MambaVision: A Hybrid Mamba-Transformer Vision Backbone
作者: Ali Hatamizadeh, Jan Kautz
分类: cs.CV
发布日期: 2024-07-10 (更新: 2025-03-25)
备注: Accepted to CVPR'25
🔗 代码/项目: GITHUB
💡 一句话要点
MambaVision:一种混合Mamba-Transformer视觉骨干网络,提升视觉特征建模效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉骨干网络 Mamba架构 Transformer 自注意力机制 图像分类 目标检测 语义分割 长程依赖建模
📋 核心要点
- 现有视觉模型在长程依赖建模和计算效率上存在挑战,限制了其在资源受限场景下的应用。
- MambaVision通过重新设计Mamba公式并融合Transformer的自注意力机制,提升视觉特征建模效率和长程依赖捕获能力。
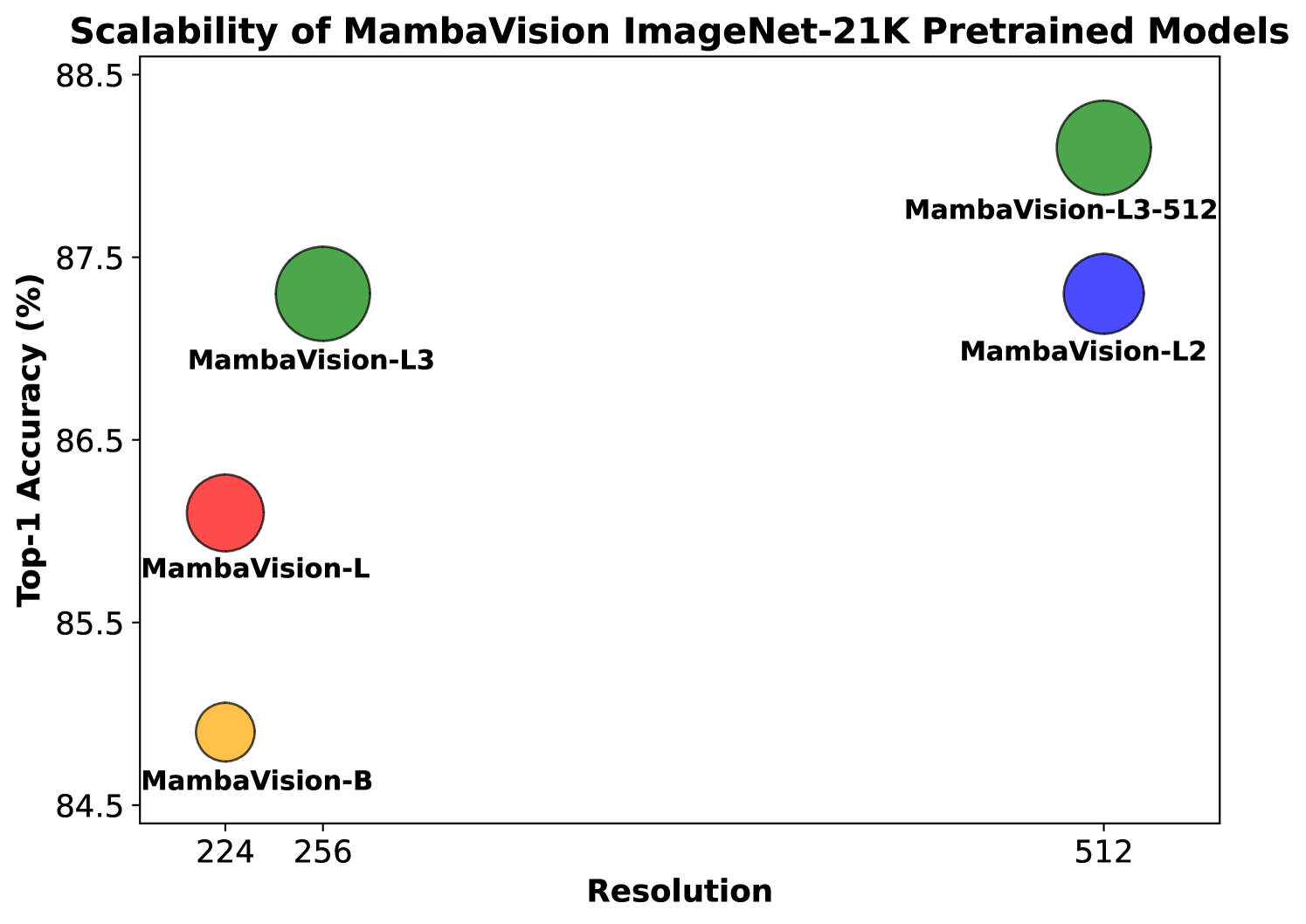
- 实验结果表明,MambaVision在ImageNet-1K分类任务和下游分割、检测任务中均取得了优异的性能,并具有更高的吞吐量。
📝 摘要(中文)
本文提出了一种新颖的混合Mamba-Transformer骨干网络,名为MambaVision,专门为视觉应用量身定制。核心贡献在于重新设计了Mamba公式,以增强其对视觉特征进行高效建模的能力。通过全面的消融研究,证明了将Vision Transformers (ViT)与Mamba集成的可行性。结果表明,在Mamba架构的最后几层配备自注意力模块,可以极大地提高其捕获长程空间依赖关系的能力。基于这些发现,我们引入了一系列具有分层架构的MambaVision模型,以满足各种设计标准。在ImageNet-1K数据集上的分类任务中,MambaVision变体在Top-1准确率和吞吐量方面均实现了最先进的(SOTA)性能。在MS COCO和ADE20K数据集上的目标检测、实例分割和语义分割等下游任务中,MambaVision优于同等规模的骨干网络,并表现出良好的性能。代码已开源。
🔬 方法详解
问题定义:现有视觉Transformer模型,如ViT,在处理高分辨率图像时计算复杂度较高,难以有效建模长程依赖关系。而Mamba架构虽然在序列建模上表现出色,但直接应用于视觉任务时,对视觉特征的建模能力仍有提升空间。因此,需要一种既能高效处理视觉信息,又能有效建模长程依赖关系的视觉骨干网络。
核心思路:MambaVision的核心思路是将Mamba架构与Transformer的自注意力机制相结合,取长补短。利用Mamba的高效序列建模能力处理大部分视觉信息,并在关键层引入自注意力机制来增强长程依赖的建模能力。通过这种混合架构,在计算效率和模型性能之间取得平衡。
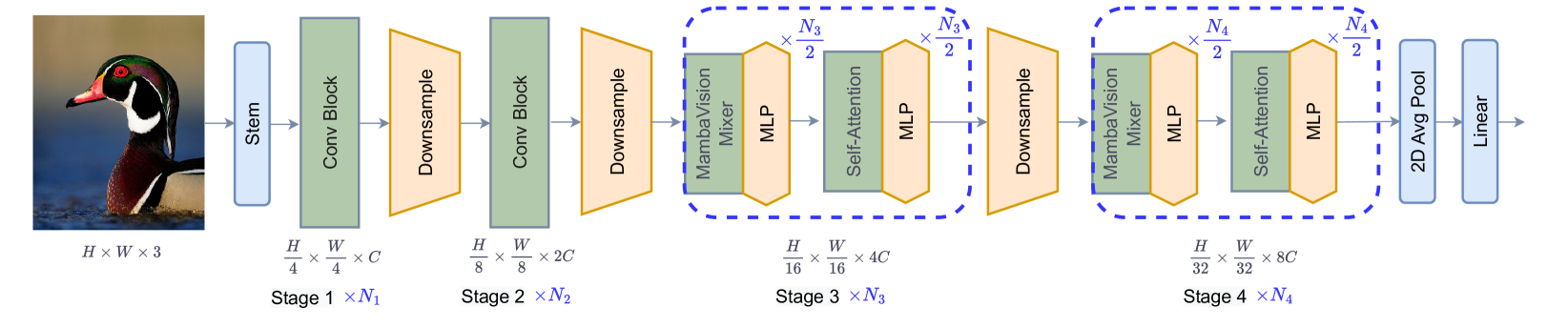
技术框架:MambaVision采用分层架构,类似于常见的视觉Transformer。整体流程包括:输入图像经过初始的patch embedding层,然后进入多个Mamba块进行特征提取。在网络的最后几层,引入自注意力模块(Transformer块)来增强全局上下文信息的建模。最后,通过分类头或下游任务相关的模块进行预测。
关键创新:MambaVision的关键创新在于混合架构的设计,以及对Mamba公式的重新设计,使其更适合视觉任务。具体来说,通过消融实验确定了自注意力模块的最佳位置和数量,从而在性能和效率之间找到最佳平衡点。此外,可能还对Mamba块的内部结构进行了调整,以更好地适应视觉特征的特性。
