The Solution for the 5th GCAIAC Zero-shot Referring Expression Comprehension Challenge
作者: Longfei Huang, Feng Yu, Zhihao Guan, Zhonghua Wan, Yang Yang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-07-06
💡 一句话要点
提出结合视觉和文本提示的联合预测方法,解决零样本指代表达式理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 指代表达式理解 视觉提示 文本提示 多模态融合 预训练模型 联合预测
📋 核心要点
- 零样本指代表达式理解旨在直接应用预训练视觉-语言模型,无需特定训练,面临泛化性挑战。
- 该方法结合视觉和文本提示,并针对数据特性设计联合预测策略,提升模型对目标对象的定位能力。
- 实验结果表明,该方法在GCAIAC零样本指代表达式理解挑战赛中取得第一名,验证了其有效性。
📝 摘要(中文)
本报告提出了一种解决零样本指代表达式理解任务的方案。近年来,视觉-语言多模态基础模型(如CLIP、SAM)作为主流研究的基石受到了广泛关注。多模态基础模型的关键应用之一在于它们能够泛化到零样本下游任务。与传统的指代表达式理解不同,零样本指代表达式理解旨在将预训练的视觉-语言模型直接应用于该任务,而无需专门的训练。最近的研究通过引入视觉提示来增强多模态基础模型在指代表达式理解任务中的零样本性能。为了应对零样本指代表达式理解挑战,我们引入了视觉提示的组合,并考虑了文本提示的影响,采用了针对数据特征量身定制的联合预测。最终,我们的方法在A排行榜上实现了84.825的准确率,在B排行榜上实现了71.460的准确率,从而获得了第一名。
🔬 方法详解
问题定义:零样本指代表达式理解任务旨在让模型在没有经过特定训练的情况下,理解自然语言描述并定位图像中的目标对象。现有方法通常依赖于预训练的视觉-语言模型,但直接应用这些模型在指代表达式理解任务中表现不佳,尤其是在复杂场景下,模型难以准确捕捉语言描述与视觉特征之间的关联。
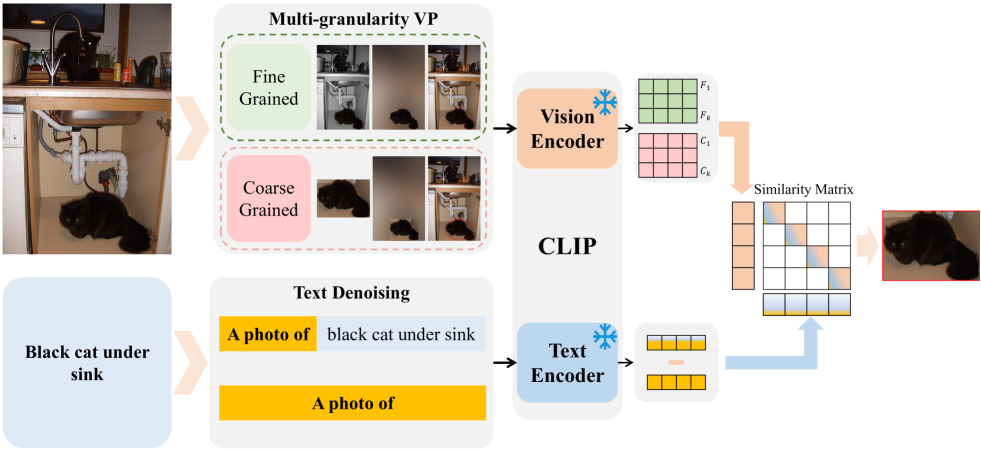
核心思路:该论文的核心思路是结合视觉提示和文本提示,利用它们来引导模型更好地理解指代表达式并定位目标对象。视觉提示通过突出图像中的潜在目标区域来减少搜索空间,而文本提示则提供额外的语言信息来增强模型对指代表达式的理解。通过联合考虑这两种提示,模型可以更准确地建立语言描述和视觉特征之间的对应关系。
技术框架:该方法的技术框架主要包括以下几个步骤:首先,利用视觉提示提取图像中的显著区域。其次,将文本提示与指代表达式进行融合,以增强语言信息的表达。然后,将视觉提示和文本提示输入到预训练的视觉-语言模型中,进行特征提取和融合。最后,利用联合预测模块,根据提取的特征预测目标对象的位置。
关键创新:该方法最重要的技术创新点在于同时考虑了视觉提示和文本提示,并设计了联合预测模块。与仅使用视觉提示或文本提示的方法相比,该方法能够更全面地利用图像和语言信息,从而提高指代表达式理解的准确性。此外,针对特定数据集的特性进行定制化设计也是一个创新点。
关键设计:在视觉提示方面,使用了SAM模型来提取图像中的显著区域。在文本提示方面,采用了某种文本增强技术(具体细节未知)来丰富指代表达式的语义信息。联合预测模块的具体结构和损失函数未知,但推测是针对指代表达式理解任务进行了优化设计。
🖼️ 关键图片


📊 实验亮点
该方法在GCAIAC零样本指代表达式理解挑战赛中,A排行榜上取得了84.825的准确率,B排行榜上取得了71.460的准确率,最终获得了第一名。这表明该方法在零样本指代表达式理解任务中具有显著的优势,能够有效地利用视觉和文本信息进行目标定位。
🎯 应用场景
该研究成果可应用于智能图像搜索、人机交互、机器人导航等领域。例如,在智能图像搜索中,用户可以通过自然语言描述快速定位图像中的目标对象。在人机交互中,机器人可以根据用户的指令,准确识别并操作指定物体。该技术还有潜力应用于自动驾驶领域,帮助车辆理解交通参与者的意图。
📄 摘要(原文)
This report presents a solution for the zero-shot referring expression comprehension task. Visual-language multimodal base models (such as CLIP, SAM) have gained significant attention in recent years as a cornerstone of mainstream research. One of the key applications of multimodal base models lies in their ability to generalize to zero-shot downstream tasks. Unlike traditional referring expression comprehension, zero-shot referring expression comprehension aims to apply pre-trained visual-language models directly to the task without specific training. Recent studies have enhanced the zero-shot performance of multimodal base models in referring expression comprehension tasks by introducing visual prompts. To address the zero-shot referring expression comprehension challenge, we introduced a combination of visual prompts and considered the influence of textual prompts, employing joint prediction tailored to the data characteristics. Ultimately, our approach achieved accuracy rates of 84.825 on the A leaderboard and 71.460 on the B leaderboard, securing the first position.