MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis
作者: Lei Chen, Feng Yan, Yujie Zhong, Shaoxiang Chen, Zequn Jie, Lin Ma
分类: cs.CV, cs.AI, cs.CL
发布日期: 2024-07-03
备注: technical report
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MindBench:用于思维导图结构识别与分析的综合性基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 思维导图 结构化文档分析 多模态学习 基准测试 视觉问答
📋 核心要点
- 现有文档分析基准测试忽略了结构化文档中元素间复杂交互,限制了多模态大型语言模型在该领域的应用。
- MindBench基准测试通过构建双语数据集和设计五种结构化理解任务,全面评估模型在文本、空间和关系理解方面的能力。
- 实验结果表明,现有模型在处理结构化文档信息方面仍有很大提升空间,MindBench为未来研究提供了方向。
📝 摘要(中文)
多模态大型语言模型(MLLM)在文档分析领域取得了显著进展。然而,现有的基准测试通常只关注提取文本和简单的布局信息,忽略了结构化文档(如思维导图和流程图)中元素之间复杂的交互。为了解决这个问题,我们推出了名为MindBench的新基准测试,它不仅包括精心构建的双语真实或合成图像、详细的注释、评估指标和基线模型,而且专门设计了五种类型的结构化理解和解析任务。这些任务包括完整解析、部分解析、位置相关解析、结构化视觉问答(VQA)和位置相关VQA,涵盖了文本识别、空间感知、关系辨别和结构化解析等关键领域。大量的实验结果表明,当前模型在处理结构化文档信息的能力方面具有巨大的潜力和显著的改进空间。我们预计MindBench的发布将显著推进结构化文档分析技术的研究和应用开发。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在结构化文档(如思维导图)理解方面的不足。现有方法主要关注文本和简单布局信息的提取,忽略了元素之间的复杂关系,导致无法有效解析和理解结构化文档的深层含义。因此,如何构建一个能够全面评估模型在结构化文档理解能力的基准测试成为了关键问题。
核心思路:论文的核心思路是构建一个包含多种结构化理解任务的综合性基准测试,即MindBench。该基准测试不仅包含精心构建的数据集,还设计了多种评估指标和基线模型,旨在全面评估模型在文本识别、空间感知、关系辨别和结构化解析等方面的能力。通过这些任务,可以更深入地了解模型在处理结构化文档信息方面的优势和不足。
