MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos
作者: Yushuo Chen, Zerong Zheng, Zhe Li, Chao Xu, Yebin Liu
分类: cs.CV, cs.GR
发布日期: 2024-07-11
备注: Project Page: https://shad0wta9.github.io/meshavatar-page/
💡 一句话要点
MeshAvatar:提出一种从多视角视频学习高质量三角形人像Avatar的新方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人像Avatar 多视角视频 三角形网格 隐式材质场 物理渲染
📋 核心要点
- 现有基于NeRF的Avatar学习方法与传统图形管线不兼容,限制了编辑和环境合成等操作。
- MeshAvatar通过显式三角形网格表示Avatar,并结合隐式材质场和基于物理的渲染,实现几何和纹理的精确分解。
- 实验结果表明,该方法能够学习高质量的三角形Avatar,支持编辑、操作和重新光照等功能。
📝 摘要(中文)
本文提出了一种从多视角视频中学习高质量三角形人像Avatar的新流程。现有Avatar学习方法通常基于神经辐射场(NeRF),这与传统图形管线不兼容,并且对编辑或在不同环境下合成等操作提出了巨大挑战。为了克服这些限制,我们的方法使用从隐式SDF场中提取的显式三角形网格来表示Avatar,并辅以基于给定姿势的隐式材质场。利用这种三角形Avatar表示,我们结合了基于物理的渲染来准确地分解几何体和纹理。为了增强几何和外观细节,我们进一步采用2D UNet作为网络骨干,并引入伪法线真值作为额外的监督。实验表明,我们的方法可以学习具有高质量几何重建和合理的材质分解的三角形Avatar,从而固有地支持编辑、操作或重新光照操作。
🔬 方法详解
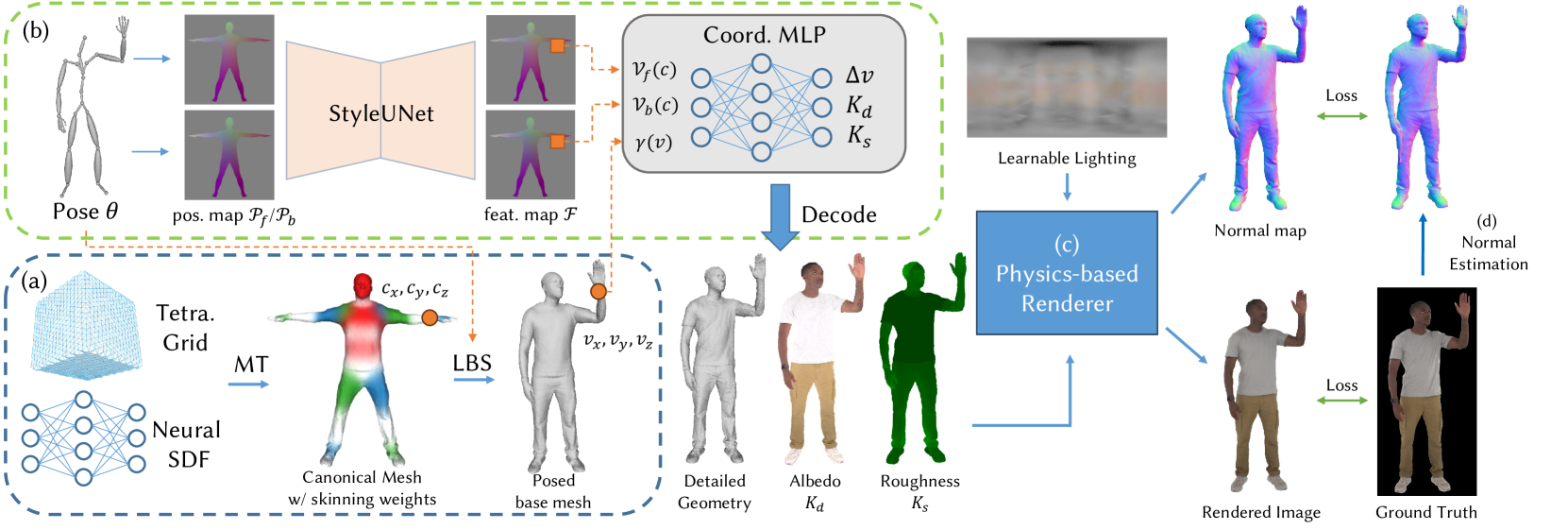
问题定义:现有基于神经辐射场(NeRF)的人像Avatar学习方法虽然取得了显著进展,但其隐式表示方式与传统图形管线不兼容,导致难以进行编辑、操作以及在不同环境下进行合成。因此,如何学习一种既能保持高质量重建效果,又能与传统图形管线兼容的显式Avatar表示是一个关键问题。
核心思路:MeshAvatar的核心思路是使用显式的三角形网格来表示人像Avatar的几何形状,并结合隐式的材质场来描述Avatar的表面属性。通过将几何和材质分离,并利用基于物理的渲染,可以实现更精确的几何重建和材质分解,从而支持各种编辑和操作。
技术框架:MeshAvatar的整体框架包括以下几个主要阶段:1) 从多视角视频中估计隐式SDF场;2) 从SDF场中提取三角形网格;3) 学习基于姿势的隐式材质场;4) 利用基于物理的渲染,将几何和材质信息渲染成图像;5) 使用2D UNet进一步增强几何和外观细节。整个流程通过端到端的方式进行训练。
关键创新:MeshAvatar最重要的创新点在于将显式的三角形网格表示与隐式的材质场相结合,从而克服了NeRF方法的局限性。这种混合表示方式既能保持高质量的重建效果,又能与传统图形管线兼容,从而支持各种编辑和操作。此外,引入伪法线真值作为额外的监督,进一步提升了几何重建的质量。
关键设计:在技术细节方面,MeshAvatar采用了2D UNet作为网络骨干,用于增强几何和外观细节。损失函数包括重建损失、法线损失和正则化损失等。为了更好地分解几何和材质,采用了基于物理的渲染模型。此外,还设计了一种有效的训练策略,以确保模型的收敛性和稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MeshAvatar在人像Avatar重建方面取得了显著的性能提升。与现有的NeRF方法相比,MeshAvatar能够生成更高质量的几何细节和更真实的材质效果。此外,MeshAvatar还支持各种编辑和操作,例如姿势调整、服装更换、光照调整等,为用户提供了更大的创作空间。
🎯 应用场景
MeshAvatar具有广泛的应用前景,包括虚拟现实、增强现实、游戏开发、电影制作等领域。它可以用于创建逼真的人像Avatar,用于虚拟社交、虚拟试穿、角色扮演等应用。此外,MeshAvatar还可以用于人体重建、动作捕捉等研究领域,为相关研究提供高质量的数据和工具。
📄 摘要(原文)
We present a novel pipeline for learning high-quality triangular human avatars from multi-view videos. Recent methods for avatar learning are typically based on neural radiance fields (NeRF), which is not compatible with traditional graphics pipeline and poses great challenges for operations like editing or synthesizing under different environments. To overcome these limitations, our method represents the avatar with an explicit triangular mesh extracted from an implicit SDF field, complemented by an implicit material field conditioned on given poses. Leveraging this triangular avatar representation, we incorporate physics-based rendering to accurately decompose geometry and texture. To enhance both the geometric and appearance details, we further employ a 2D UNet as the network backbone and introduce pseudo normal ground-truth as additional supervision. Experiments show that our method can learn triangular avatars with high-quality geometry reconstruction and plausible material decomposition, inherently supporting editing, manipulation or relighting operations.