ASSR-NeRF: Arbitrary-Scale Super-Resolution on Voxel Grid for High-Quality Radiance Fields Reconstruction
作者: Ding-Jiun Huang, Zi-Ting Chou, Yu-Chiang Frank Wang, Cheng Sun
分类: cs.CV
发布日期: 2024-06-28 (更新: 2025-12-16)
💡 一句话要点
提出ASSR-NeRF,通过体素网格上的任意尺度超分辨率实现高质量辐射场重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: NeRF 超分辨率 新视角合成 体素网格 注意力机制
📋 核心要点
- 现有NeRF方法在高分辨率新视角合成中,低分辨率优化易导致过度平滑,单图超分缺乏多视角一致性。
- ASSR-NeRF通过注意力机制的VoxelGridSR模型,直接在优化后的体素网格上进行3D超分辨率。
- 该模型在多样场景训练,保证泛化性;在未见场景上,可直接细化体素,实现多视角一致的超分辨率。
📝 摘要(中文)
本文提出了一种名为任意尺度超分辨率NeRF(ASSR-NeRF)的新框架,用于超分辨率新视角合成(SRNVS)。基于NeRF的方法通过构建具有隐式或显式表示的辐射场来重建3D场景。虽然基于NeRF的方法可以执行任意尺度的新视角合成(NVS),但在低分辨率(LR)优化的情况下进行高分辨率新视角合成(HRNVS)时,性能通常会导致过度平滑。另一方面,单图像超分辨率(SR)旨在将LR图像增强为HR图像,但缺乏多视角一致性。为了解决这些挑战,我们提出了基于注意力机制的VoxelGridSR模型,以直接在优化的体素上执行3D超分辨率(SR)。我们的模型在不同的场景上进行训练,以确保泛化能力。对于使用LR视图训练的未见场景,我们可以直接应用我们的VoxelGridSR来进一步细化体素并实现多视角一致的SR。实验结果表明,该方法在SRNVS中取得了显著的性能提升。
🔬 方法详解
问题定义:论文旨在解决在低分辨率图像上训练的NeRF模型,进行高分辨率新视角合成时,出现的过度平滑问题。同时,单张图像的超分辨率方法缺乏多视角一致性,无法直接应用于NeRF场景重建。因此,需要一种能够同时实现高分辨率和多视角一致性的超分辨率新视角合成方法。
核心思路:论文的核心思路是利用体素网格作为NeRF的显式表示,并在此基础上进行3D超分辨率。通过训练一个基于注意力机制的VoxelGridSR模型,直接在优化的体素网格上进行超分辨率操作,从而避免了传统NeRF方法中隐式表示带来的模糊问题,并保证了多视角一致性。
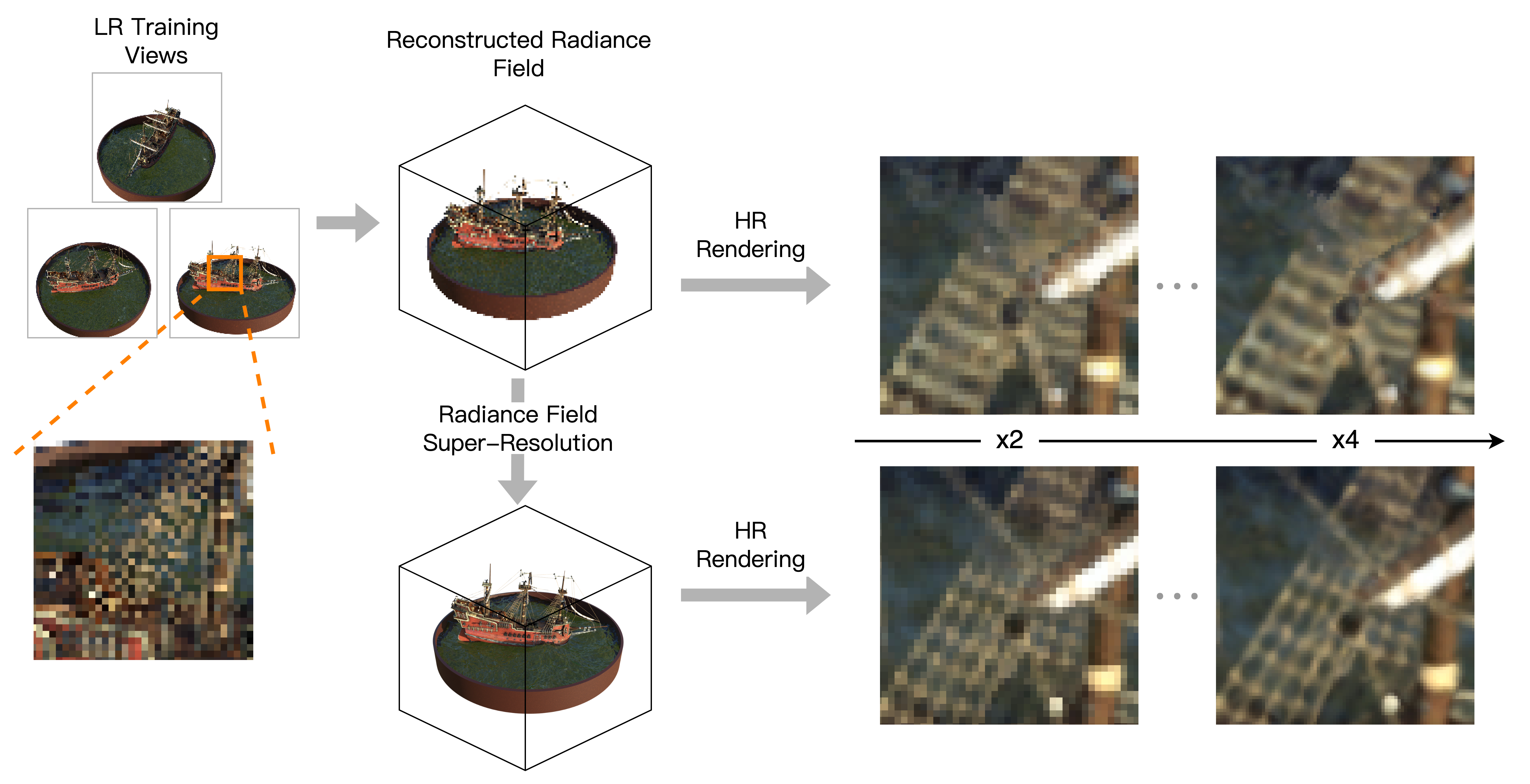
技术框架:ASSR-NeRF的整体框架包含以下几个主要阶段:1) 使用低分辨率图像训练NeRF模型,得到优化的体素网格表示;2) 使用训练好的VoxelGridSR模型,对体素网格进行超分辨率处理;3) 使用超分辨率后的体素网格进行新视角合成。VoxelGridSR模型是整个框架的核心,负责将低分辨率的体素网格提升到高分辨率,并保持多视角一致性。
关键创新:论文最重要的技术创新点在于提出了VoxelGridSR模型,该模型能够直接在3D体素网格上进行超分辨率操作。与传统的基于图像的超分辨率方法不同,VoxelGridSR模型能够利用体素网格的3D结构信息,从而更好地保持多视角一致性。此外,该模型还采用了注意力机制,能够自适应地关注重要的体素区域,从而提高超分辨率的质量。
