QueryMamba: A Mamba-Based Encoder-Decoder Architecture with a Statistical Verb-Noun Interaction Module for Video Action Forecasting @ Ego4D Long-Term Action Anticipation Challenge 2024
作者: Zeyun Zhong, Manuel Martin, Frederik Diederichs, Juergen Beyerer
分类: cs.CV
发布日期: 2024-07-04
💡 一句话要点
提出QueryMamba,结合统计动宾交互模块,用于视频行为预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频行为预测 Mamba架构 动宾交互 统计建模 长时行为预测
📋 核心要点
- 现有视频行为预测方法缺乏对动词和名词之间关系的有效建模,限制了预测精度。
- QueryMamba通过引入统计动宾共现矩阵,显式地建模动词和名词之间的依赖关系,提升预测性能。
- 实验表明,QueryMamba在Ego4D LTA挑战赛中取得了优异成绩,尤其在名词预测方面表现突出。
📝 摘要(中文)
本报告介绍了一种新颖的基于Mamba的编码器-解码器架构QueryMamba,它具有一个集成的动宾交互模块,该模块利用统计动宾共现矩阵来增强视频行为预测。该架构不仅基于历史数据预测可能发生的动词和名词,还考虑了它们的联合出现以提高预测准确性。实验结果证实了该方法的有效性,该方法在Ego4D LTA挑战赛中获得第二名,并在名词预测准确率方面排名第一。
🔬 方法详解
问题定义:视频行为预测旨在根据历史视频数据预测未来可能发生的行为。现有方法通常独立地预测动词和名词,忽略了它们之间的内在联系,导致预测精度受限。尤其是在长时行为预测中,这种关联性的缺失会显著降低预测的准确性。
核心思路:QueryMamba的核心思路是利用统计动宾共现矩阵来显式地建模动词和名词之间的依赖关系。通过学习历史数据中动词和名词的共现频率,构建一个统计模型,用于指导预测过程,从而提高预测的准确性。
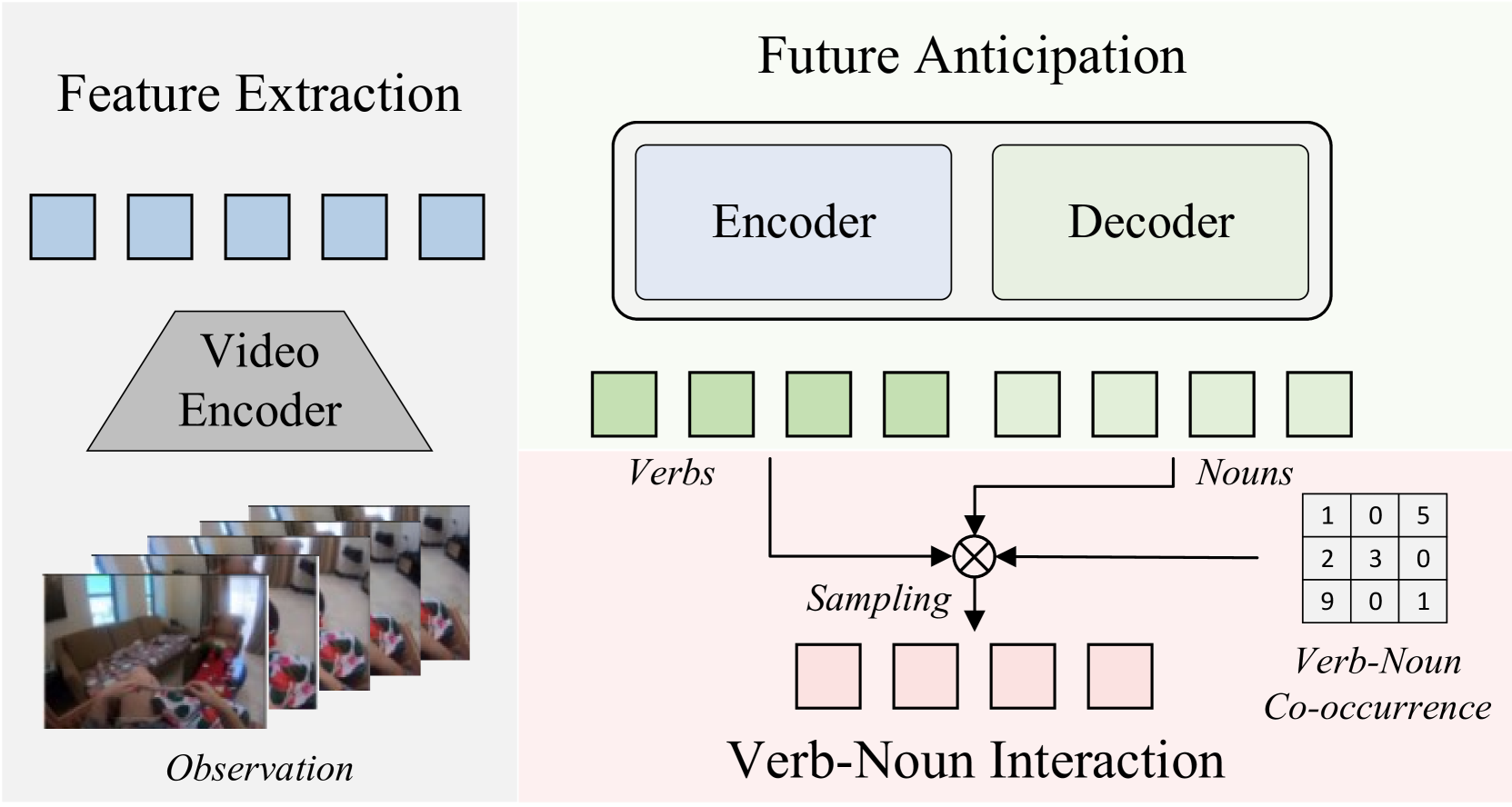
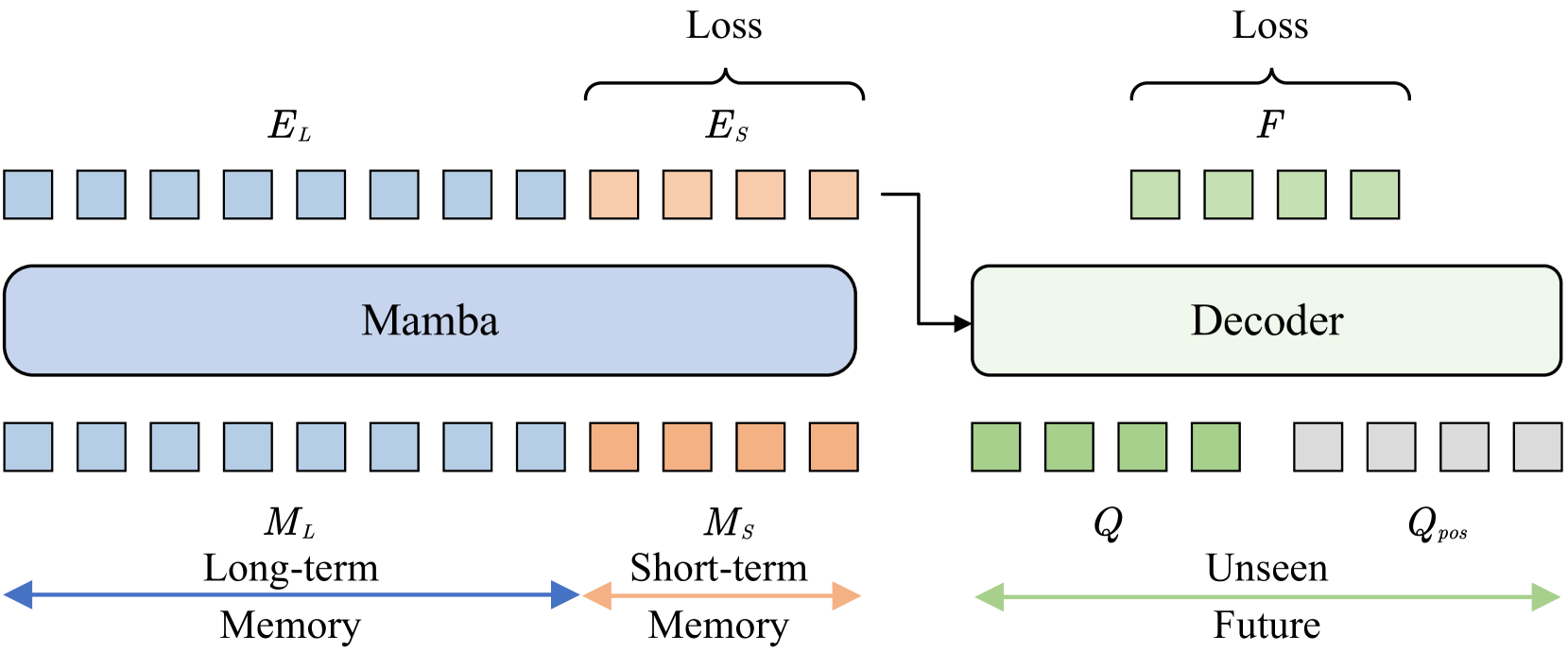
技术框架:QueryMamba采用基于Mamba的编码器-解码器架构。编码器负责提取历史视频数据的特征表示,解码器则利用这些特征和动宾交互模块预测未来可能发生的行为。动宾交互模块接收解码器的输出,并结合统计动宾共现矩阵,调整动词和名词的预测概率。整体流程包括特征提取、编码、解码和动宾交互四个主要阶段。
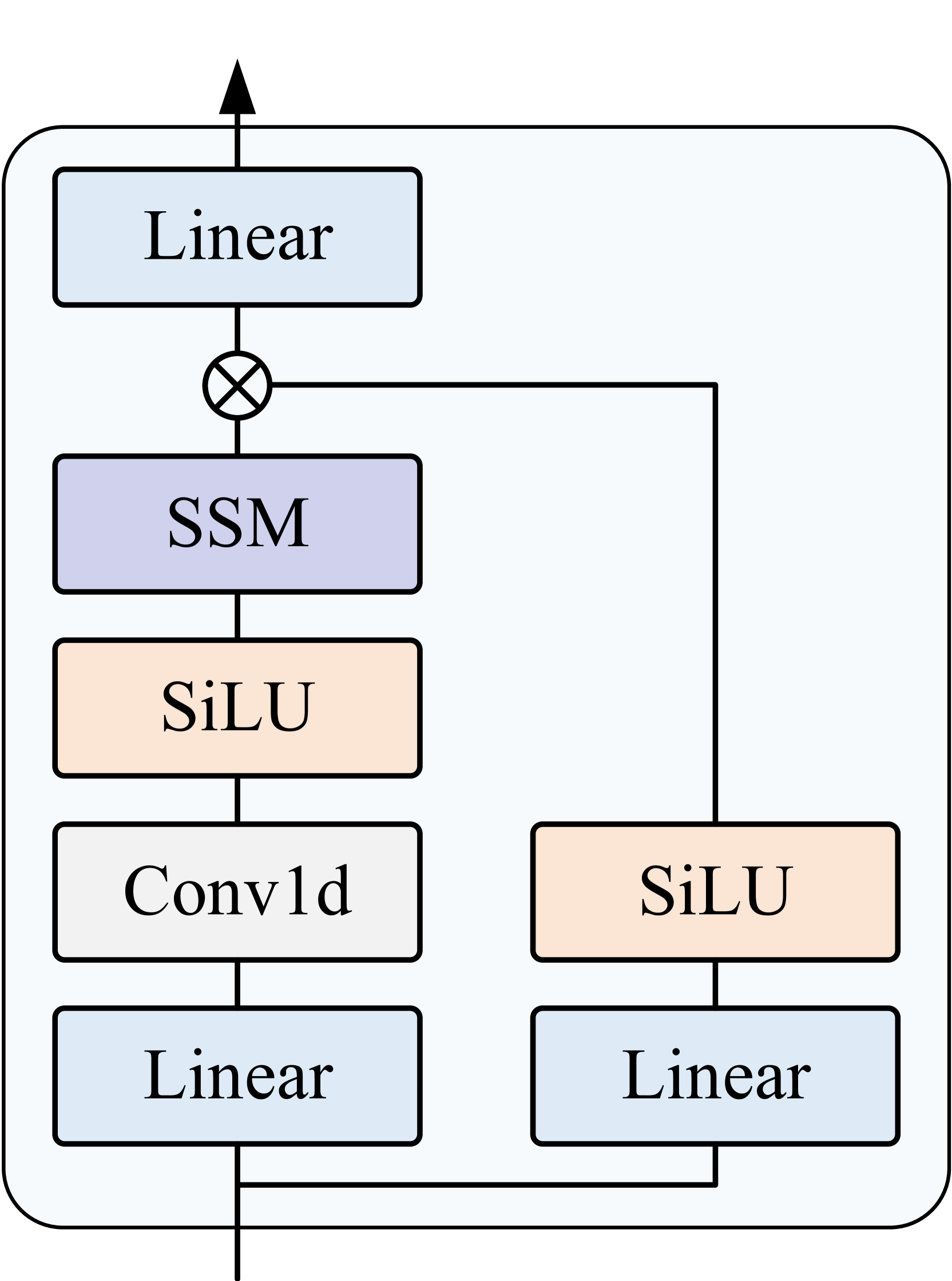
