The Solution for Language-Enhanced Image New Category Discovery
作者: Haonan Xu, Dian Chao, Xiangyu Wu, Zhonghua Wan, Yang Yang
分类: cs.CV, cs.LG
发布日期: 2024-07-06
💡 一句话要点
提出伪视觉提示,增强文本标签的视觉表征能力,用于语言增强的图像新类别发现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 图像分类 新类别发现 CLIP 伪视觉提示 对比学习 多模态学习
📋 核心要点
- 现有零样本图像识别方法依赖文本标签存储视觉信息,难以充分表达视觉对象的多样性。
- 论文提出伪视觉提示,通过预训练挖掘CLIP中的视觉信息,并将其转移到文本标签,增强视觉表征能力。
- 实验结果表明,该方法在干净和伪文本数据上均超越了现有技术水平,证明了其有效性。
📝 摘要(中文)
本文提出了一种用于语言增强的图像新类别发现方法。现有方法依赖文本标签存储视觉信息,不足以表达视觉对象的多样性。本文反转CLIP的训练过程,引入伪视觉提示的概念,为每个对象类别初始化提示,并在大型、低成本的语言模型生成的句子数据上进行预训练。该过程挖掘CLIP中对齐的视觉信息,并将其存储在特定于类别的视觉提示中。然后,采用对比学习将存储的视觉信息转移到文本标签,增强其视觉表征能力。此外,引入双适配器模块,同时利用原始CLIP的知识和从下游数据集学习的新知识。受益于伪视觉提示,该方法不仅在干净的带注释文本数据上,而且在大型语言模型生成的伪文本数据上,都超越了现有技术水平。
🔬 方法详解
问题定义:现有基于CLIP的零样本图像识别方法,特别是针对新类别发现,主要依赖文本标签来表示视觉信息。然而,文本标签在捕捉视觉对象的多样性和细粒度特征方面存在局限性,导致模型在新类别上的泛化能力不足。现有方法难以有效利用CLIP模型中蕴含的丰富视觉信息。
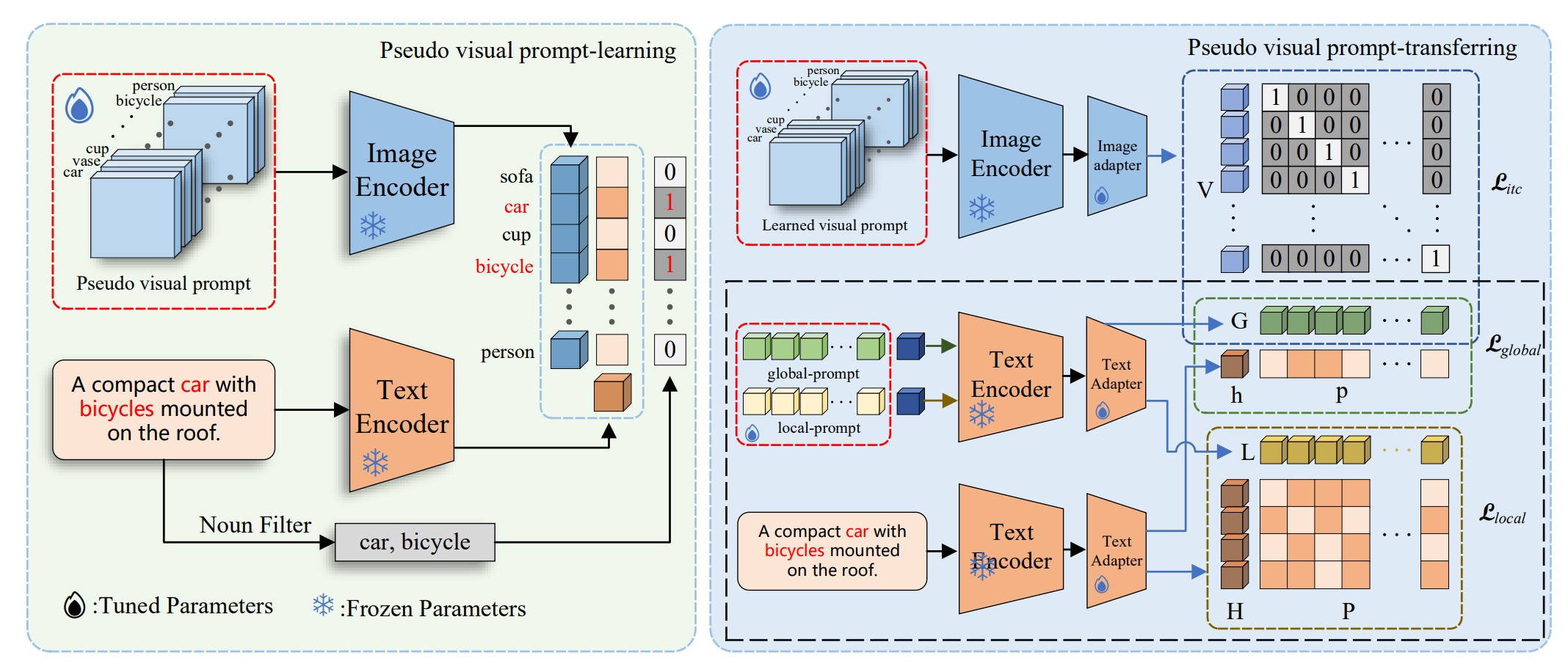
核心思路:论文的核心思路是反转CLIP的训练过程,通过引入“伪视觉提示”来显式地挖掘和存储CLIP模型中的视觉信息。这些伪视觉提示针对每个类别进行初始化和预训练,从而能够更有效地捕捉该类别的视觉特征。然后,通过对比学习将这些视觉信息迁移到文本标签,增强文本标签的视觉表征能力。
技术框架:整体框架包含以下几个主要阶段:1) 使用大型语言模型生成大规模的句子数据。2) 为每个类别初始化伪视觉提示。3) 在生成的句子数据上预训练伪视觉提示,使其能够捕捉CLIP模型中的视觉信息。4) 使用对比学习将伪视觉提示中存储的视觉信息迁移到文本标签。5) 引入双适配器模块,同时利用原始CLIP的知识和下游数据集学习的新知识。
关键创新:最重要的技术创新点在于“伪视觉提示”的概念。与直接使用文本标签不同,伪视觉提示允许模型显式地学习和存储视觉信息,从而更有效地利用CLIP模型中的视觉知识。此外,双适配器模块的设计也使得模型能够更好地融合原始CLIP的知识和下游数据集的知识。
关键设计:伪视觉提示的初始化方式未知。对比学习损失函数的具体形式未知。双适配器模块的具体网络结构和参数设置未知。预训练伪视觉提示时使用的优化器和学习率等超参数未知。
🖼️ 关键图片

📊 实验亮点
该方法通过引入伪视觉提示,在图像新类别发现任务上取得了显著的性能提升。具体提升幅度未知,但摘要中提到该方法超越了现有技术水平,尤其是在大型语言模型生成的伪文本数据上,证明了伪视觉提示的有效性。
🎯 应用场景
该研究成果可应用于图像分类、目标检测、图像检索等领域,尤其是在缺乏标注数据的新类别识别场景下具有重要价值。例如,在智能监控、自动驾驶、医疗影像分析等领域,可以利用该方法识别未知的物体或疾病类型,提高系统的智能化水平和泛化能力。未来,该方法有望扩展到其他多模态任务中,例如视频理解和跨模态检索。
📄 摘要(原文)
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.