Pseudo-RIS: Distinctive Pseudo-supervision Generation for Referring Image Segmentation
作者: Seonghoon Yu, Paul Hongsuck Seo, Jeany Son
分类: cs.CV, cs.AI
发布日期: 2024-07-10 (更新: 2024-07-17)
备注: Accepted to ECCV 2024
💡 一句话要点
提出伪RIS框架以解决图像分割中的伪监督生成问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像分割 伪监督学习 深度学习 自然语言处理 半监督学习
📋 核心要点
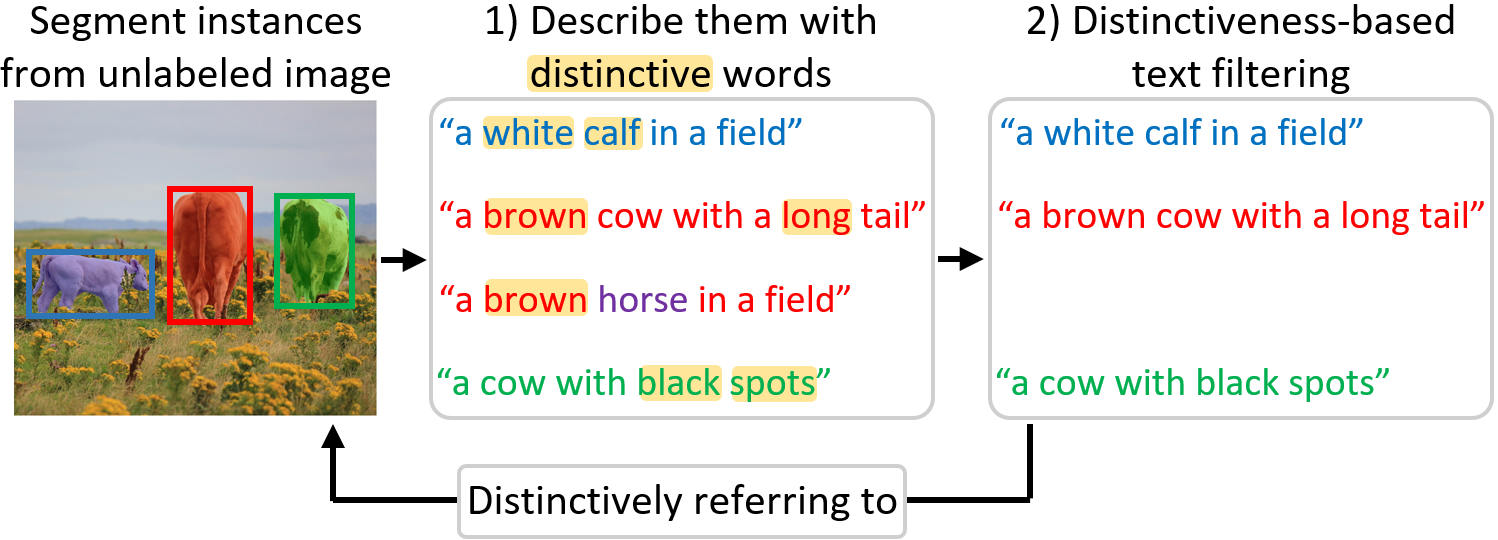
- 现有的图像分割方法在生成伪监督时常面临表达不具区分性的问题,导致训练效果不佳。
- 本文提出的伪RIS框架通过结合分割和图像描述模型,生成高质量的伪监督表达,提升了图像分割的准确性。
- 实验结果表明,该方法在多个基准数据集上显著优于现有的弱监督和零样本方法,且在未见领域中表现出色。
📝 摘要(中文)
本文提出了一种新框架,自动生成高质量的分割掩码及其对应的伪监督表达,用于图像分割任务。这些伪监督使得任何监督的图像分割方法在无需人工标注的情况下进行训练。为此,作者结合了现有的分割和图像描述基础模型,利用其广泛的泛化能力。然而,简单地结合这些模型可能会生成不具区分性的表达。为了解决这一挑战,提出了两种策略:1)'区分性描述采样',一种新的解码方法,生成多个关注目标的详细表达候选;2)'基于区分性的文本过滤',进一步验证候选并过滤掉低区分性的表达。这两种策略确保生成的文本监督能够有效区分目标与其他对象,使其适用于图像分割注释。该方法在图像分割基准数据集上显著超越了弱监督和零样本的最新方法,并在未见领域中超越了完全监督的方法,证明了其在开放世界挑战中的能力。
🔬 方法详解
问题定义:本文旨在解决图像分割任务中伪监督生成的低区分性问题。现有方法在生成描述时,往往无法有效区分目标与其他对象,影响训练效果。
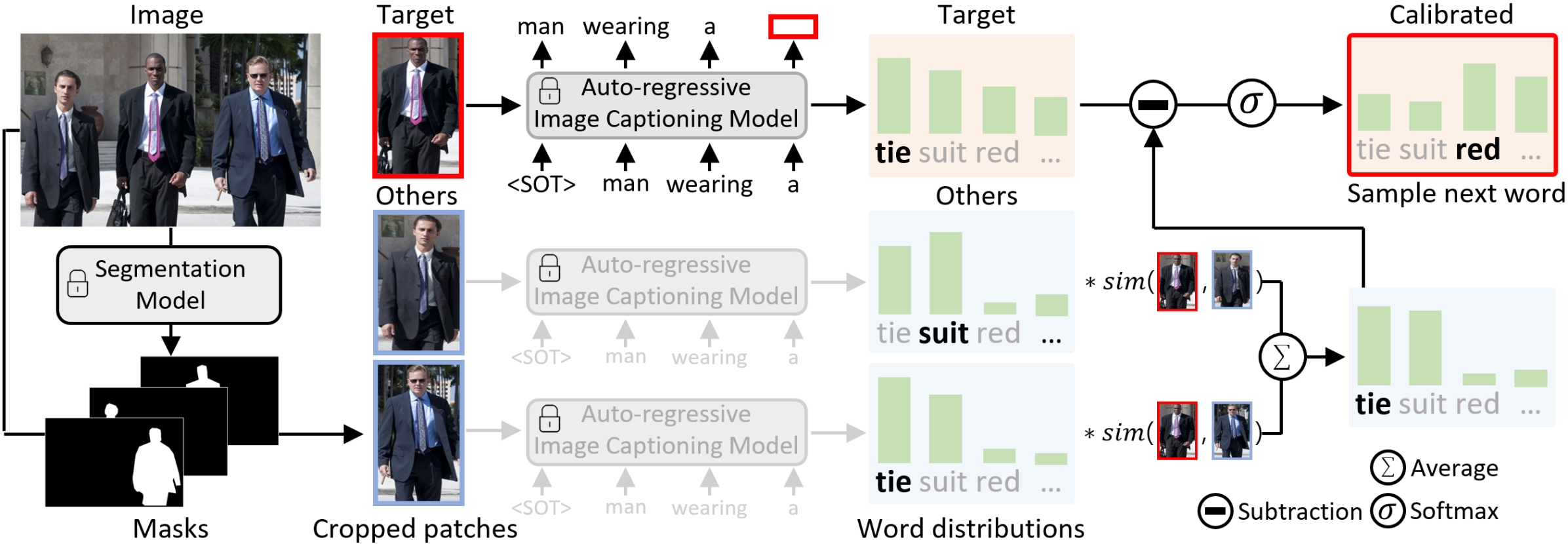
核心思路:论文提出通过结合现有的分割和图像描述模型,生成高质量的伪监督表达。通过引入区分性描述采样和基于区分性的文本过滤,确保生成的描述能够准确指向目标。
技术框架:整体框架包括两个主要模块:1)描述生成模块,利用改进的解码方法生成多个表达候选;2)文本过滤模块,通过评估候选的区分性,筛选出有效的描述。
关键创新:最重要的创新在于提出了区分性描述采样和基于区分性的文本过滤策略。这些策略确保生成的文本能够有效区分目标与其他对象,与现有方法相比,显著提升了伪监督的质量。
关键设计:在描述生成模块中,采用了新的解码策略以生成多样化的表达候选;在文本过滤模块中,设计了特定的评估标准,以确保候选的区分性达到预期标准。
🖼️ 关键图片

📊 实验亮点
实验结果显示,伪RIS方法在多个图像分割基准数据集上显著超越了当前的弱监督和零样本方法,尤其在未见领域中表现出色,证明了其在开放世界挑战中的有效性。与完全监督方法相比,提升幅度明显,展示了其在实际应用中的潜力。
🎯 应用场景
该研究具有广泛的应用潜力,尤其在需要大量标注数据的图像分割任务中。通过自动生成高质量的伪监督,能够降低人工标注的成本,提高模型在新领域的适应能力,推动半监督学习的发展。
📄 摘要(原文)
We propose a new framework that automatically generates high-quality segmentation masks with their referring expressions as pseudo supervisions for referring image segmentation (RIS). These pseudo supervisions allow the training of any supervised RIS methods without the cost of manual labeling. To achieve this, we incorporate existing segmentation and image captioning foundation models, leveraging their broad generalization capabilities. However, the naive incorporation of these models may generate non-distinctive expressions that do not distinctively refer to the target masks. To address this challenge, we propose two-fold strategies that generate distinctive captions: 1) 'distinctive caption sampling', a new decoding method for the captioning model, to generate multiple expression candidates with detailed words focusing on the target. 2) 'distinctiveness-based text filtering' to further validate the candidates and filter out those with a low level of distinctiveness. These two strategies ensure that the generated text supervisions can distinguish the target from other objects, making them appropriate for the RIS annotations. Our method significantly outperforms both weakly and zero-shot SoTA methods on the RIS benchmark datasets. It also surpasses fully supervised methods in unseen domains, proving its capability to tackle the open-world challenge within RIS. Furthermore, integrating our method with human annotations yields further improvements, highlighting its potential in semi-supervised learning applications.