLM) by a projection layer, enhancing vision-language alignment in mathematical domains. Third, we adopt MAVIS-Instruct to perform the instruction tuning for robust problem-solving skills, and term the resulting model as MAVIS-7B. Fourth, we apply Direct Preference Optimization (DPO) to enhance the CoT capabilities of our model, further refining its step-wise reasoning performance. Code and data will be released at https://github.com/ZrrSkywalker/MAVIS