关键设计:具体的技术细节可能包括:Mamba块的具体实现方式(例如,状态空间模型的参数设置、选择机制的实现等),自注意力模块的层数和维度,以及损失函数的设计。此外,patch embedding的大小、Mamba块和Transformer块的堆叠方式等也都是重要的设计参数。具体的参数设置和网络结构需要参考论文的详细描述。
🖼️ 关键图片

📊 实验亮点
MambaVision在ImageNet-1K图像分类任务上取得了SOTA的Top-1准确率,同时具有更高的吞吐量。在MS COCO和ADE20K数据集上的目标检测、实例分割和语义分割等下游任务中,MambaVision也优于同等规模的骨干网络,展现了其强大的泛化能力和高效性。
🎯 应用场景
MambaVision具有广泛的应用前景,可应用于图像分类、目标检测、语义分割等多种视觉任务。其高效的计算特性使其在资源受限的移动设备或边缘计算场景中具有优势。此外,该研究为设计更高效的视觉骨干网络提供了新的思路,有望推动计算机视觉领域的发展。
📄 摘要(原文)
We propose a novel hybrid Mamba-Transformer backbone, MambaVision, specifically tailored for vision applications. Our core contribution includes redesigning the Mamba formulation to enhance its capability for efficient modeling of visual features. Through a comprehensive ablation study, we demonstrate the feasibility of integrating Vision Transformers (ViT) with Mamba. Our results show that equipping the Mamba architecture with self-attention blocks in the final layers greatly improves its capacity to capture long-range spatial dependencies. Based on these findings, we introduce a family of MambaVision models with a hierarchical architecture to meet various design criteria. For classification on the ImageNet-1K dataset, MambaVision variants achieve state-of-the-art (SOTA) performance in terms of both Top-1 accuracy and throughput. In downstream tasks such as object detection, instance segmentation, and semantic segmentation on MS COCO and ADE20K datasets, MambaVision outperforms comparably sized backbones while demonstrating favorable performance. Code: https://github.com/NVlabs/MambaVision