LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
作者: Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, Chunyuan Li
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-07-10 (更新: 2024-07-28)
备注: Project Page: https://llava-vl.github.io/blog/2024-06-16-llava-next-interleave/
🔗 代码/项目: GITHUB
💡 一句话要点
LLaVA-NeXT-Interleave:统一处理多图、视频和3D场景的大型多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉指令调优 多图像处理 视频理解 3D场景理解 跨模态迁移 大型多模态模型
📋 核心要点
- 现有大型多模态模型主要关注单图像任务,缺乏对多图像、视频和3D等复杂场景的统一处理能力。
- LLaVA-NeXT-Interleave将交错数据格式作为通用模板,统一处理多图像、视频和3D等多模态数据。
- 实验表明,LLaVA-NeXT-Interleave在多图像、视频和3D基准测试中表现出色,并具备跨模态任务迁移能力。
📝 摘要(中文)
视觉指令调优在提升大型多模态模型(LMMs)的能力方面取得了显著进展。然而,现有的开源LMMs主要集中于单图像任务,它们在多图像场景中的应用仍有待探索。此外,先前的LMM研究分别处理不同的场景,无法推广到具有新兴能力的跨场景应用。为此,我们推出了LLaVA-NeXT-Interleave,它同时处理LMM中的多图像、多帧(视频)、多视角(3D)和多块(单图像)场景。为了实现这些能力,我们将交错数据格式视为通用模板,并编译了包含1177.6k个样本的M4-Instruct数据集,涵盖4个主要领域,包含14个任务和41个数据集。我们还策划了LLaVA-Interleave Bench,以全面评估LMMs的多图像性能。通过广泛的实验,LLaVA-NeXT-Interleave在多图像、视频和3D基准测试中取得了领先的结果,同时保持了单图像任务的性能。此外,我们的模型还展示了一些新兴能力,例如,在不同设置和模态之间转移任务。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在处理多图像、视频和3D等多模态数据时存在局限性。它们通常针对特定模态或任务进行优化,缺乏通用性和跨模态迁移能力。此外,缺乏统一的数据格式和训练方法来支持多种模态的联合学习。
