Multi-Task Domain Adaptation for Language Grounding with 3D Objects
作者: Penglei Sun, Yaoxian Song, Xinglin Pan, Peijie Dong, Xiaofei Yang, Qiang Wang, Zhixu Li, Tiefeng Li, Xiaowen Chu
分类: cs.CV
发布日期: 2024-07-03 (更新: 2024-07-05)
💡 一句话要点
提出DA4LG,通过多任务领域自适应实现3D对象语言定位的跨域泛化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D对象语言定位 领域自适应 多任务学习 视觉-语言对齐 跨模态学习
📋 核心要点
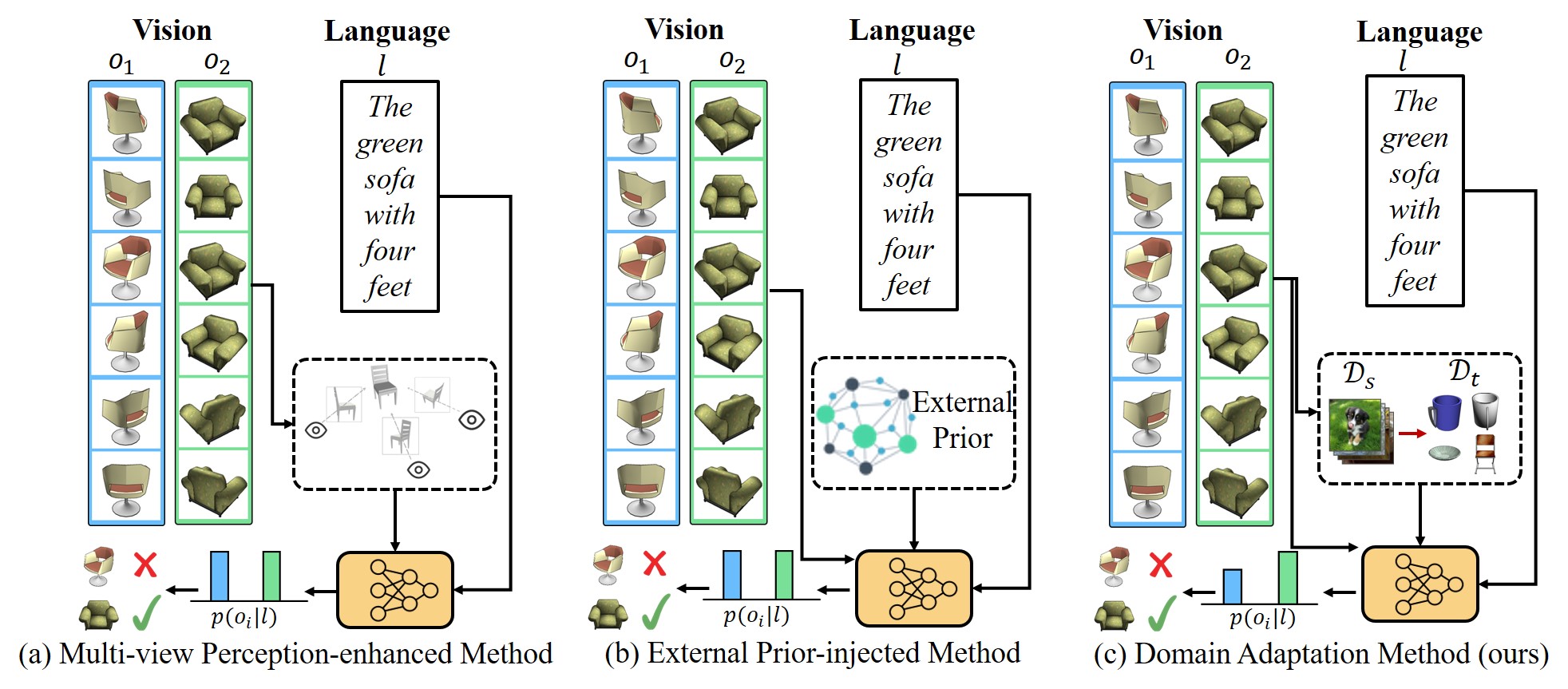
- 现有3D对象语言定位方法缺乏跨域的语言-视觉对齐的探索,限制了模型的泛化能力。
- DA4LG通过视觉适配器模块和多任务学习,实现全面的多模态特征表示,从而进行视觉-语言对齐。
- DA4LG在SNARE基准测试中取得了SOTA结果,并在单视图和多视图设置下分别达到了83.8%和86.8%的精度。
📝 摘要(中文)
现有的基于3D对象的对象级语言定位工作主要集中于利用现成的预训练模型来捕获特征,例如视点选择或几何先验,从而提高性能。然而,它们未能考虑探索跨域领域中语言-视觉对齐的跨模态表示。为了解决这个问题,我们提出了一种名为“用于语言定位的领域自适应(DA4LG)”的新方法,用于处理3D对象。具体而言,所提出的DA4LG包含一个具有多任务学习的视觉适配器模块,通过全面的多模态特征表示来实现视觉-语言对齐。实验结果表明,DA4LG在视觉和非视觉语言描述方面都表现出竞争优势,且不受观察完整性的影响。在语言定位基准SNARE中,DA4LG在单视图设置和多视图设置中分别实现了83.8%和86.8%的state-of-the-art精度。仿真实验表明,与现有方法相比,DA4LG具有良好的实用性和泛化性能。我们的项目可在https://sites.google.com/view/da4lg上找到。
🔬 方法详解
问题定义:现有基于3D对象的语言定位方法主要依赖于预训练模型提取特征,如视点选择和几何先验,但忽略了跨域场景下视觉和语言特征的对齐问题。这导致模型在不同领域的数据上泛化能力较差,尤其是在观察不完整的情况下,性能会显著下降。
