DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception
作者: Xiaotong Li, Fan Zhang, Haiwen Diao, Yueze Wang, Xinlong Wang, Ling-Yu Duan
分类: cs.CV, cs.AI
发布日期: 2024-07-11 (更新: 2024-11-24)
备注: Accepted by NeurIPS 2024. Project is available at https://github.com/baaivision/DenseFusion
🔗 代码/项目: GITHUB
💡 一句话要点
提出DenseFusion-1M,融合视觉专家知识,提升多模态大语言模型对图像的全面感知能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉感知 图像描述生成 数据集 感知融合 视觉专家 高分辨率图像
📋 核心要点
- 现有MLLM在理解复杂视觉元素方面面临挑战,缺乏高质量、详细的图像-文本数据集是主要瓶颈。
- 论文提出Perceptual Fusion方法,融合多种视觉专家知识,并利用高效MLLM生成完整准确的图像描述。
- 实验表明,DenseFusion-1M数据集显著提升了现有MLLM在视觉-语言任务中的感知和认知能力,尤其是在高分辨率图像输入下。
📝 摘要(中文)
现有的多模态大型语言模型(MLLM)越来越重视对各种视觉元素的复杂理解,包括多个对象、文本信息和空间关系。它们在全面视觉感知方面的发展取决于高质量图像-文本数据集的可用性,这些数据集提供多样化的视觉元素和全面的图像描述。然而,目前这种超详细数据集的稀缺性阻碍了MLLM社区的进展。瓶颈在于当前字幕引擎的有限感知能力,它们无法提供完整和准确的注释。为了促进MLLM在全面视觉感知方面的尖端研究,我们提出了一种感知融合方法,使用低成本但高效的字幕引擎来生成完整和准确的图像描述。具体来说,感知融合集成了各种感知专家作为图像先验,以提供关于视觉元素的显式信息,并采用高效的MLLM作为中心枢纽来模仿高级MLLM的感知能力。我们从未经整理的LAION数据集中精心挑选了100万张具有高度代表性的图像,并使用我们的引擎生成了密集的描述,称为DenseFusion-1M。广泛的实验验证了我们的引擎优于同类引擎,由此产生的数据集显著提高了现有MLLM在各种视觉-语言基准测试中的感知和认知能力,尤其是在以高分辨率图像作为输入时。数据集和代码可在https://github.com/baaivision/DenseFusion公开获取。
🔬 方法详解
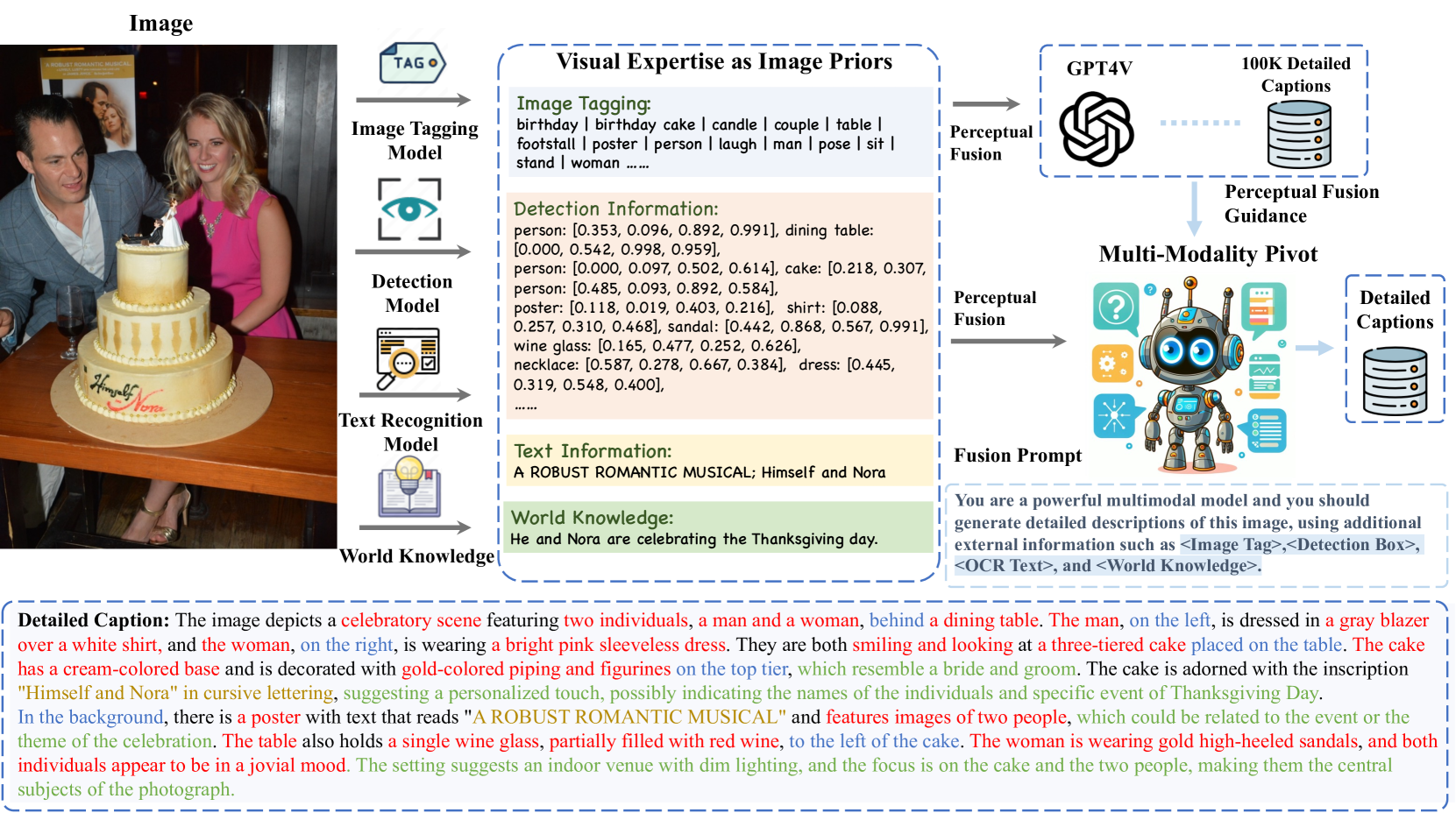
