Swiss DINO: Efficient and Versatile Vision Framework for On-device Personal Object Search
作者: Kirill Paramonov, Jia-Xing Zhong, Umberto Michieli, Jijoong Moon, Mete Ozay
分类: cs.CV, cs.AI, cs.RO
发布日期: 2024-07-10
备注: 8 pages, 2 figures, accepted to IROS2024
💡 一句话要点
Swiss DINO:高效且通用的设备端个人物体搜索视觉框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 个人物体搜索 设备端视觉 DINOv2 零样本学习 机器人视觉
📋 核心要点
- 现有小样本学习方法难以满足设备端资源限制,且难以区分细粒度类别,尤其是在遮挡和杂乱场景下。
- Swiss DINO利用DINOv2的强大零样本泛化能力,无需额外训练即可实现设备端个人物体搜索。
- 实验表明,Swiss DINO在分割和识别精度上显著优于轻量级方案,且大幅降低了推理时间和GPU消耗。
📝 摘要(中文)
本文提出了一种针对机器人家用电器中视觉系统的新趋势,即能够动态地个性化设备。特别地,我们定义并解决了一个重要的技术任务:个人物体搜索,该任务涉及在机器人电器拍摄的图像中定位和识别感兴趣的个人物品,每个物品仅由少量带注释的图像引用。该任务对于需要处理个人视觉场景或操作特定个人物品(例如,用于抓取或导航)的机器人家用电器和移动系统至关重要。实际上,个人物体搜索提出了两个主要的技术挑战。首先,机器人视觉系统需要能够在存在遮挡和杂乱的情况下区分许多细粒度的类别。其次,设备端系统的严格资源要求限制了大多数最先进的小样本学习方法的使用,并且通常阻止了设备端自适应。在这项工作中,我们提出了Swiss DINO:一个简单而有效的基于DINOv2 Transformer模型的单样本个人物体搜索框架,该模型已被证明具有强大的零样本泛化性能。Swiss DINO处理了具有挑战性的设备端个性化场景理解要求,并且不需要任何自适应训练。与常见的轻量级解决方案相比,我们在分割和识别精度方面显示出显着提高(高达55%),并且与基于Transformer的重型解决方案相比,骨干网络推理时间和GPU消耗显着降低(高达100倍)。
🔬 方法详解
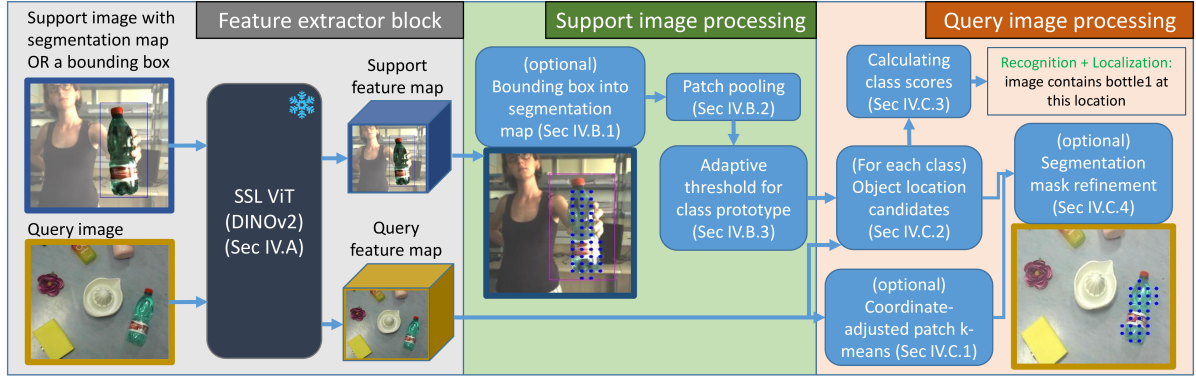
问题定义:论文旨在解决机器人设备端个人物体搜索问题,即在资源受限的条件下,仅使用少量带标注的图像,在复杂场景中定位和识别用户感兴趣的特定物体。现有方法,特别是基于深度学习的小样本学习方法,通常计算量大,难以部署在资源有限的设备上,并且在遮挡和杂乱场景下的细粒度物体识别性能不佳。
核心思路:论文的核心思路是利用预训练的DINOv2模型的强大零样本泛化能力,避免在设备端进行耗时的训练或微调。DINOv2在大量无标注数据上进行自监督学习,学习到了丰富的视觉特征表示,可以直接用于下游任务,而无需针对特定任务进行优化。通过利用DINOv2的特征,可以有效地进行单样本物体搜索。
技术框架:Swiss DINO框架主要包含以下几个阶段:1) 使用DINOv2提取输入图像和参考图像的视觉特征。2) 利用提取的特征进行相似度匹配,确定目标物体在输入图像中的位置。3) 使用分割算法对目标物体进行分割。整个流程无需额外的训练或微调,可以直接在设备端部署。
关键创新:该论文的关键创新在于将DINOv2模型应用于设备端个人物体搜索任务,并证明了其在资源受限环境下的有效性。与传统的基于微调或元学习的小样本学习方法相比,Swiss DINO无需训练,大大降低了计算成本和部署难度。此外,Swiss DINO在分割和识别精度方面也取得了显著的提升。
关键设计:Swiss DINO的关键设计包括:1) 选择DINOv2作为特征提取器,利用其强大的零样本泛化能力。2) 使用简单的相似度匹配算法进行物体定位,避免复杂的模型训练。3) 采用轻量级的分割算法进行物体分割,保证设备端的实时性。具体参数设置和损失函数细节未在摘要中详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
Swiss DINO在个人物体搜索任务中取得了显著的性能提升。与常见的轻量级解决方案相比,分割和识别精度提高了高达55%。同时,与基于Transformer的重型解决方案相比,骨干网络推理时间降低了高达100倍,GPU消耗降低了高达10倍。这些结果表明,Swiss DINO在精度和效率方面都具有显著优势。
🎯 应用场景
该研究成果可广泛应用于智能家居、机器人、可穿戴设备等领域。例如,智能扫地机器人可以根据用户提供的少量图片识别特定的玩具或宠物,并避开它们。智能眼镜可以帮助用户快速定位和识别周围的物品。这些应用可以提升用户体验,并使设备更加智能化和个性化。
📄 摘要(原文)
In this paper, we address a recent trend in robotic home appliances to include vision systems on personal devices, capable of personalizing the appliances on the fly. In particular, we formulate and address an important technical task of personal object search, which involves localization and identification of personal items of interest on images captured by robotic appliances, with each item referenced only by a few annotated images. The task is crucial for robotic home appliances and mobile systems, which need to process personal visual scenes or to operate with particular personal objects (e.g., for grasping or navigation). In practice, personal object search presents two main technical challenges. First, a robot vision system needs to be able to distinguish between many fine-grained classes, in the presence of occlusions and clutter. Second, the strict resource requirements for the on-device system restrict the usage of most state-of-the-art methods for few-shot learning and often prevent on-device adaptation. In this work, we propose Swiss DINO: a simple yet effective framework for one-shot personal object search based on the recent DINOv2 transformer model, which was shown to have strong zero-shot generalization properties. Swiss DINO handles challenging on-device personalized scene understanding requirements and does not require any adaptation training. We show significant improvement (up to 55%) in segmentation and recognition accuracy compared to the common lightweight solutions, and significant footprint reduction of backbone inference time (up to 100x) and GPU consumption (up to 10x) compared to the heavy transformer-based solutions.