DyFADet: Dynamic Feature Aggregation for Temporal Action Detection
作者: Le Yang, Ziwei Zheng, Yizeng Han, Hao Cheng, Shiji Song, Gao Huang, Fan Li
分类: cs.CV
发布日期: 2024-07-03
备注: ECCV 2024
🔗 代码/项目: GITHUB
💡 一句话要点
提出DyFADet,通过动态特征聚合解决时序动作检测中长短动作实例的检测难题。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序动作检测 动态特征聚合 动态神经网络 视频理解 深度学习
📋 核心要点
- 现有TAD模型难以提取判别性特征,且对不同长度的动作实例建模能力有限,尤其是在复杂场景下。
- 提出动态特征聚合(DFA)模块,自适应调整核权重和感受野,增强特征判别性,提升对不同长度动作的建模能力。
- DyFADet在多个TAD基准测试中表现出色,证明了所提方法的有效性,代码已开源。
📝 摘要(中文)
本文提出了一种新的基于动态特征聚合(DFA)模块的时序动作检测(TAD)模型,旨在解决现有模型在复杂场景中提取判别性特征和建模不同长度动作实例方面的局限性。DFA模块能够同时自适应地调整不同时间戳上的核权重和感受野。基于DFA,提出的动态编码器层聚合动作时间范围内的时序特征,保证提取表示的判别性。此外,DFA还有助于开发动态TAD头(DyHead),自适应地聚合多尺度特征,并调整参数和学习感受野,从而更好地检测视频中不同范围的动作实例。提出的DyFADet模型在一系列具有挑战性的TAD基准测试中取得了有希望的性能,包括HACS-Segment、THUMOS14、ActivityNet-1.3、Epic-Kitchen 100、Ego4D-Moment QueriesV1.0和FineAction。
🔬 方法详解
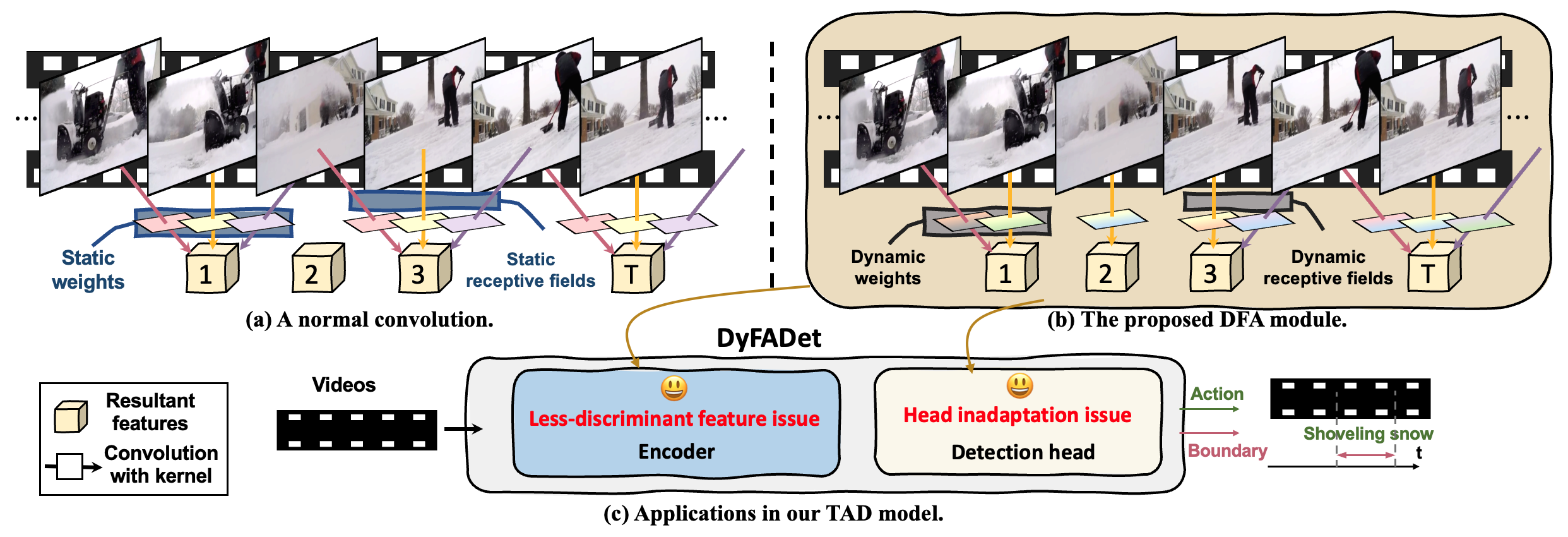
问题定义:时序动作检测旨在识别视频中动作的起始和结束时间。现有方法通常使用共享权重的检测头,这限制了模型提取判别性特征和建模不同长度动作实例的能力,尤其是在复杂场景中,不同动作的持续时间差异很大,且背景噪声较多。
核心思路:本文的核心思路是引入动态神经网络的思想,通过动态调整卷积核的权重和感受野,使模型能够自适应地关注不同时间戳上的重要特征,从而更好地提取判别性特征并适应不同长度的动作实例。DFA模块是实现这一目标的关键。
技术框架:DyFADet模型主要由动态编码器层和动态TAD头(DyHead)组成。动态编码器层利用DFA模块聚合动作时间范围内的时序特征,增强特征的判别性。DyHead则利用DFA模块自适应地聚合多尺度特征,并调整参数和学习感受野,从而更好地检测不同范围的动作实例。整体流程是:输入视频帧特征,经过动态编码器层提取特征,然后通过DyHead进行动作检测。
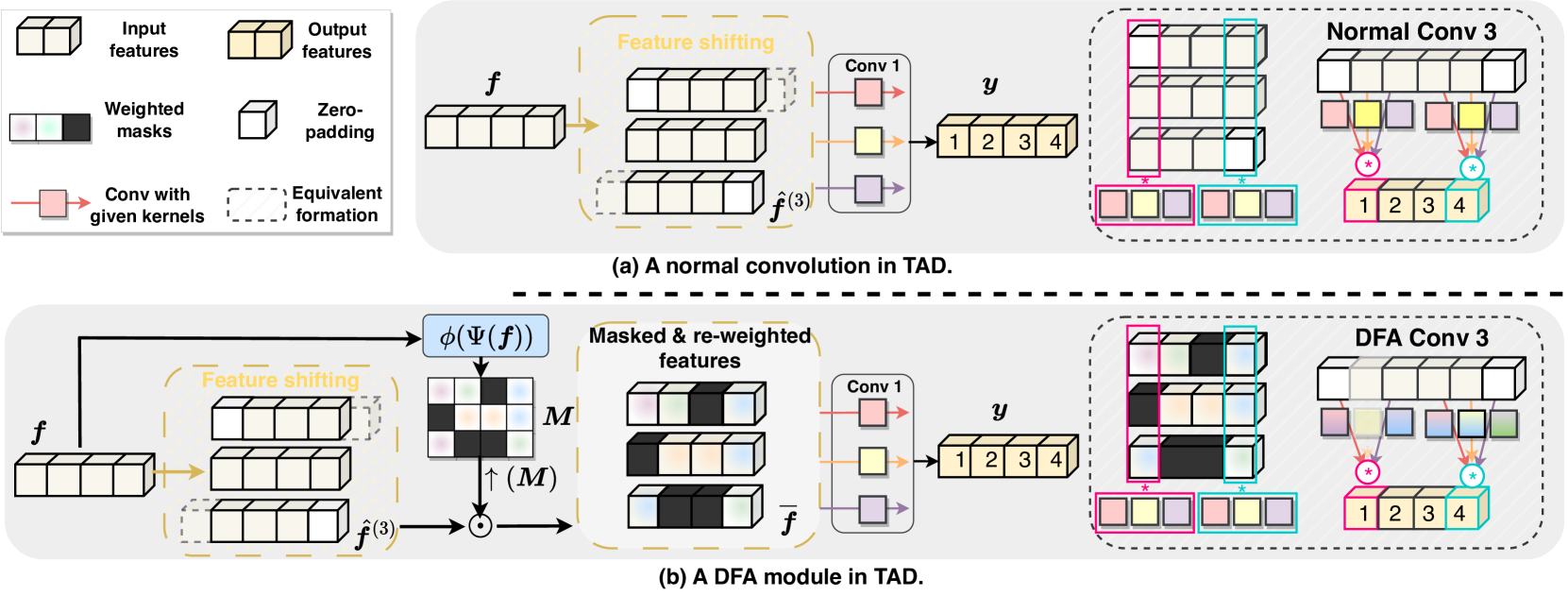
关键创新:最重要的技术创新点是DFA模块,它能够同时自适应地调整卷积核的权重和感受野。与传统的静态卷积核相比,DFA模块可以根据输入特征动态地调整其参数,从而更好地适应不同的动作实例。这种动态调整机制使得模型能够更好地关注重要的时间戳和特征,提高检测精度。
关键设计:DFA模块的具体实现细节包括:使用注意力机制来学习不同时间戳上的权重,并使用可变形卷积来调整感受野。损失函数方面,使用了标准的分类损失和回归损失,并针对动态特性进行了调整。网络结构方面,采用了多尺度特征融合的策略,以更好地检测不同尺度的动作实例。
