Unified Anomaly Detection methods on Edge Device using Knowledge Distillation and Quantization
作者: Sushovan Jena, Arya Pulkit, Kajal Singh, Anoushka Banerjee, Sharad Joshi, Ananth Ganesh, Dinesh Singh, Arnav Bhavsar
分类: cs.CV, cs.AI, cs.CC, cs.ET
发布日期: 2024-07-03
备注: 20 pages
💡 一句话要点
提出基于知识蒸馏和量化的边缘设备统一异常检测方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异常检测 边缘计算 知识蒸馏 模型量化 多类分类 工业视觉检测 MVTec AD
📋 核心要点
- 现有异常检测方法通常依赖单类模型,需要为每个类别单独训练,计算和存储成本高昂。
- 本文提出一种统一的多类异常检测框架,通过知识蒸馏和量化技术,降低模型复杂度和资源消耗。
- 实验表明,多类模型在MVTec AD数据集上性能与单类模型相当,且量化感知训练能有效弥补量化带来的性能损失。
📝 摘要(中文)
随着深度学习和工业4.0智能制造的快速发展,对高吞吐量、高性能和完全集成的视觉检测系统的需求迫在眉睫。大多数使用缺陷检测数据集(如MVTec AD)的异常检测方法采用单类模型,需要为每个类别拟合单独的模型。相反,统一模型消除了为每个类别拟合单独模型的需求,并显著降低了成本和内存需求。因此,本文尝试考虑统一的多类设置。实验研究表明,对于标准MVTec AD数据集,多类模型的性能与单类模型相当。这表明,当对象类别彼此显著不同时,可能不需要学习单独的按对象/类别的模型,正如所考虑的数据集的情况。此外,还在CPU和边缘设备(NVIDIA Jetson Xavier NX)上部署了三种不同的统一轻量级架构。分析了量化的多类异常检测模型在边缘设备上的延迟和内存需求,同时比较了量化感知训练(QAT)和训练后量化(PTQ)在不同精度宽度下的性能。此外,探索了训练后场景中所需的两种不同的校准方法,并表明其中一种方法的性能明显更好,突出了其在无监督任务中的重要性。由于量化,PTQ的性能下降可以通过QAT进一步补偿,从而在所考虑的两个模型中产生与原始32位浮点数相当的性能。
🔬 方法详解
问题定义:现有异常检测方法,特别是基于深度学习的方法,通常采用单类模型,即为每个待检测的类别训练一个独立的模型。这种方法在类别数量较多时,会显著增加计算和存储开销,难以部署在资源受限的边缘设备上。此外,为每个类别单独训练模型也增加了模型管理的复杂性。
核心思路:本文的核心思路是利用统一的多类模型来替代多个单类模型。通过将所有类别的数据混合在一起训练一个模型,从而降低模型的数量和整体复杂度。此外,采用知识蒸馏和量化技术进一步压缩模型,使其更适合在边缘设备上部署。这种设计旨在降低资源消耗,同时保持甚至提升异常检测的性能。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:将多个类别的正常数据混合在一起,作为训练数据。2) 模型训练:训练一个多类分类模型,用于区分不同的正常类别。3) 知识蒸馏:使用一个较大的教师模型指导训练一个更小的学生模型,从而提高学生模型的性能。4) 模型量化:将训练好的模型进行量化,降低模型的存储空间和计算复杂度。5) 边缘部署:将量化后的模型部署到边缘设备上,进行实时异常检测。
关键创新:该方法最重要的创新点在于将统一的多类模型与知识蒸馏和量化技术相结合,从而在降低资源消耗的同时,保持了较高的异常检测性能。与传统的单类模型相比,该方法显著降低了模型数量和复杂度,更适合在边缘设备上部署。此外,该方法还探索了不同的量化方法和校准策略,并分析了它们对模型性能的影响。
关键设计:在模型训练阶段,使用了交叉熵损失函数来优化多类分类模型。在知识蒸馏阶段,使用了温度缩放的softmax输出来计算教师模型和学生模型之间的KL散度损失。在模型量化阶段,比较了量化感知训练(QAT)和训练后量化(PTQ)两种方法,并探索了不同的校准策略,例如最大值校准和百分位数校准。此外,还针对不同的边缘设备,选择了合适的轻量级网络架构,例如MobileNetV2和ShuffleNetV2。
🖼️ 关键图片

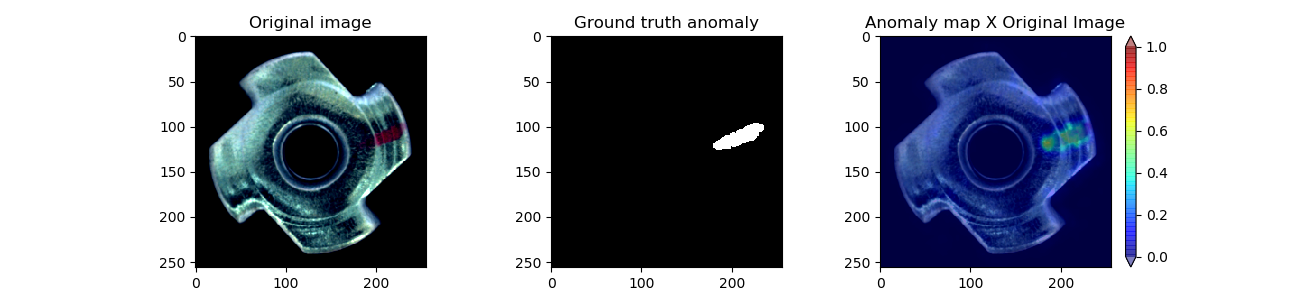

📊 实验亮点
实验结果表明,多类模型在MVTec AD数据集上的性能与单类模型相当,甚至在某些类别上有所提升。通过量化感知训练(QAT),可以有效弥补量化带来的性能损失,使量化后的模型性能接近原始32位浮点模型。在NVIDIA Jetson Xavier NX边缘设备上,量化后的模型实现了显著的加速,同时降低了内存占用。
🎯 应用场景
该研究成果可广泛应用于工业4.0中的智能制造领域,例如产品质量检测、设备故障诊断等。通过在边缘设备上部署轻量级的异常检测模型,可以实现实时、高效的视觉检测,降低生产成本,提高产品质量。此外,该方法还可以应用于其他领域,例如智能安防、医疗诊断等,具有广阔的应用前景。
📄 摘要(原文)
With the rapid advances in deep learning and smart manufacturing in Industry 4.0, there is an imperative for high-throughput, high-performance, and fully integrated visual inspection systems. Most anomaly detection approaches using defect detection datasets, such as MVTec AD, employ one-class models that require fitting separate models for each class. On the contrary, unified models eliminate the need for fitting separate models for each class and significantly reduce cost and memory requirements. Thus, in this work, we experiment with considering a unified multi-class setup. Our experimental study shows that multi-class models perform at par with one-class models for the standard MVTec AD dataset. Hence, this indicates that there may not be a need to learn separate object/class-wise models when the object classes are significantly different from each other, as is the case of the dataset considered. Furthermore, we have deployed three different unified lightweight architectures on the CPU and an edge device (NVIDIA Jetson Xavier NX). We analyze the quantized multi-class anomaly detection models in terms of latency and memory requirements for deployment on the edge device while comparing quantization-aware training (QAT) and post-training quantization (PTQ) for performance at different precision widths. In addition, we explored two different methods of calibration required in post-training scenarios and show that one of them performs notably better, highlighting its importance for unsupervised tasks. Due to quantization, the performance drop in PTQ is further compensated by QAT, which yields at par performance with the original 32-bit Floating point in two of the models considered.