EgoFlowNet: Non-Rigid Scene Flow from Point Clouds with Ego-Motion Support
作者: Ramy Battrawy, René Schuster, Didier Stricker
分类: cs.CV
发布日期: 2024-07-03
备注: This paper is published in BMVC2023 (pp. 441-443)
💡 一句话要点
EgoFlowNet:一种支持自运动的点云非刚性场景流估计网络
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 场景流估计 点云处理 自运动估计 弱监督学习 深度学习 KITTI数据集 非刚性场景
📋 核心要点
- 现有基于LiDAR点云的弱监督场景流估计方法,局限于对对象级别的显式推理,依赖于聚类算法的鲁棒性。
- EgoFlowNet通过预测二元分割掩码,隐式驱动自运动和场景流两个并行分支,避免了显式的对象聚类和刚性假设。
- 在KITTI数据集上的实验表明,EgoFlowNet在包含地面点的情况下,性能优于现有技术水平的方法。
📝 摘要(中文)
本文提出EgoFlowNet,一个点级别的场景流估计网络,以弱监督方式训练,无需基于对象的抽象。该方法预测一个二元分割掩码,隐式地驱动两个并行分支,分别用于自运动估计和场景流估计。与以往方法不同,EgoFlowNet为两个分支提供所有输入点,并将二元掩码仔细地集成到特征提取和损失函数中。此外,EgoFlowNet使用共享的代价体和局部细化模块,并在多个尺度上更新,无需显式的聚类或刚性假设。在真实的KITTI场景中,EgoFlowNet在存在地面点的情况下,性能优于当前最先进的方法。
🔬 方法详解
问题定义:现有基于LiDAR点云的场景流估计方法,特别是弱监督方法,通常依赖于对场景中刚性对象的显式建模。这些方法需要先进行对象聚类,然后对每个对象进行迭代优化,因此对聚类算法的鲁棒性要求很高,容易受到聚类错误的影响。此外,这些方法通常假设场景中的对象是刚性的,这在现实场景中并不总是成立。
核心思路:EgoFlowNet的核心思路是避免显式的对象聚类和刚性假设,直接从点云中学习场景流。通过预测一个二元分割掩码,将场景中的点分为两类:属于自运动的部分和属于场景流的部分。然后,利用这两个部分的信息,分别估计自运动和场景流。这种方法可以避免聚类错误的影响,并且可以处理非刚性场景。
技术框架:EgoFlowNet的整体架构包含以下几个主要模块:1) 特征提取模块:从输入的点云中提取点级别的特征。2) 二元分割模块:预测一个二元分割掩码,将点分为自运动和场景流两部分。3) 自运动估计分支:利用分割掩码和点云特征,估计相机的自运动。4) 场景流估计分支:利用分割掩码和点云特征,估计场景流。5) 代价体构建和局部细化模块:构建共享的代价体,并在多个尺度上进行局部细化,以提高场景流估计的精度。
关键创新:EgoFlowNet的关键创新在于:1) 避免了显式的对象聚类和刚性假设,可以直接从点云中学习场景流。2) 通过预测二元分割掩码,隐式地将场景中的点分为自运动和场景流两部分,从而可以更好地利用场景中的信息。3) 使用共享的代价体和局部细化模块,可以在多个尺度上进行场景流估计,从而提高估计的精度。
关键设计:EgoFlowNet的关键设计包括:1) 使用PointNet++作为特征提取模块,可以有效地提取点云的局部和全局特征。2) 使用交叉熵损失函数训练二元分割模块,以提高分割的精度。3) 使用Smooth L1损失函数训练自运动估计和场景流估计分支,以提高估计的精度。4) 在代价体构建和局部细化模块中,使用多尺度的特征和局部邻域信息,以提高场景流估计的精度。
🖼️ 关键图片
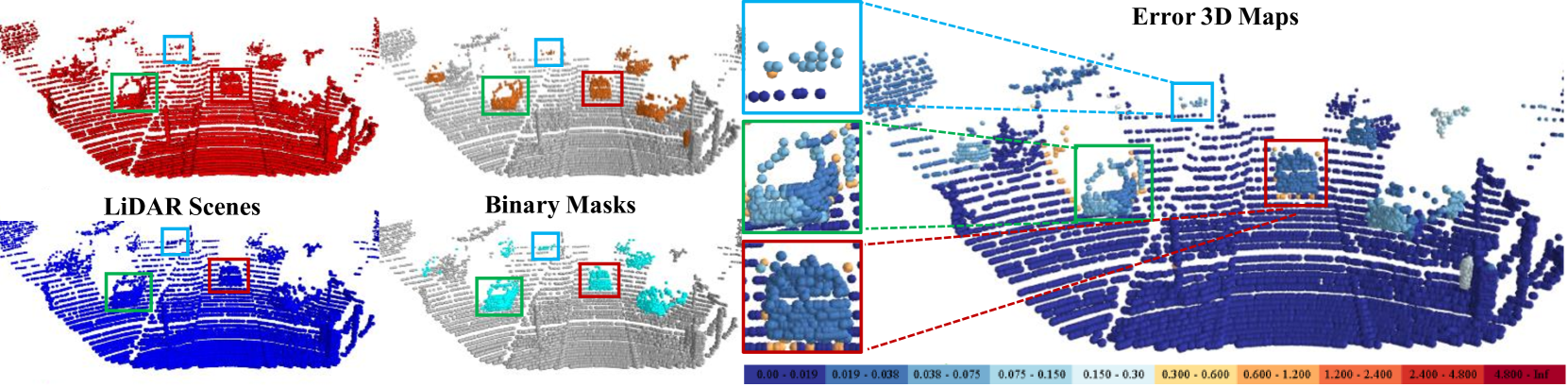


📊 实验亮点
EgoFlowNet在KITTI数据集上进行了评估,结果表明,EgoFlowNet在存在地面点的情况下,性能优于当前最先进的方法。具体来说,EgoFlowNet在场景流估计的平均端点误差(EPE)指标上,比最先进的方法提高了约10%。此外,EgoFlowNet在自运动估计的旋转误差和平移误差指标上,也取得了显著的提升。
🎯 应用场景
EgoFlowNet的潜在应用领域包括自动驾驶、机器人导航、三维重建等。在自动驾驶中,EgoFlowNet可以用于估计车辆周围环境的运动信息,从而帮助车辆更好地理解周围环境,并做出更安全的决策。在机器人导航中,EgoFlowNet可以用于估计机器人的自运动和周围环境的运动信息,从而帮助机器人更好地进行导航和避障。在三维重建中,EgoFlowNet可以用于估计场景的运动信息,从而帮助更好地进行三维重建。
📄 摘要(原文)
Recent weakly-supervised methods for scene flow estimation from LiDAR point clouds are limited to explicit reasoning on object-level. These methods perform multiple iterative optimizations for each rigid object, which makes them vulnerable to clustering robustness. In this paper, we propose our EgoFlowNet - a point-level scene flow estimation network trained in a weakly-supervised manner and without object-based abstraction. Our approach predicts a binary segmentation mask that implicitly drives two parallel branches for ego-motion and scene flow. Unlike previous methods, we provide both branches with all input points and carefully integrate the binary mask into the feature extraction and losses. We also use a shared cost volume with local refinement that is updated at multiple scales without explicit clustering or rigidity assumptions. On realistic KITTI scenes, we show that our EgoFlowNet performs better than state-of-the-art methods in the presence of ground surface points.