技术框架:MindBench基准测试主要包含以下几个部分:1) 数据集构建:包括双语(真实和合成)思维导图图像,并进行详细的标注。2) 任务设计:设计了五种结构化理解和解析任务,包括完整解析、部分解析、位置相关解析、结构化视觉问答(VQA)和位置相关VQA。3) 评估指标:定义了用于评估模型在不同任务上的性能的指标。4) 基线模型:提供了在MindBench上进行评估的基线模型。整体流程是,模型接收思维导图图像作为输入,然后根据不同的任务要求进行处理,最后通过评估指标来衡量模型的性能。
关键创新:MindBench的关键创新在于其对结构化文档理解的全面性和深度。与现有基准测试相比,MindBench不仅关注文本和布局信息,更强调元素之间的关系和结构。通过设计多种结构化理解任务,MindBench能够更全面地评估模型在处理复杂结构化文档信息方面的能力。此外,MindBench还提供了双语数据集,有助于促进跨语言的结构化文档理解研究。
关键设计:MindBench的关键设计包括:1) 数据集的构建方式,如何生成真实和合成的思维导图图像,以及如何进行详细的标注。2) 五种结构化理解任务的具体定义和实现方式,例如,如何设计位置相关解析任务,以及如何构建结构化视觉问答(VQA)任务。3) 评估指标的选择,如何选择合适的指标来衡量模型在不同任务上的性能。4) 基线模型的选择和训练方式,如何选择具有代表性的模型,以及如何对其进行训练和优化。
🖼️ 关键图片
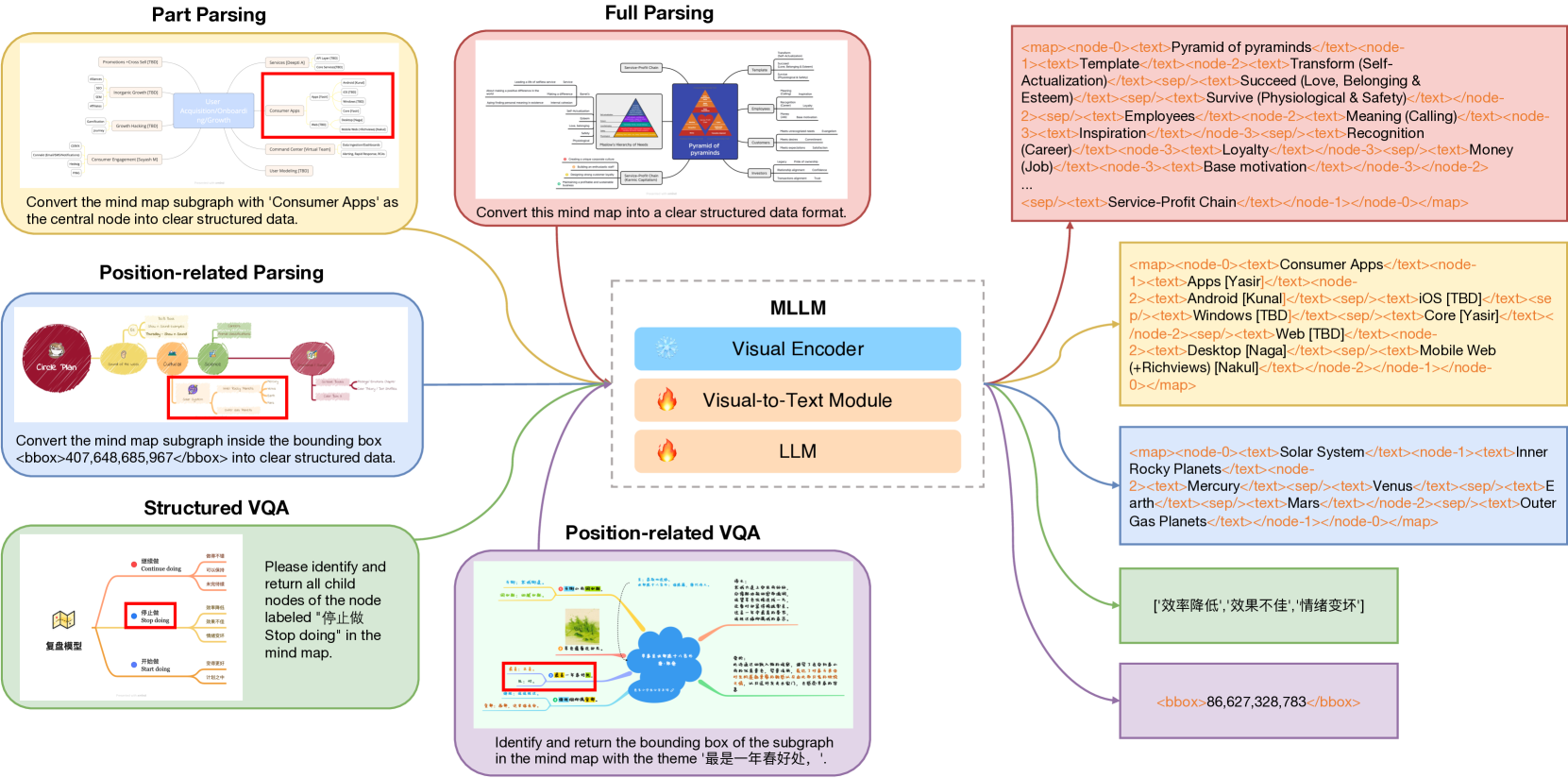

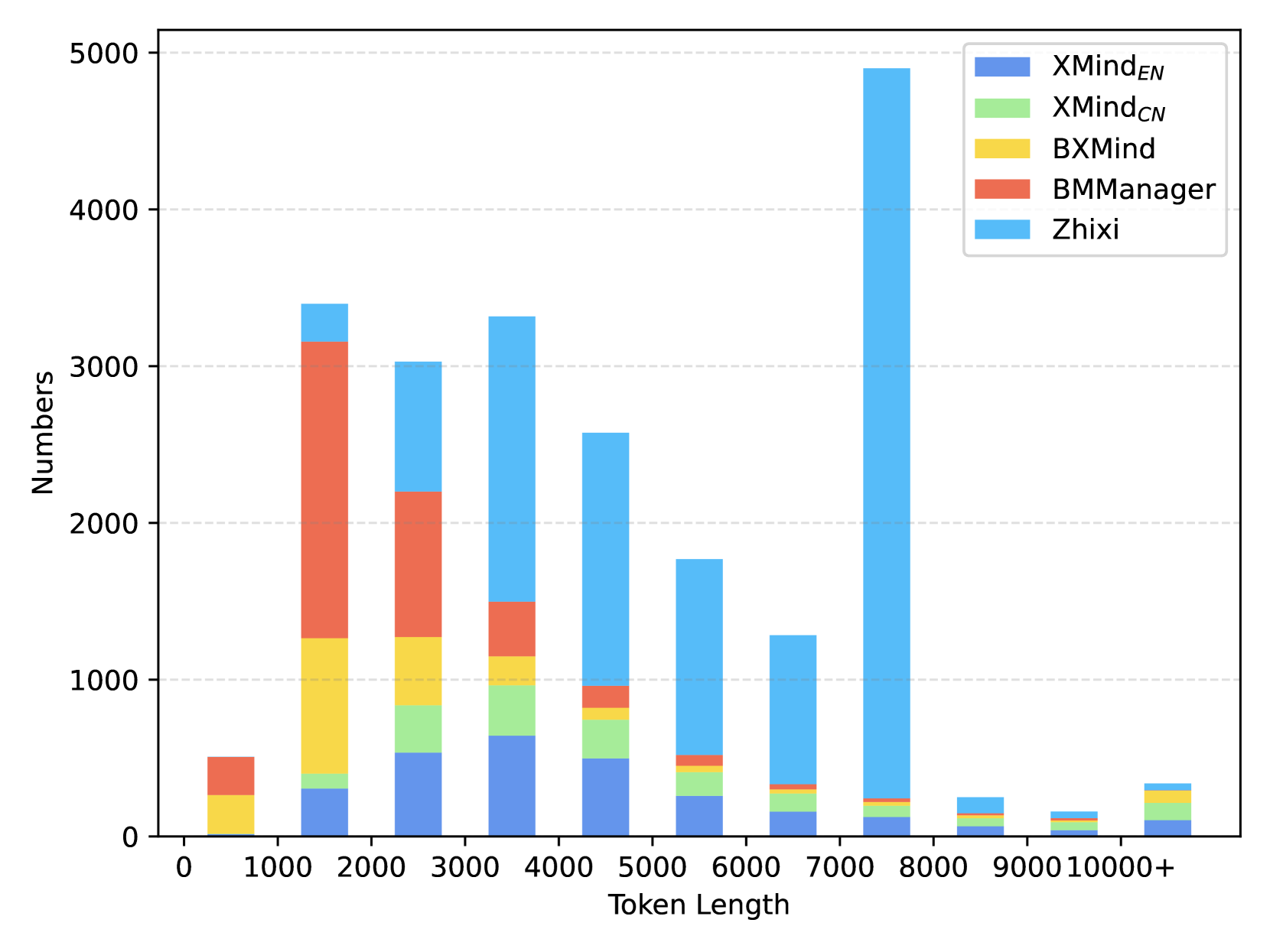
📊 实验亮点
实验结果表明,现有模型在MindBench基准测试上的性能仍有较大提升空间,尤其是在关系辨别和结构化解析任务上。例如,在完整解析任务上,现有模型的准确率仅为XX%,表明模型在理解复杂结构化文档方面仍存在挑战。MindBench的发布为研究者提供了一个新的平台,可以促进结构化文档分析技术的发展。
🎯 应用场景
MindBench的研究成果可广泛应用于办公自动化、教育、知识管理等领域。例如,可以帮助自动提取和理解思维导图中的信息,辅助用户进行知识整理和学习。在企业中,可以用于自动分析流程图和组织结构图,提高工作效率。未来,该技术有望应用于智能文档处理、信息检索和人机交互等领域,实现更智能化的文档理解和管理。
📄 摘要(原文)
Multimodal Large Language Models (MLLM) have made significant progress in the field of document analysis. Despite this, existing benchmarks typically focus only on extracting text and simple layout information, neglecting the complex interactions between elements in structured documents such as mind maps and flowcharts. To address this issue, we introduce the new benchmark named MindBench, which not only includes meticulously constructed bilingual authentic or synthetic images, detailed annotations, evaluation metrics and baseline models, but also specifically designs five types of structured understanding and parsing tasks. These tasks include full parsing, partial parsing, position-related parsing, structured Visual Question Answering (VQA), and position-related VQA, covering key areas such as text recognition, spatial awareness, relationship discernment, and structured parsing. Extensive experimental results demonstrate the substantial potential and significant room for improvement in current models' ability to handle structured document information. We anticipate that the launch of MindBench will significantly advance research and application development in structured document analysis technology. MindBench is available at: https://miasanlei.github.io/MindBench.github.io/.