Dude: Dual Distribution-Aware Context Prompt Learning For Large Vision-Language Model
作者: Duy M. H. Nguyen, An T. Le, Trung Q. Nguyen, Nghiem T. Diep, Tai Nguyen, Duy Duong-Tran, Jan Peters, Li Shen, Mathias Niepert, Daniel Sonntag
分类: cs.CV
发布日期: 2024-07-05
备注: Version 1
💡 一句话要点
提出基于双重分布感知的上下文提示学习框架Dude,提升大视觉语言模型在细粒度分类任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 提示学习 细粒度分类 非平衡最优传输 上下文学习
📋 核心要点
- 现有提示学习方法在细粒度分类任务中,由于缺乏足够的判别属性,难以优化统一的提示输入。
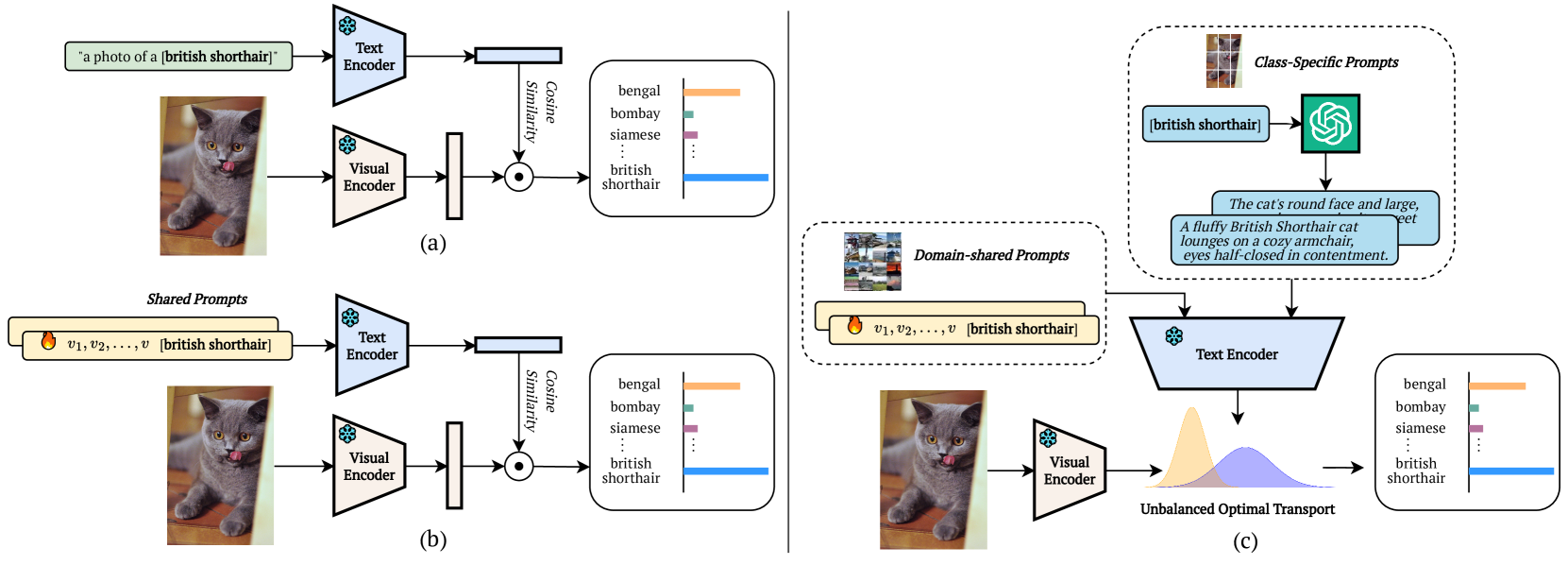
- 论文提出基于领域共享和类别特定双重上下文的提示学习框架,利用大型语言模型生成类别特定上下文。
- 实验结果表明,该模型在少量样本分类和适配器设置上优于当前最先进的基线方法,性能显著提升。
📝 摘要(中文)
本文提出了一种双重分布感知的上下文提示学习框架(Dude),旨在提升大型视觉语言模型在细粒度分类任务上的性能。该框架利用领域共享和类别特定的双重上下文,其中类别特定上下文由大型语言模型(LLM)生成。这种双重提示方法通过结合LLM知识中编码的隐式和显式因素来增强模型的特征表示。此外,本文还引入了非平衡最优传输(UOT)理论来量化构建的提示和视觉token之间的关系。UOT通过部分匹配,可以在不同的质量分布下正确对齐离散的视觉token集和提示嵌入,这对于处理不相关或噪声元素特别有价值。UOT的特性与图像增强无缝集成,扩展了训练样本池,同时保持扰动图像和提示输入之间的合理距离。在少量样本分类和适配器设置上的大量实验证明了该模型优于当前最先进的基线。
🔬 方法详解
问题定义:现有提示学习方法通常优化统一的提示输入,这在细粒度分类任务中表现不佳,因为它们难以捕捉到足够的判别性特征。模型难以区分不同类别之间的细微差别,导致分类精度下降。
核心思路:论文的核心思路是利用双重上下文提示,即同时考虑领域共享的上下文和类别特定的上下文。类别特定的上下文由大型语言模型(LLM)生成,从而引入了更丰富的语义信息和判别性特征。此外,使用非平衡最优传输(UOT)来对齐视觉token和提示嵌入,从而更好地处理噪声和不相关信息。
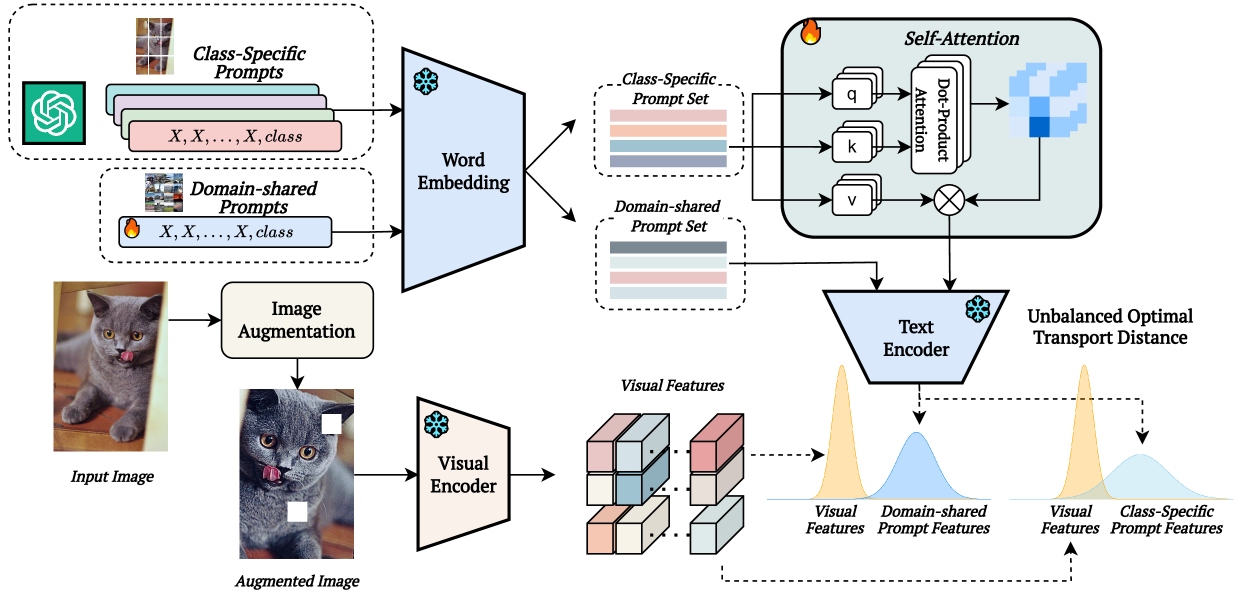
技术框架:整体框架包含以下几个主要模块:1) 视觉编码器:用于提取图像的视觉特征。2) 提示生成器:生成领域共享和类别特定的双重上下文提示,其中类别特定提示由LLM生成。3) 非平衡最优传输模块:用于对齐视觉token和提示嵌入,计算它们之间的距离。4) 分类器:基于对齐后的特征进行分类。整个流程是:输入图像经过视觉编码器得到视觉特征,然后与双重上下文提示一起输入到非平衡最优传输模块进行对齐,最后将对齐后的特征输入到分类器进行分类。
关键创新:最重要的技术创新点在于双重上下文提示学习和非平衡最优传输的应用。双重上下文提示能够提供更丰富的语义信息和判别性特征,从而提升模型的分类性能。非平衡最优传输能够更好地处理噪声和不相关信息,从而提高模型的鲁棒性。
关键设计:论文的关键设计包括:1) 使用GPT等大型语言模型生成类别特定的上下文提示。2) 引入非平衡最优传输(UOT)理论来量化提示和视觉token之间的关系,并使用Sinkhorn算法求解UOT问题。3) 将UOT与图像增强技术相结合,通过保持扰动图像和提示输入之间的合理距离来扩展训练样本池。具体的损失函数设计未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该模型在少量样本分类和适配器设置上均优于当前最先进的基线方法。具体的性能提升数据未知,但摘要中明确指出该模型在多个实验中都取得了显著的性能提升,证明了其有效性。
