MM-Instruct: Generated Visual Instructions for Large Multimodal Model Alignment
作者: Jihao Liu, Xin Huang, Jinliang Zheng, Boxiao Liu, Jia Wang, Osamu Yoshie, Yu Liu, Hongsheng Li
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-06-28
备注: Dataset and models are available at https://github.com/jihaonew/MM-Instruct
🔗 代码/项目: GITHUB
💡 一句话要点
MM-Instruct:生成视觉指令数据,提升大型多模态模型指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉指令 大型语言模型 指令遵循 数据集生成
📋 核心要点
- 现有视觉指令数据集主要集中于问答,缺乏在创意写作、图像分析等更广泛场景的泛化能力。
- 利用大型语言模型(LLM)的指令遵循能力,从图像描述数据集中自动生成多样化和高质量的视觉指令数据。
- 通过在生成的MM-Instruct数据上训练LLaVA-1.5模型,显著提升了模型在指令遵循方面的性能。
📝 摘要(中文)
本文提出了MM-Instruct,一个大规模、多样化和高质量的视觉指令数据集,旨在增强大型多模态模型(LMMs)的指令遵循能力。现有的视觉指令数据集通常侧重于问答,难以泛化到更广泛的应用场景,如创意写作、摘要或图像分析。为了解决这些局限性,我们提出了一种新方法来构建MM-Instruct,该方法利用现有LLM强大的指令遵循能力,从大规模但传统的图像描述数据集中生成新的视觉指令数据。MM-Instruct首先利用ChatGPT通过增强和总结,从一小组种子指令中自动生成多样化的指令。然后,它将这些指令与图像匹配,并使用开源的大型语言模型(LLM)生成与指令-图像对一致的答案。在整个答案生成过程中,LLM以图像的详细文本描述为基础,以保证指令数据的一致性。此外,我们基于生成的指令数据引入了一个基准,以评估现有LMM的指令遵循能力。我们通过在生成的数据上训练LLaVA-1.5模型(表示为LLaVA-Instruct)证明了MM-Instruct的有效性,与LLaVA-1.5模型相比,该模型在指令遵循能力方面表现出显著的改进。MM-Instruct数据集、基准和预训练模型可在https://github.com/jihaonew/MM-Instruct上获得。
🔬 方法详解
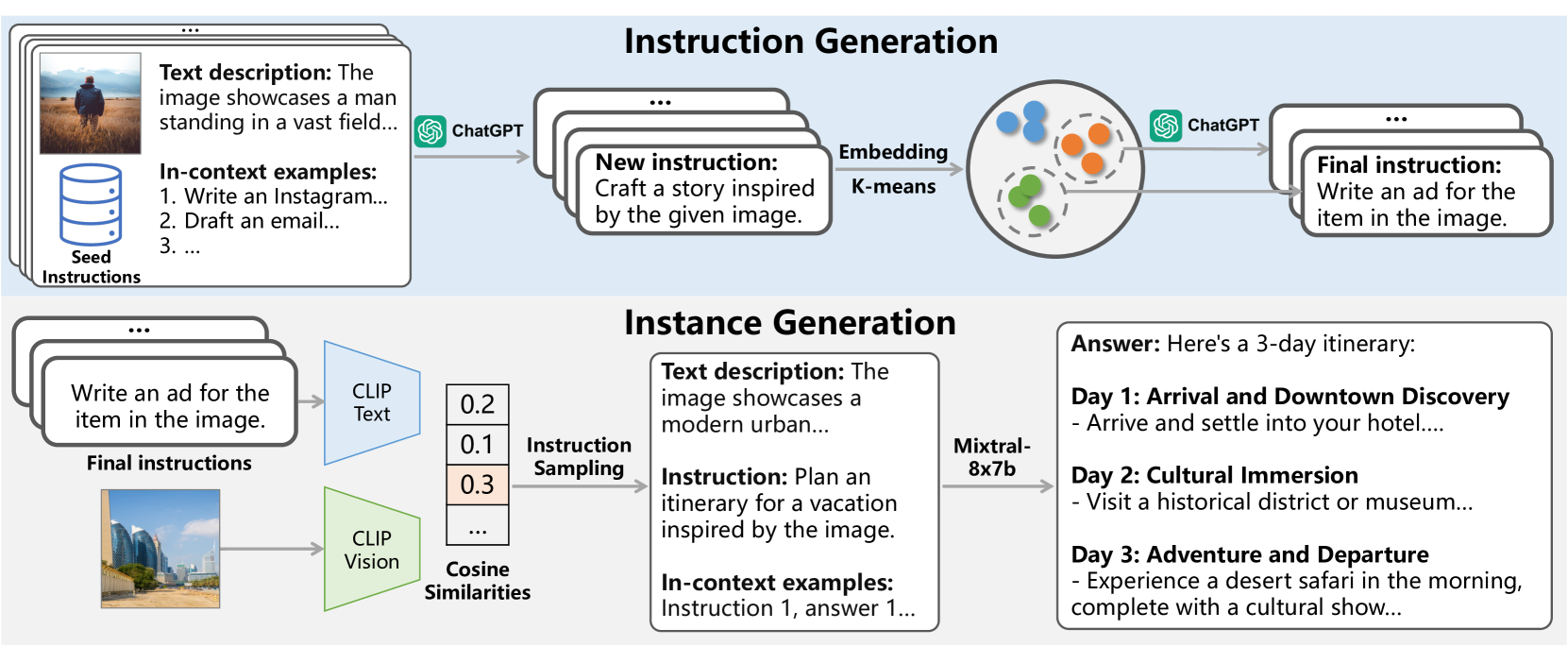
问题定义:现有视觉指令数据集主要集中于问答任务,缺乏对创意写作、图像分析等更广泛应用场景的泛化能力。这限制了大型多模态模型(LMMs)在实际应用中的潜力。因此,需要构建一个更通用、多样化的视觉指令数据集,以提升LMMs的指令遵循能力。
核心思路:利用现有大型语言模型(LLMs)强大的指令遵循能力,自动生成视觉指令数据。具体来说,利用LLMs从图像描述数据集中生成多样化的指令和对应的答案,从而构建大规模的视觉指令数据集。这种方法避免了人工标注的成本,并能够生成更丰富、更具创造性的指令。
技术框架:MM-Instruct的构建流程主要包括以下几个阶段:1) 指令生成:利用ChatGPT从少量种子指令中生成多样化的指令,通过增强和总结等方式扩展指令集。2) 指令匹配:将生成的指令与图像进行匹配,形成指令-图像对。3) 答案生成:使用开源LLM,以图像的文本描述为基础,生成与指令-图像对一致的答案。整个过程保证了指令、图像和答案之间的一致性。
关键创新:核心创新在于利用LLM的生成能力,自动构建大规模、多样化的视觉指令数据集。与传统的人工标注方法相比,该方法能够显著降低成本,并生成更具创造性的指令。此外,该方法还引入了一个基于生成数据的基准,用于评估LMMs的指令遵循能力。
关键设计:在指令生成阶段,使用了ChatGPT进行指令的增强和总结,以生成更多样化的指令。在答案生成阶段,LLM以图像的文本描述为基础,保证了答案与图像内容的一致性。具体使用的LLM模型和参数设置在论文中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
