SEED-Story: Multimodal Long Story Generation with Large Language Model
作者: Shuai Yang, Yuying Ge, Yang Li, Yukang Chen, Yixiao Ge, Ying Shan, Yingcong Chen
分类: cs.CV
发布日期: 2024-07-11 (更新: 2024-10-11)
备注: Our models, codes and datasets are released in https://github.com/TencentARC/SEED-Story
💡 一句话要点
SEED-Story:利用多模态大语言模型生成长篇多模态故事
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态故事生成 多模态大语言模型 长序列生成 视觉反tokenizer 注意力机制 自回归模型 StoryStream数据集
📋 核心要点
- 多模态故事生成任务需要理解文本和图像间的复杂关联,并生成长序列连贯内容,现有方法难以兼顾。
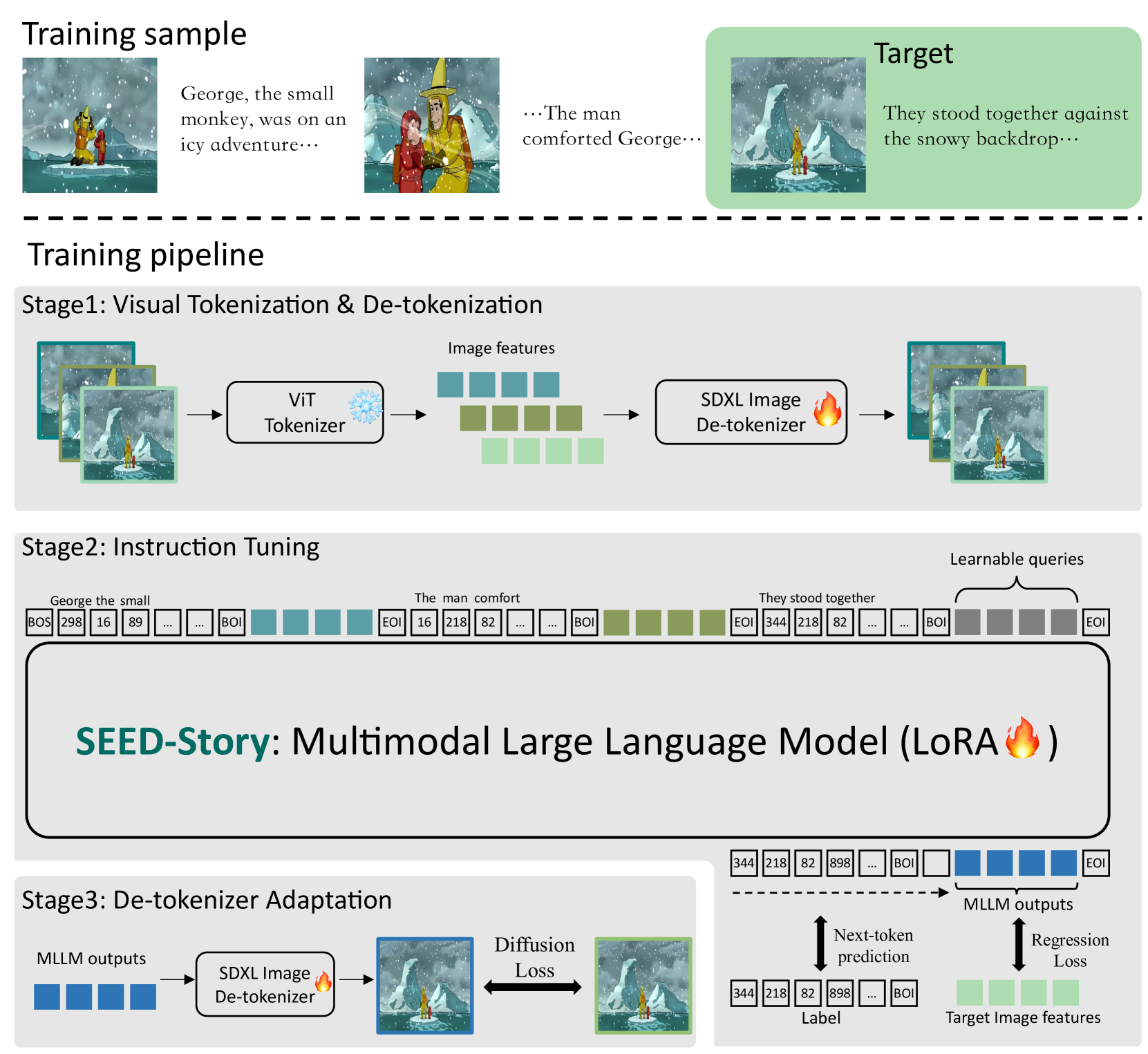
- SEED-Story利用多模态大语言模型,同时预测文本和视觉token,并使用视觉反tokenizer生成一致性图像。
- 提出的多模态注意力汇聚机制,使模型能够高效自回归地生成更长的故事序列,并构建了StoryStream数据集。
📝 摘要(中文)
随着图像生成和开放式文本生成技术的显著进步,交错式图文内容的创作变得越来越引人关注。多模态故事生成,以交替生成叙事文本和生动图像为特征,已成为一项有价值且实用的任务,具有广泛的应用前景。然而,这项任务带来了巨大的挑战,因为它需要理解文本和图像之间复杂的相互作用,并具备生成连贯、上下文相关的长序列文本和视觉内容的能力。本文提出了SEED-Story,一种利用多模态大语言模型(MLLM)生成扩展多模态故事的新方法。我们的模型建立在MLLM强大的理解能力之上,预测文本token以及视觉token,随后通过改进的视觉反tokenizer进行处理,以生成具有一致角色和风格的图像。我们进一步提出了多模态注意力汇聚机制,以高效的自回归方式生成多达25个序列的故事(训练仅需10个)。此外,我们提出了一个名为StoryStream的大规模高分辨率数据集,用于训练我们的模型,并从各个方面定量评估多模态故事生成任务。
🔬 方法详解
问题定义:多模态故事生成旨在生成交错的文本和图像序列,要求内容连贯、角色风格一致。现有方法难以生成长篇故事,且计算效率较低,难以处理长序列依赖关系。此外,缺乏大规模高质量数据集也限制了模型性能的提升。
核心思路:利用多模态大语言模型(MLLM)强大的理解和生成能力,将文本和图像生成统一到一个框架中。通过预测视觉token,并使用视觉反tokenizer生成图像,保证视觉内容的一致性。引入注意力汇聚机制,降低计算复杂度,实现长序列生成。
技术框架:SEED-Story模型基于MLLM,主要包含以下模块:1) MLLM:负责文本和视觉token的预测;2) 视觉反tokenizer:将视觉token转换为图像,保证图像质量和一致性;3) 多模态注意力汇聚机制:降低计算复杂度,支持长序列生成。模型以自回归的方式生成文本和图像序列。
关键创新:1) 提出了一种基于MLLM的多模态故事生成框架,能够同时处理文本和图像生成任务。2) 引入了视觉反tokenizer,保证生成图像的一致性和质量。3) 提出了多模态注意力汇聚机制,显著降低了计算复杂度,实现了长序列故事生成。
关键设计:视觉反tokenizer的具体实现细节(例如,使用的GAN架构、损失函数等)未知。多模态注意力汇聚机制的具体实现方式(例如,如何选择汇聚的token、汇聚的比例等)未知。StoryStream数据集的规模、数据分布、标注方式等细节未知。