🎯 应用场景
该研究成果可应用于各种细粒度图像分类任务,例如动植物识别、医学图像诊断、产品缺陷检测等。通过利用大型语言模型的知识和非平衡最优传输的对齐能力,可以有效提升分类精度和鲁棒性,具有重要的实际应用价值和广泛的应用前景。
📄 摘要(原文)
Prompt learning methods are gaining increasing attention due to their ability to customize large vision-language models to new domains using pre-trained contextual knowledge and minimal training data. However, existing works typically rely on optimizing unified prompt inputs, often struggling with fine-grained classification tasks due to insufficient discriminative attributes. To tackle this, we consider a new framework based on a dual context of both domain-shared and class-specific contexts, where the latter is generated by Large Language Models (LLMs) such as GPTs. Such dual prompt methods enhance the model's feature representation by joining implicit and explicit factors encoded in LLM knowledge. Moreover, we formulate the Unbalanced Optimal Transport (UOT) theory to quantify the relationships between constructed prompts and visual tokens. Through partial matching, UOT can properly align discrete sets of visual tokens and prompt embeddings under different mass distributions, which is particularly valuable for handling irrelevant or noisy elements, ensuring that the preservation of mass does not restrict transport solutions. Furthermore, UOT's characteristics integrate seamlessly with image augmentation, expanding the training sample pool while maintaining a reasonable distance between perturbed images and prompt inputs. Extensive experiments across few-shot classification and adapter settings substantiate the superiority of our model over current state-of-the-art baselines.