通过在MM-Instruct数据集上训练LLaVA-1.5模型(LLaVA-Instruct),实验结果表明,该模型在指令遵循能力方面取得了显著提升。具体的性能数据和对比基线未在摘要中给出,需要参考论文正文获取更详细的实验结果。
🎯 应用场景
该研究成果可广泛应用于各种需要多模态理解和指令遵循的场景,例如智能助手、图像编辑、创意内容生成、教育和医疗诊断等。通过提升LMMs的指令遵循能力,可以实现更自然、更智能的人机交互,并为各种应用提供更强大的支持。
📄 摘要(原文)
This paper introduces MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). While existing visual instruction datasets often focus on question-answering, they struggle to generalize to broader application scenarios such as creative writing, summarization, or image analysis. To address these limitations, we propose a novel approach to constructing MM-Instruct that leverages the strong instruction-following capabilities of existing LLMs to generate novel visual instruction data from large-scale but conventional image captioning datasets. MM-Instruct first leverages ChatGPT to automatically generate diverse instructions from a small set of seed instructions through augmenting and summarization. It then matches these instructions with images and uses an open-sourced large language model (LLM) to generate coherent answers to the instruction-image pairs. The LLM is grounded by the detailed text descriptions of images in the whole answer generation process to guarantee the alignment of the instruction data. Moreover, we introduce a benchmark based on the generated instruction data to evaluate the instruction-following capabilities of existing LMMs. We demonstrate the effectiveness of MM-Instruct by training a LLaVA-1.5 model on the generated data, denoted as LLaVA-Instruct, which exhibits significant improvements in instruction-following capabilities compared to LLaVA-1.5 models. The MM-Instruct dataset, benchmark, and pre-trained models are available at https://github.com/jihaonew/MM-Instruct.