🖼️ 关键图片

📊 实验亮点
DyFADet在HACS-Segment、THUMOS14、ActivityNet-1.3等多个具有挑战性的TAD基准测试中取得了显著的性能提升。例如,在ActivityNet-1.3数据集上,相较于之前的SOTA方法,DyFADet取得了明显的性能提升,证明了其有效性。具体的性能数据可以在论文的实验部分找到。
🎯 应用场景
DyFADet在视频监控、智能安防、人机交互、体育赛事分析、自动驾驶等领域具有广泛的应用前景。例如,在视频监控中,可以用于自动检测异常行为;在体育赛事分析中,可以用于自动识别运动员的动作;在自动驾驶中,可以用于识别行人和车辆的动作。
📄 摘要(原文)
Recent proposed neural network-based Temporal Action Detection (TAD) models are inherently limited to extracting the discriminative representations and modeling action instances with various lengths from complex scenes by shared-weights detection heads. Inspired by the successes in dynamic neural networks, in this paper, we build a novel dynamic feature aggregation (DFA) module that can simultaneously adapt kernel weights and receptive fields at different timestamps. Based on DFA, the proposed dynamic encoder layer aggregates the temporal features within the action time ranges and guarantees the discriminability of the extracted representations. Moreover, using DFA helps to develop a Dynamic TAD head (DyHead), which adaptively aggregates the multi-scale features with adjusted parameters and learned receptive fields better to detect the action instances with diverse ranges from videos. With the proposed encoder layer and DyHead, a new dynamic TAD model, DyFADet, achieves promising performance on a series of challenging TAD benchmarks, including HACS-Segment, THUMOS14, ActivityNet-1.3, Epic-Kitchen 100, Ego4D-Moment QueriesV1.0, and FineAction. Code is released to https://github.com/yangle15/DyFADet-pytorch.