关键设计:VoxelGridSR模型采用了一个3D卷积神经网络,并加入了注意力机制。具体的网络结构未知,但可以推测其包含多个3D卷积层、池化层和上采样层,用于提取体素网格的特征并进行超分辨率。损失函数的设计也至关重要,可能包括L1损失、L2损失以及感知损失等,用于衡量超分辨率结果与真实高分辨率体素网格之间的差异。注意力机制的具体实现方式未知,但可以推测其通过学习一个注意力权重矩阵,来对不同的体素区域进行加权。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,ASSR-NeRF在超分辨率新视角合成任务中取得了显著的性能提升。具体的数据和对比基线未知,但摘要中提到该方法在定量和定性上都优于现有方法,表明其在生成高质量、多视角一致的新视角图像方面具有优势。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、游戏开发等领域,提升3D场景的视觉质量和沉浸感。例如,在VR游戏中,可以使用该方法将低分辨率的3D模型提升到高分辨率,从而提高游戏的画面质量。此外,该方法还可以应用于遥感图像处理、医学图像分析等领域,提高图像的分辨率和清晰度。
📄 摘要(原文)
NeRF-based methods reconstruct 3D scenes by building a radiance field with implicit or explicit representations. While NeRF-based methods can perform novel view synthesis (NVS) at arbitrary scale, the performance in high-resolution novel view synthesis (HRNVS) with low-resolution (LR) optimization often results in oversmoothing. On the other hand, single-image super-resolution (SR) aims to enhance LR images to HR counterparts but lacks multi-view consistency. To address these challenges, we propose Arbitrary-Scale Super-Resolution NeRF (ASSR-NeRF), a novel framework for super-resolution novel view synthesis (SRNVS). We propose an attention-based VoxelGridSR model to directly perform 3D super-resolution (SR) on the optimized volume. Our model is trained on diverse scenes to ensure generalizability. For unseen scenes trained with LR views, we then can directly apply our VoxelGridSR to further refine the volume and achieve multi-view consistent SR. We demonstrate quantitative and qualitatively that the proposed method achieves significant performance in SRNVS.