Simplifying Source-Free Domain Adaptation for Object Detection: Effective Self-Training Strategies and Performance Insights
作者: Yan Hao, Florent Forest, Olga Fink
分类: cs.CV, cs.LG
发布日期: 2024-07-10
备注: Accepted at ECCV 2024. 19 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出简单有效的自训练策略,显著提升无源域目标检测的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 无源域自适应 目标检测 自训练 Mean Teacher 伪标签
📋 核心要点
- 无源域目标检测旨在解决目标域无标注数据,源域数据可用的情况下的模型泛化问题,现有方法通常复杂且效果提升有限。
- 论文核心在于探索更简单的自训练策略,通过调整批归一化统计量和使用强-弱增强的Mean Teacher模型,实现高效的领域自适应。
- 实验表明,提出的SF-UT方法和基于固定伪标签的训练策略,在多个数据集上超越了现有复杂的SFOD方法,并在Cityscapes→Foggy-Cityscapes上实现了4.7% AP50的提升。
📝 摘要(中文)
本文关注计算机视觉中的无源域目标检测问题。由于为每个新领域获取带标注的数据集成本高昂,这项任务具有挑战性和重要的实际意义。最近的研究提出了各种无源域目标检测(SFOD)的解决方案,其中大多数是具有不同特征对齐、正则化和伪标签选择策略的教师-学生架构的变体。我们的工作研究了更简单的方法,并将其性能与几种适应场景中更复杂的SFOD方法进行了比较。我们强调了检测器骨干网络中批归一化层的重要性,并表明仅调整批统计量是SFOD的一个强基线。我们提出了一个简单的Mean Teacher扩展,在无源设置中使用强-弱增强,即无偏教师(SF-UT),并表明它实际上优于以前的大多数SFOD方法。此外,我们展示了一种更简单的策略,即在固定的伪标签集上进行训练,可以实现与更复杂的教师-学生互学习相似的性能,同时具有计算效率并减轻了教师-学生崩溃的主要问题。我们使用包括(Foggy)Cityscapes、Sim10k和KITTI在内的基准驾驶数据集,在多个适应任务上进行了实验,并且与最新的SFOD技术相比,在Cityscapes→Foggy-Cityscapes上实现了4.7% AP50的显著提升。源代码可在https://github.com/EPFL-IMOS/simple-SFOD获得。
🔬 方法详解
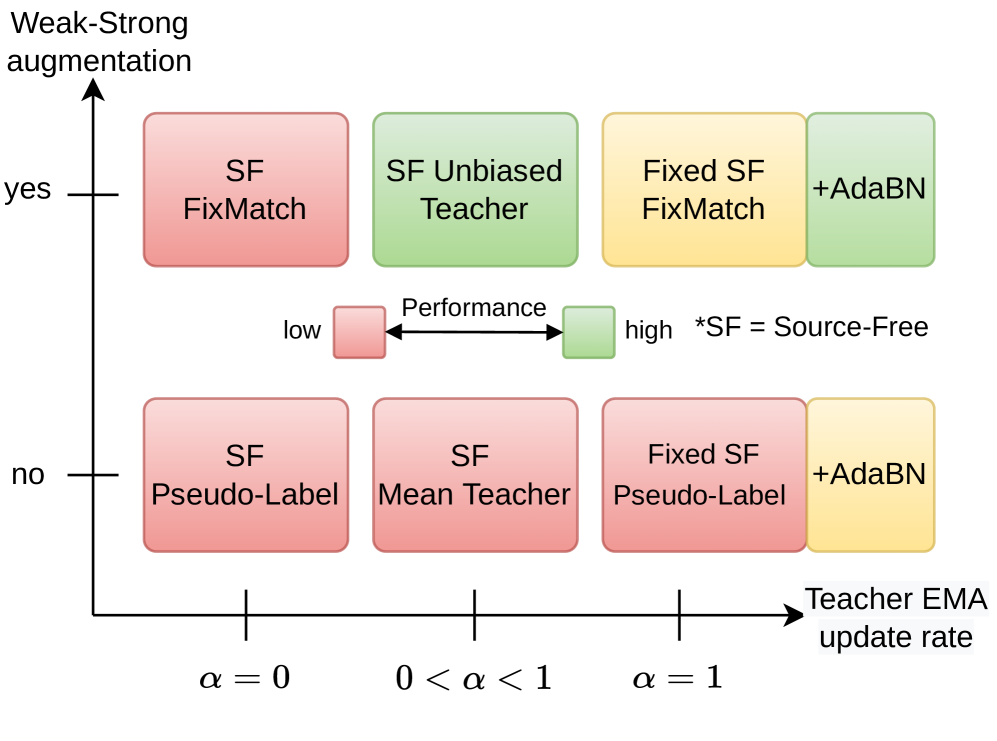
问题定义:论文旨在解决无源域目标检测(SFOD)问题,即在只有源域数据(带标注)和目标域数据(无标注)的情况下,训练一个在目标域上表现良好的目标检测器。现有SFOD方法通常采用复杂的教师-学生架构,涉及特征对齐、正则化和伪标签选择等策略,计算成本高昂,且效果提升有限。这些方法往往忽略了批归一化层的重要性,并且容易出现教师-学生模型崩溃的问题。
核心思路:论文的核心思路是探索更简单有效的自训练策略,以实现高效的SFOD。作者认为,批归一化层在领域自适应中起着关键作用,并且简单的Mean Teacher模型结合强-弱增强可以作为强大的基线。此外,作者还提出了一种基于固定伪标签的训练策略,以避免教师-学生模型崩溃的问题。
技术框架:论文主要提出了两种方法:1) Source-Free Unbiased Teacher (SF-UT):这是一种基于Mean Teacher模型的扩展,使用强-弱增强策略来生成更可靠的伪标签。2) 基于固定伪标签的训练策略:首先使用源域模型在目标域上生成伪标签,然后使用这些固定的伪标签来训练目标检测器。整体流程包括:源域模型训练 -> 目标域伪标签生成(可选) -> 目标域自训练。
关键创新:论文的关键创新在于:1) 强调了批归一化层在SFOD中的重要性,并证明仅调整批统计量即可作为强大的基线。2) 提出了简单有效的SF-UT方法,该方法优于现有复杂的SFOD方法。3) 提出了一种基于固定伪标签的训练策略,该策略可以避免教师-学生模型崩溃的问题,并且具有计算效率。
