15M Multimodal Facial Image-Text Dataset
作者: Dawei Dai, YuTang Li, YingGe Liu, Mingming Jia, Zhang YuanHui, Guoyin Wang
分类: cs.CV, cs.AI
发布日期: 2024-07-11 (更新: 2024-07-12)
备注: 15 pages, 8 figures
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
发布FaceCaption-15M:大规模人脸图像-文本多模态数据集,促进人脸相关任务研究。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人脸图像 文本描述 多模态学习 对比学习 预训练模型 数据集 人脸识别 图像-文本对齐
📋 核心要点
- 现有方法在人脸相关任务中缺乏大规模、高质量的图像-文本对数据,限制了多模态深度学习模型的应用。
- 论文构建了FaceCaption-15M数据集,包含1500万张人脸图像和对应的自然语言描述,旨在促进人脸相关任务的研究。
- 通过在FaceCaption-15M上预训练FLIP模型,并在下游任务上进行微调,取得了state-of-the-art的结果,验证了数据集的有效性。
📝 摘要(中文)
本文提出了FaceCaption-15M,一个大规模、多样化和高质量的人脸图像及其自然语言描述(人脸图像到文本)的数据集。该数据集旨在促进以人脸为中心任务的研究。FaceCaption-15M包含超过1500万对人脸图像及其对应的面部特征自然语言描述,是迄今为止最大的人脸图像-文本描述数据集。我们对图像质量、文本自然度、文本复杂度和文本-图像相关性进行了全面分析,以证明FaceCaption-15M的优越性。为了验证FaceCaption-15M的有效性,我们首先训练了一个面部语言-图像预训练模型(FLIP,类似于CLIP),以在特征空间中对齐人脸图像及其对应的文本描述。随后,使用图像和文本编码器,仅微调线性层,我们基于FLIP的模型在两个具有挑战性的人脸中心任务上取得了最先进的结果。旨在通过所提出的FaceCaption-15M数据集的可用性来促进人脸相关任务领域的研究。所有数据、代码和模型均已公开。
🔬 方法详解
问题定义:现有的人脸相关任务,例如人脸识别、人脸属性预测等,通常依赖于图像数据或少量文本描述。缺乏大规模、高质量的人脸图像-文本对数据限制了多模态深度学习模型在该领域的应用,难以充分利用文本信息来提升模型性能。
核心思路:论文的核心思路是构建一个大规模的人脸图像-文本数据集,即FaceCaption-15M,其中包含大量的人脸图像以及对应的自然语言描述。通过在该数据集上进行预训练,可以学习到人脸图像和文本之间的关联,从而提升模型在各种人脸相关任务上的性能。
技术框架:整体框架包含数据集构建和模型训练两个主要阶段。数据集构建阶段,收集并清洗了1500万张人脸图像及其对应的文本描述。模型训练阶段,采用了类似于CLIP的FLIP模型,包含图像编码器和文本编码器,通过对比学习的方式,将人脸图像和文本描述映射到同一个特征空间。
关键创新:该论文的关键创新在于构建了迄今为止最大的人脸图像-文本数据集FaceCaption-15M。与现有数据集相比,FaceCaption-15M在规模、多样性和质量上都具有显著优势,能够更好地支持多模态深度学习模型在该领域的应用。
关键设计:在模型训练方面,采用了对比学习的损失函数,鼓励相似的图像-文本对在特征空间中靠近,而不相似的图像-文本对远离。图像编码器和文本编码器可以采用不同的网络结构,例如ResNet和Transformer。在下游任务微调时,只微调线性层,以减少计算量和防止过拟合。
🖼️ 关键图片

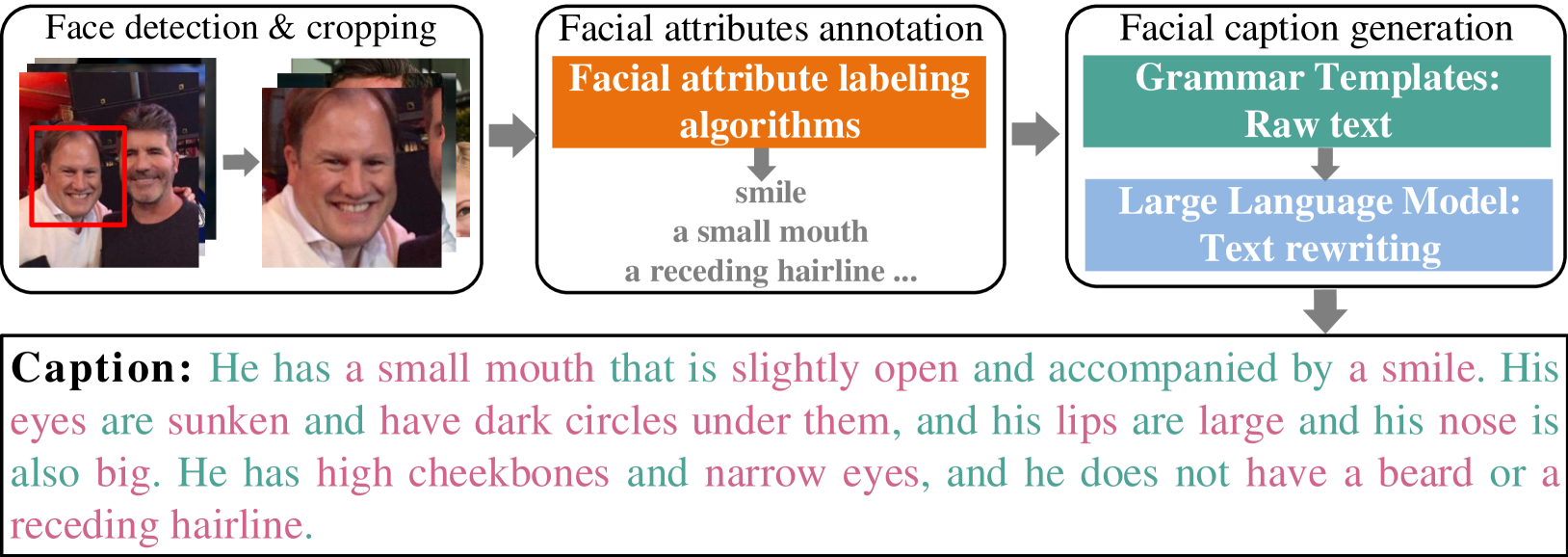

📊 实验亮点
