PathGen-1.6M: 1.6 Million Pathology Image-text Pairs Generation through Multi-agent Collaboration
作者: Yuxuan Sun, Yunlong Zhang, Yixuan Si, Chenglu Zhu, Zhongyi Shui, Kai Zhang, Jingxiong Li, Xingheng Lyu, Tao Lin, Lin Yang
分类: cs.CV
发布日期: 2024-06-28
备注: 13 pages, 3 figures
💡 一句话要点
PathGen-1.6M:通过多智能体协作生成160万病理图像-文本对,提升病理VLM性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 病理图像分析 视觉语言模型 多模态学习 数据生成 全切片图像 零样本学习 多智能体协作
📋 核心要点
- 现有病理VLM训练依赖的数据集规模有限、质量不高,限制了模型性能。
- 利用大规模WSI数据集,通过多智能体协作生成高质量图像-文本对,构建PathGen-1.6M数据集。
- PathGen-CLIP在多个病理图像分析任务中显著提升性能,验证了生成数据对VLM训练的有效性。
📝 摘要(中文)
本文提出PathGen-1.6M,一个包含160万高质量病理图像-文本对的数据集,旨在解决现有病理视觉语言模型(VLM)训练数据有限且质量不高的问题。该方法利用大规模WSI数据集(如TCGA)提取高质量图像块,并训练大型多模态模型生成图像描述。通过多智能体模型协作,提取代表性WSI图像块,生成并优化描述,最终获得高质量图像-文本对。实验表明,将PathGen-1.6M与现有数据集结合训练的病理CLIP模型PathGen-CLIP,显著提升了病理图像分析能力,在九个病理相关零样本图像分类任务和三个全切片图像任务中均取得了显著改进。此外,基于PathGen-1.6M构建了20万条指令调优数据,并将PathGen-CLIP与Vicuna LLM集成,通过指令调优创建了更强大的多模态模型。该研究为病理学领域高质量数据生成提供了一种可扩展的途径,为下一代通用病理模型铺平了道路。
🔬 方法详解
问题定义:现有病理视觉语言模型(VLM)的训练依赖于从PubMed、YouTube和Twitter等平台获取的病理图像-文本对。这些数据存在规模有限、质量不高的问题,严重制约了病理VLM的性能提升。因此,如何获取大规模、高质量的病理图像-文本对成为一个关键挑战。
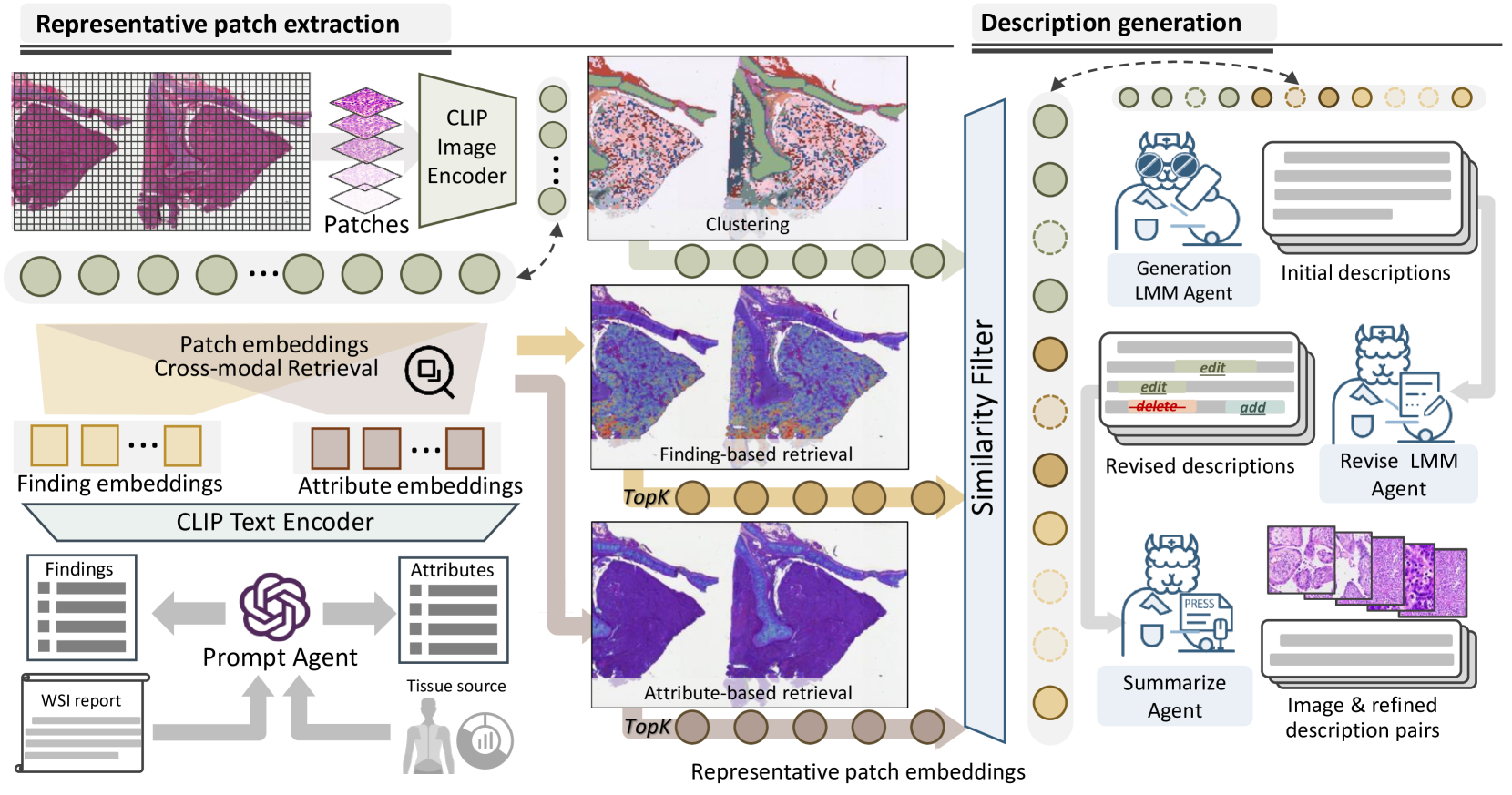
核心思路:本文的核心思路是利用大规模的全切片图像(WSI)数据集(如TCGA),从中提取大量高质量的图像块,并训练一个大型多模态模型来为这些图像块生成对应的文本描述。通过多智能体协作的方式,确保提取的图像块具有代表性,并且生成的文本描述准确、详细。