关键设计:SF-UT方法的关键设计在于使用强-弱增强策略来生成更可靠的伪标签。强增强用于学生模型,弱增强用于教师模型。损失函数通常采用标准的监督学习损失函数,例如交叉熵损失和Smooth L1损失。基于固定伪标签的训练策略的关键设计在于如何生成高质量的伪标签,这可以通过调整源域模型的置信度阈值来实现。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的SF-UT方法在Cityscapes→Foggy-Cityscapes上实现了4.7% AP50的显著提升,超越了现有的SOTA方法。此外,基于固定伪标签的训练策略也取得了与复杂教师-学生互学习方法相似的性能,同时具有更高的计算效率。这些结果表明,简单的自训练策略在SFOD中具有巨大的潜力。
🎯 应用场景
该研究成果可广泛应用于自动驾驶、智能监控、机器人等领域,尤其是在难以获取标注数据的场景下。例如,在自动驾驶中,可以利用该方法将模型从模拟环境迁移到真实环境,或者从一个城市迁移到另一个城市,而无需重新标注数据。该研究有助于降低模型部署成本,提高模型的泛化能力。
📄 摘要(原文)
This paper focuses on source-free domain adaptation for object detection in computer vision. This task is challenging and of great practical interest, due to the cost of obtaining annotated data sets for every new domain. Recent research has proposed various solutions for Source-Free Object Detection (SFOD), most being variations of teacher-student architectures with diverse feature alignment, regularization and pseudo-label selection strategies. Our work investigates simpler approaches and their performance compared to more complex SFOD methods in several adaptation scenarios. We highlight the importance of batch normalization layers in the detector backbone, and show that adapting only the batch statistics is a strong baseline for SFOD. We propose a simple extension of a Mean Teacher with strong-weak augmentation in the source-free setting, Source-Free Unbiased Teacher (SF-UT), and show that it actually outperforms most of the previous SFOD methods. Additionally, we showcase that an even simpler strategy consisting in training on a fixed set of pseudo-labels can achieve similar performance to the more complex teacher-student mutual learning, while being computationally efficient and mitigating the major issue of teacher-student collapse. We conduct experiments on several adaptation tasks using benchmark driving datasets including (Foggy)Cityscapes, Sim10k and KITTI, and achieve a notable improvement of 4.7\% AP50 on Cityscapes$\rightarrow$Foggy-Cityscapes compared with the latest state-of-the-art in SFOD. Source code is available at https://github.com/EPFL-IMOS/simple-SFOD.