核心思路:LLaVA-NeXT-Interleave的核心思路是将各种模态的数据(多图像、视频帧、3D视角等)统一表示为交错的数据格式。通过将不同模态的数据交织在一起,模型可以学习到它们之间的关联性,从而实现跨模态的理解和推理。这种方法将多模态学习问题转化为一个统一的序列预测问题。
技术框架:LLaVA-NeXT-Interleave的整体框架基于LLaVA-NeXT架构,并进行了扩展以支持交错数据格式。该框架包含以下主要模块:1) 视觉编码器:用于提取图像、视频帧和3D数据的视觉特征。2) 文本编码器:用于编码文本指令和问题。3) 多模态连接器:用于将视觉特征和文本特征融合在一起。4) 解码器:用于生成文本回复。训练过程中,模型使用M4-Instruct数据集进行视觉指令调优。
关键创新:LLaVA-NeXT-Interleave最重要的技术创新点在于其统一的交错数据格式。这种格式使得模型能够同时处理多种模态的数据,并学习到它们之间的关联性。此外,该模型还展示了跨模态任务迁移能力,即在一个模态上训练的模型可以泛化到其他模态上。
关键设计:M4-Instruct数据集是关键设计之一,它包含了1177.6k个样本,涵盖4个主要领域(多图像、视频、3D和单图像),包含14个任务和41个数据集。损失函数采用标准的交叉熵损失函数,用于优化模型的文本生成能力。视觉编码器和文本编码器采用预训练的模型,例如CLIP和LLaMA,并进行微调。
🖼️ 关键图片

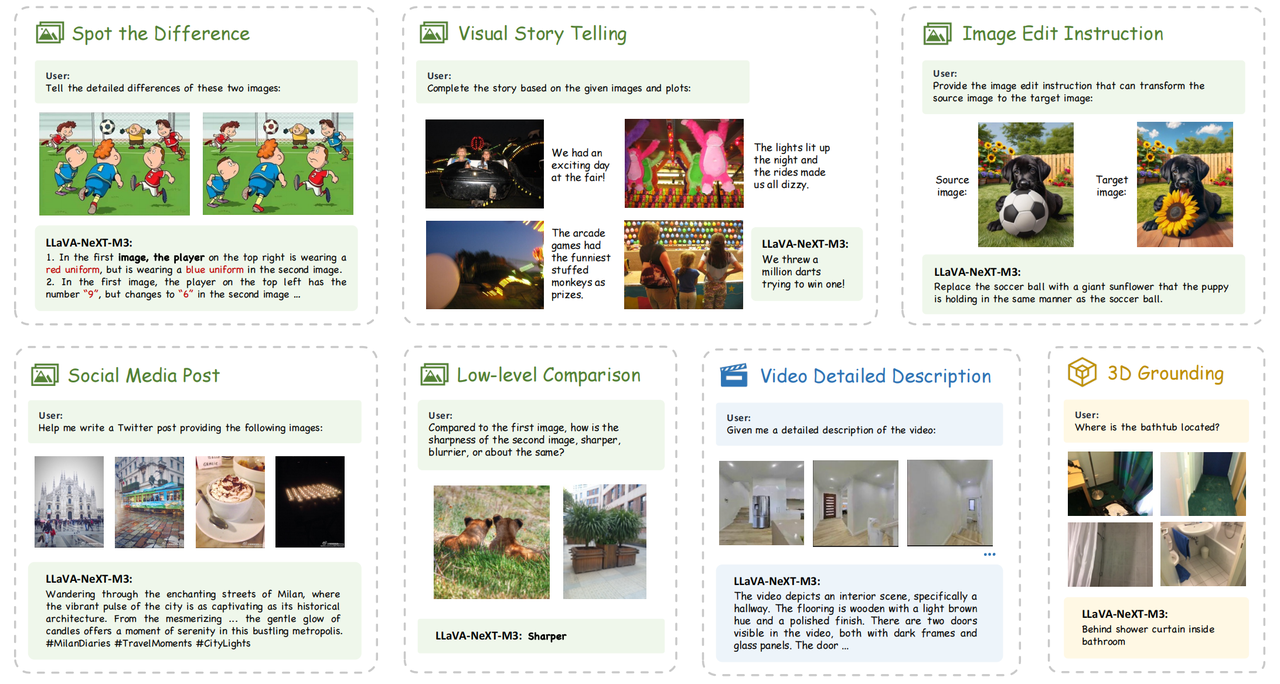
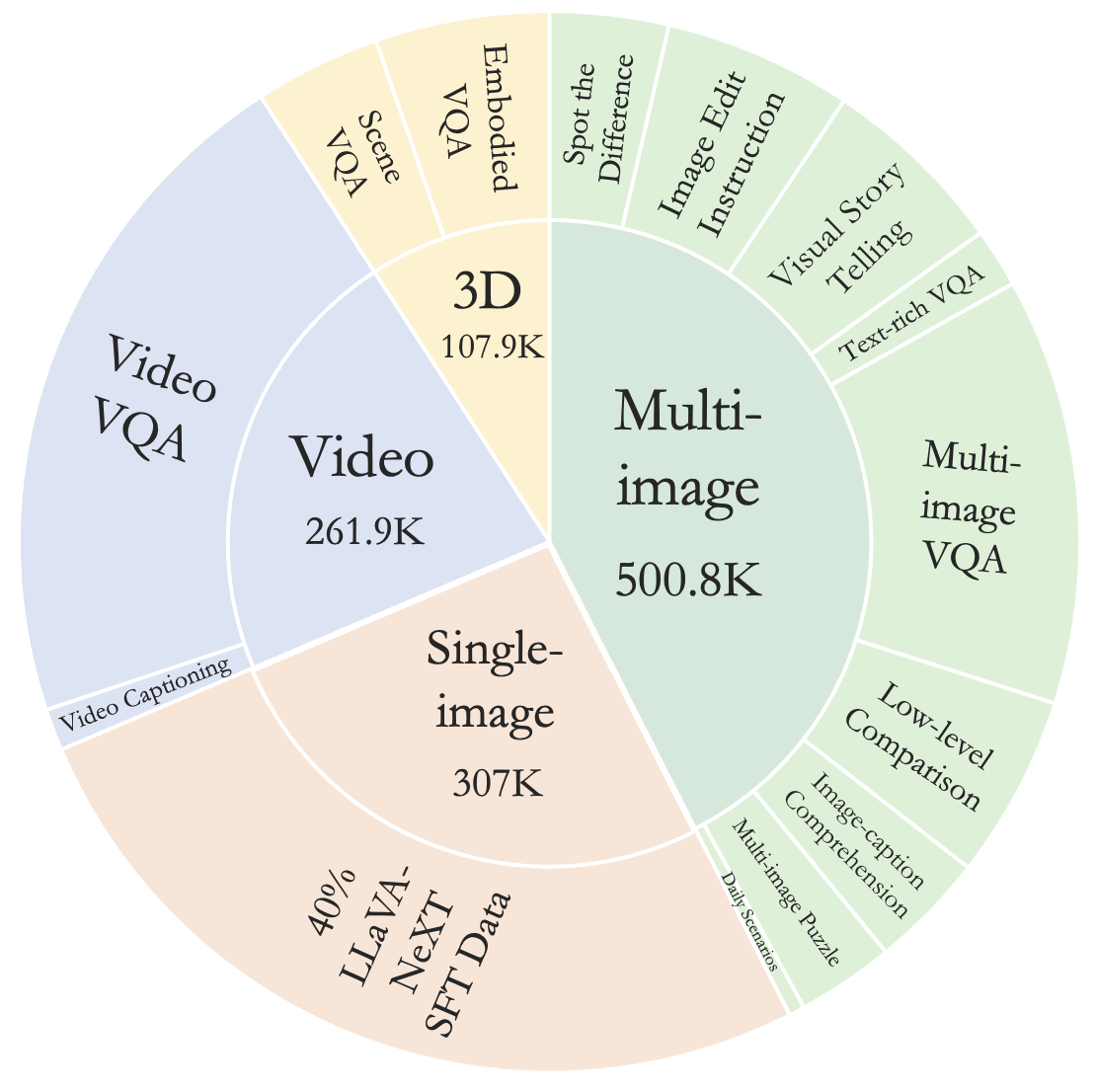
📊 实验亮点
LLaVA-NeXT-Interleave在多图像、视频和3D基准测试中取得了领先的结果,例如在LLaVA-Interleave Bench上取得了显著的性能提升。此外,该模型还展示了跨模态任务迁移能力,例如在视频问答任务上,使用在图像问答任务上训练的模型可以取得良好的性能。
🎯 应用场景
LLaVA-NeXT-Interleave具有广泛的应用前景,例如智能视频分析、3D场景理解、多图像内容生成等。它可以应用于自动驾驶、机器人导航、医疗影像分析等领域,帮助机器更好地理解和处理复杂的多模态数据,从而实现更智能化的应用。
📄 摘要(原文)
Visual instruction tuning has made considerable strides in enhancing the capabilities of Large Multimodal Models (LMMs). However, existing open LMMs largely focus on single-image tasks, their applications to multi-image scenarios remains less explored. Additionally, prior LMM research separately tackles different scenarios, leaving it impossible to generalize cross scenarios with new emerging capabilities. To this end, we introduce LLaVA-NeXT-Interleave, which simultaneously tackles Multi-image, Multi-frame (video), Multi-view (3D), and Multi-patch (single-image) scenarios in LMMs. To enable these capabilities, we regard the interleaved data format as a general template and compile the M4-Instruct dataset with 1,177.6k samples, spanning 4 primary domains with 14 tasks and 41 datasets. We also curate the LLaVA-Interleave Bench to comprehensively evaluate the multi-image performance of LMMs. Through extensive experiments, LLaVA-NeXT-Interleave achieves leading results in multi-image, video, and 3D benchmarks, while maintaining the performance of single-image tasks. Besides, our model also exhibits several emerging capabilities, e.g., transferring tasks across different settings and modalities. Code is available at https://github.com/LLaVA-VL/LLaVA-NeXT