🖼️ 关键图片


📊 实验亮点
论文提出了StoryStream数据集,并验证了SEED-Story模型在多模态故事生成任务上的有效性。通过多模态注意力汇聚机制,模型能够生成长达25个序列的故事,显著优于现有方法。具体的性能数据和对比基线未知,但论文强调了模型在生成长序列故事方面的优势。
🎯 应用场景
该研究成果可应用于自动化内容创作、教育娱乐、虚拟现实等领域。例如,可以用于生成儿童故事书、制作个性化漫画、构建沉浸式游戏体验等。未来,该技术有望进一步发展,实现更高质量、更具创意的内容生成,并推动多模态人工智能的发展。
📄 摘要(原文)
With the remarkable advancements in image generation and open-form text generation, the creation of interleaved image-text content has become an increasingly intriguing field. Multimodal story generation, characterized by producing narrative texts and vivid images in an interleaved manner, has emerged as a valuable and practical task with broad applications. However, this task poses significant challenges, as it necessitates the comprehension of the complex interplay between texts and images, and the ability to generate long sequences of coherent, contextually relevant texts and visuals. In this work, we propose SEED-Story, a novel method that leverages a Multimodal Large Language Model (MLLM) to generate extended multimodal stories. Our model, built upon the powerful comprehension capability of MLLM, predicts text tokens as well as visual tokens, which are subsequently processed with an adapted visual de-tokenizer to produce images with consistent characters and styles. We further propose multimodal attention sink mechanism to enable the generation of stories with up to 25 sequences (only 10 for training) in a highly efficient autoregressive manner. Additionally, we present a large-scale and high-resolution dataset named StoryStream for training our model and quantitatively evaluating the task of multimodal story generation in various aspects.