技术框架:整体框架包含以下几个主要阶段:1) 从大规模WSI数据集中提取图像块;2) 使用多智能体模型协作生成图像块的文本描述;3) 对生成的文本描述进行优化和筛选,确保质量;4) 构建包含160万高质量图像-文本对的PathGen-1.6M数据集;5) 使用PathGen-1.6M数据集训练病理CLIP模型PathGen-CLIP;6) 基于PathGen-1.6M构建指令调优数据,并与LLM集成,训练更强大的多模态模型。
关键创新:最重要的技术创新点在于使用多智能体协作的方式生成高质量的病理图像-文本对。与以往依赖人工标注或从互联网抓取数据的方法相比,该方法能够更高效、更可控地生成大规模、高质量的数据。此外,利用WSI数据提取图像块,保证了数据的多样性和代表性。
关键设计:多智能体协作的具体实现细节未知,论文中可能涉及智能体的数量、角色分配、协作方式等。损失函数和网络结构等细节也未在摘要中提及,属于未知信息。但可以推测,生成模型可能采用了Transformer架构,并使用了对比学习等技术来提高生成文本的质量。
🖼️ 关键图片

📊 实验亮点
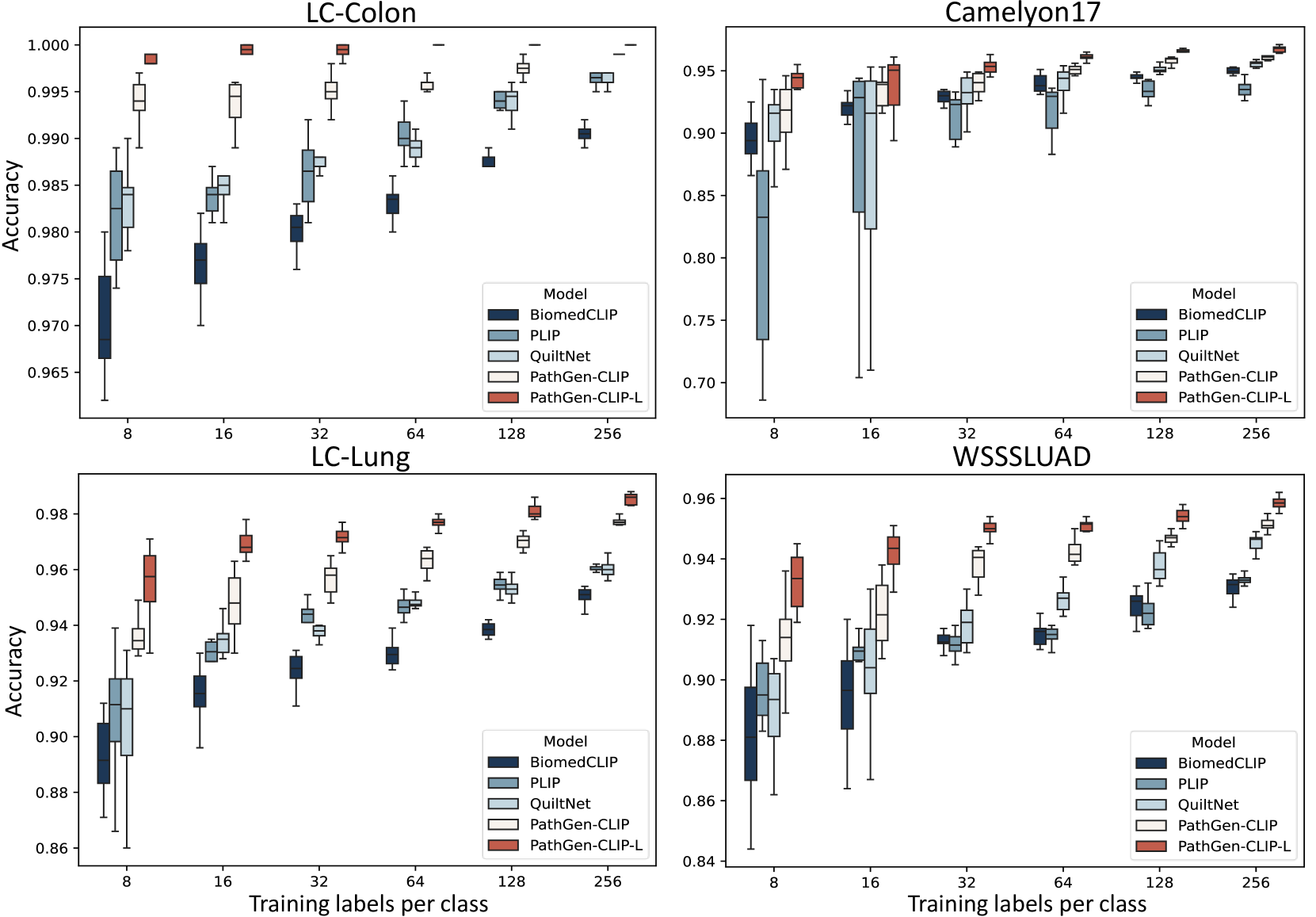
实验结果表明,使用PathGen-1.6M数据集训练的PathGen-CLIP模型,在九个病理相关零样本图像分类任务和三个全切片图像任务中均取得了显著改进。具体性能提升数据未知,但可以确定的是,PathGen-1.6M数据集的引入显著提升了病理VLM的性能。
🎯 应用场景
该研究成果可广泛应用于病理图像分析领域,例如零样本图像分类、全切片图像分析等。高质量的PathGen-1.6M数据集能够促进病理VLM的发展,提升疾病诊断的准确性和效率。未来,该方法还可扩展到其他医学影像领域,为构建更强大的医学人工智能系统提供数据支持。
📄 摘要(原文)
Vision Language Models (VLMs) like CLIP have attracted substantial attention in pathology, serving as backbones for applications such as zero-shot image classification and Whole Slide Image (WSI) analysis. Additionally, they can function as vision encoders when combined with large language models (LLMs) to support broader capabilities. Current efforts to train pathology VLMs rely on pathology image-text pairs from platforms like PubMed, YouTube, and Twitter, which provide limited, unscalable data with generally suboptimal image quality. In this work, we leverage large-scale WSI datasets like TCGA to extract numerous high-quality image patches. We then train a large multimodal model to generate captions for these images, creating PathGen-1.6M, a dataset containing 1.6 million high-quality image-caption pairs. Our approach involves multiple agent models collaborating to extract representative WSI patches, generating and refining captions to obtain high-quality image-text pairs. Extensive experiments show that integrating these generated pairs with existing datasets to train a pathology-specific CLIP model, PathGen-CLIP, significantly enhances its ability to analyze pathological images, with substantial improvements across nine pathology-related zero-shot image classification tasks and three whole-slide image tasks. Furthermore, we construct 200K instruction-tuning data based on PathGen-1.6M and integrate PathGen-CLIP with the Vicuna LLM to create more powerful multimodal models through instruction tuning. Overall, we provide a scalable pathway for high-quality data generation in pathology, paving the way for next-generation general pathology models.