关键创新:QueryMamba的关键创新在于集成了统计动宾交互模块。该模块利用统计方法学习动词和名词之间的依赖关系,并将其融入到预测过程中。与传统的独立预测方法相比,QueryMamba能够更准确地预测未来可能发生的行为。Mamba架构的使用也使得模型能够处理更长的视频序列,从而提升长时行为预测的性能。
关键设计:统计动宾共现矩阵的构建是关键设计之一。该矩阵通过统计历史数据中动词和名词的共现频率得到。在预测阶段,该矩阵被用于调整解码器输出的动词和名词的预测概率。具体的调整方式未知,但可以推测是利用共现矩阵对预测结果进行加权或修正。此外,Mamba架构的具体配置(如层数、隐藏层大小等)也可能对性能产生影响,但论文中未提供详细信息。
🖼️ 关键图片
📊 实验亮点
QueryMamba在Ego4D LTA挑战赛中取得了第二名的成绩,并在名词预测准确率方面排名第一。这表明QueryMamba在视频行为预测任务中具有很强的竞争力,尤其在名词预测方面表现突出。具体的性能数据和对比基线未知,但可以推断QueryMamba相对于其他方法在名词预测准确率方面有显著提升。
🎯 应用场景
QueryMamba在视频行为预测领域具有广泛的应用前景,例如智能监控、人机交互、机器人导航等。通过准确预测未来行为,可以提前采取相应的措施,提高系统的智能化水平和安全性。例如,在智能监控中,可以预测潜在的危险行为,及时发出警报;在人机交互中,可以预测用户的意图,提供更自然、流畅的交互体验。
📄 摘要(原文)
This report presents a novel Mamba-based encoder-decoder architecture, QueryMamba, featuring an integrated verb-noun interaction module that utilizes a statistical verb-noun co-occurrence matrix to enhance video action forecasting. This architecture not only predicts verbs and nouns likely to occur based on historical data but also considers their joint occurrence to improve forecast accuracy. The efficacy of this approach is substantiated by experimental results, with the method achieving second place in the Ego4D LTA challenge and ranking first in noun prediction accuracy.