问题定义:现有MLLM在理解复杂视觉场景时,依赖于高质量的图像-文本数据集。然而,现有的caption引擎生成的描述不够完整和准确,无法满足MLLM对细粒度视觉信息的需求,限制了MLLM在全面视觉感知方面的研究进展。
核心思路:论文的核心思路是利用Perceptual Fusion方法,融合多个视觉专家的知识,生成更全面、更准确的图像描述。通过将不同视觉专家的输出作为图像的先验信息,并结合高效的MLLM,从而提升caption引擎的感知能力。
技术框架:DenseFusion-1M的生成流程主要包括以下几个阶段:1) 从LAION数据集中选择具有代表性的图像;2) 利用多个视觉专家(例如,目标检测器、文本识别器等)提取图像中的视觉元素信息;3) 将这些视觉元素信息作为先验知识输入到高效的MLLM中;4) MLLM生成最终的图像描述。
关键创新:该方法的关键创新在于Perceptual Fusion的思想,即通过融合多个视觉专家的知识,弥补单个caption引擎的不足。这种方法能够生成更全面、更准确的图像描述,从而提升MLLM的视觉感知能力。与传统的caption引擎相比,DenseFusion-1M能够提供更丰富的视觉信息,例如,图像中包含的多个对象、文本信息以及它们之间的空间关系。
关键设计:在DenseFusion-1M的生成过程中,关键的设计包括:1) 如何选择合适的视觉专家;2) 如何有效地融合不同视觉专家的输出;3) 如何选择和训练高效的MLLM。论文中提到选择了100万张具有代表性的图像,但关于具体的专家选择、融合方式以及MLLM的训练细节,论文中没有详细说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用DenseFusion-1M数据集训练的MLLM在多个视觉-语言基准测试中取得了显著的性能提升。尤其是在高分辨率图像输入下,MLLM的感知和认知能力得到了大幅提高。具体的数据提升幅度未知,但论文强调了DenseFusion-1M数据集的有效性。
🎯 应用场景
该研究成果可广泛应用于多模态大语言模型的训练和评估,尤其是在需要对图像进行细粒度理解的任务中,例如视觉问答、图像描述生成、图像检索等。DenseFusion-1M数据集的发布将促进MLLM社区在全面视觉感知方面的研究,并推动相关技术的进步。未来,该方法可以扩展到其他模态的数据,例如视频和音频,从而实现更全面的多模态感知。
📄 摘要(原文)
Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, and spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The dataset and code are publicly available at https://github.com/baaivision/DenseFusion.