核心思路:DA4LG的核心思路是通过领域自适应的方式,学习一个领域不变的视觉-语言联合表示。通过多任务学习,模型能够同时学习到不同领域的特征,并减小领域之间的差异,从而提高模型的泛化能力。视觉适配器模块用于提取和对齐视觉特征,使其与语言特征更好地融合。
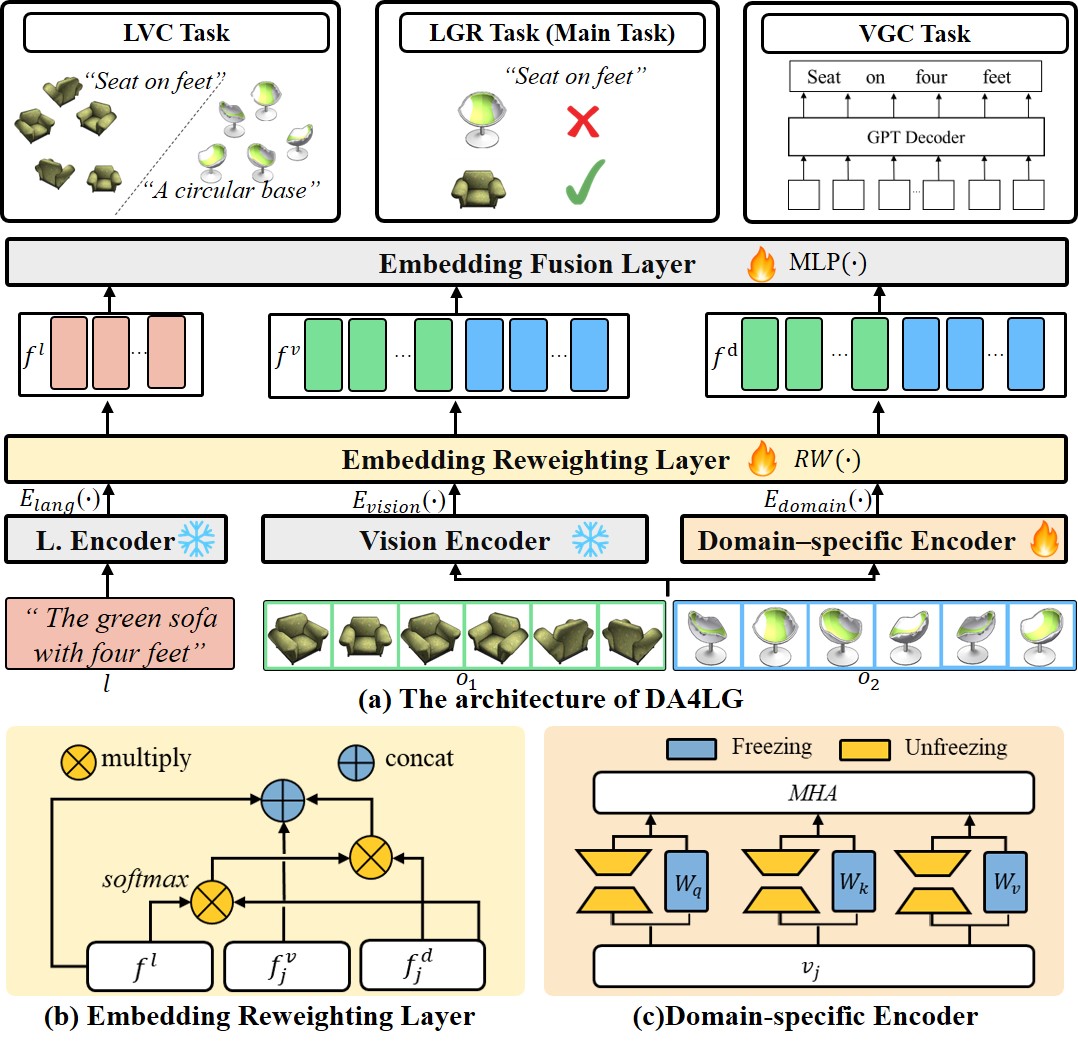
技术框架:DA4LG包含一个视觉适配器模块,该模块与现有的视觉特征提取器(例如,从预训练模型中提取的特征)相结合。视觉适配器通过多任务学习框架进行训练,该框架包含多个辅助任务,例如领域分类、重建等,以促进视觉和语言特征的对齐。整个流程包括:输入3D对象和语言描述,通过视觉适配器和语言编码器提取特征,然后通过融合模块进行特征融合,最后进行对象定位。
关键创新:DA4LG的关键创新在于引入了领域自适应的思想,并设计了视觉适配器模块,通过多任务学习来实现跨域的视觉-语言对齐。与现有方法相比,DA4LG能够更好地处理不同领域的数据,并且在观察不完整的情况下也能保持较好的性能。
关键设计:视觉适配器模块的网络结构未知,但可以推测其包含卷积层、池化层和全连接层等,用于提取和转换视觉特征。多任务学习框架中的损失函数包括定位损失、领域分类损失和重建损失等,用于指导模型学习领域不变的特征表示。具体的参数设置和网络结构细节在论文中可能有所描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
DA4LG在SNARE基准测试中取得了显著的性能提升,在单视图设置下达到了83.8%的精度,在多视图设置下达到了86.8%的精度,超越了现有的state-of-the-art方法。仿真实验也表明,DA4LG具有良好的实用性和泛化性能,能够有效地处理不同领域的数据。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、虚拟现实和增强现实等领域。例如,机器人可以通过理解人类的语言指令,在复杂的3D环境中定位和操作物体。在智能家居中,用户可以通过语音控制来选择和操作家电。该研究还有助于提升跨模态信息检索和人机交互的效率和准确性。
📄 摘要(原文)
The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.