通过在FaceCaption-15M上预训练FLIP模型,并在两个具有挑战性的人脸中心任务上进行微调,仅微调线性层就取得了state-of-the-art的结果。这验证了FaceCaption-15M数据集的有效性,表明该数据集能够有效地提升模型在人脸相关任务上的性能。
🎯 应用场景
FaceCaption-15M数据集可以广泛应用于人脸识别、人脸属性预测、人脸编辑、人脸检索等领域。该数据集的发布将促进多模态深度学习模型在人脸相关任务中的研究和应用,例如,可以用于开发更准确、更鲁棒的人脸识别系统,或者用于生成更逼真的人脸图像。
📄 摘要(原文)
Currently, image-text-driven multi-modal deep learning models have demonstrated their outstanding potential in many fields. In practice, tasks centered around facial images have broad application prospects. This paper presents \textbf{FaceCaption-15M}, a large-scale, diverse, and high-quality dataset of facial images accompanied by their natural language descriptions (facial image-to-text). This dataset aims to facilitate a study on face-centered tasks. FaceCaption-15M comprises over 15 million pairs of facial images and their corresponding natural language descriptions of facial features, making it the largest facial image-caption dataset to date. We conducted a comprehensive analysis of image quality, text naturalness, text complexity, and text-image relevance to demonstrate the superiority of FaceCaption-15M. To validate the effectiveness of FaceCaption-15M, we first trained a facial language-image pre-training model (FLIP, similar to CLIP) to align facial image with its corresponding captions in feature space. Subsequently, using both image and text encoders and fine-tuning only the linear layer, our FLIP-based models achieved state-of-the-art results on two challenging face-centered tasks. The purpose is to promote research in the field of face-related tasks through the availability of the proposed FaceCaption-15M dataset. All data, codes, and models are publicly available. https://huggingface.co/datasets/OpenFace-CQUPT/FaceCaption-15M