OMG-LLaVA: Bridging Image-level, Object-level, Pixel-level Reasoning and Understanding
作者: Tao Zhang, Xiangtai Li, Hao Fei, Haobo Yuan, Shengqiong Wu, Shunping Ji, Chen Change Loy, Shuicheng Yan
分类: cs.CV
发布日期: 2024-06-27 (更新: 2024-10-01)
备注: NeurIPS-2024. Project page: https://lxtgh.github.io/project/omg_llava/
💡 一句话要点
OMG-LLaVA:融合图像、对象和像素级推理与理解的多模态模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 像素级理解 图像分割 推理能力 感知先验 端到端训练
📋 核心要点
- 现有方法或缺乏推理能力,或缺乏像素级理解,难以兼顾图像、对象和像素级别的理解与推理。
- OMG-LLaVA通过结合通用分割模型和大型语言模型,实现对图像的全面理解和灵活的用户交互。
- OMG-LLaVA在多个基准测试中表现出色,证明了其在多粒度视觉理解方面的有效性。
📝 摘要(中文)
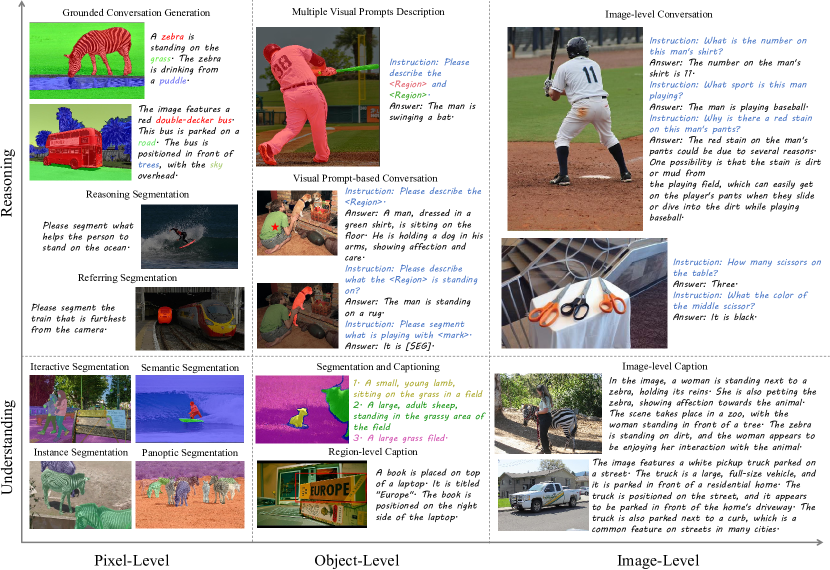
本文提出了一种名为OMG-LLaVA的新框架,旨在结合强大的像素级视觉理解能力与推理能力。现有通用分割方法在像素级图像和视频理解方面表现出色,但缺乏推理能力,且无法通过文本指令进行控制。而大型视觉-语言多模态模型虽然具备强大的基于视觉的对话和推理能力,但缺乏像素级理解,且难以接受视觉提示以实现灵活的用户交互。OMG-LLaVA使用通用分割方法作为视觉编码器,将图像信息、感知先验和视觉提示集成到提供给LLM的视觉tokens中。LLM负责理解用户的文本指令,并根据视觉信息提供文本响应和像素级分割结果。本文提出了感知先验嵌入,以更好地将感知先验与图像特征集成。OMG-LLaVA在单个模型中实现了图像级、对象级和像素级推理与理解,在多个基准测试中达到或超过了专用方法的性能。该工作旨在通过在一个编码器、一个解码器和一个LLM上进行端到端训练,而非使用LLM连接各个专家模型。代码和模型已发布,供进一步研究。
🔬 方法详解
问题定义:现有通用分割方法虽然在像素级图像和视频理解方面表现出色,但缺乏推理能力,无法根据文本指令进行控制。另一方面,大型视觉-语言模型虽然具备强大的视觉推理能力,但缺乏像素级理解,难以接受视觉提示。
核心思路:OMG-LLaVA的核心思路是将像素级的视觉理解能力与大型语言模型的推理能力相结合,从而实现对图像的多粒度理解和灵活的用户交互。通过通用分割模型提取像素级特征,并将其与图像级信息和用户提示相结合,输入到大型语言模型中进行推理。
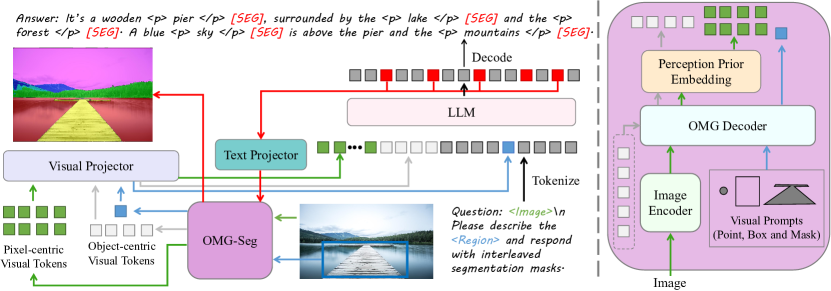
技术框架:OMG-LLaVA的整体框架包含一个通用分割模型作为视觉编码器,一个大型语言模型(LLM)作为推理引擎。视觉编码器负责提取图像的像素级特征,并将图像信息、感知先验和视觉提示编码为视觉tokens。这些tokens与用户的文本指令一起输入到LLM中。LLM负责理解用户的指令,并生成文本响应和像素级分割结果。
关键创新:OMG-LLaVA的关键创新在于将像素级视觉理解与大型语言模型的推理能力相结合,从而实现对图像的多粒度理解。此外,该模型还提出了感知先验嵌入,以更好地将感知先验与图像特征集成。与以往使用LLM连接多个专家模型的方法不同,OMG-LLaVA采用端到端训练的方式,在一个编码器、一个解码器和一个LLM上进行训练。
关键设计:OMG-LLaVA的关键设计包括:1) 使用通用分割模型作为视觉编码器,提取像素级特征;2) 提出感知先验嵌入,以更好地将感知先验与图像特征集成;3) 采用端到端训练的方式,优化整个模型。
🖼️ 关键图片

📊 实验亮点
OMG-LLaVA在多个基准测试中表现出色,证明了其在多粒度视觉理解方面的有效性。具体性能数据和对比基线未在摘要中明确给出,但强调了该模型达到或超过了专用方法的性能。该模型在图像级、对象级和像素级推理与理解方面都取得了显著进展。
🎯 应用场景
OMG-LLaVA具有广泛的应用前景,例如智能图像编辑、视觉问答、机器人导航、自动驾驶等。该模型可以根据用户的文本指令,对图像进行精确的像素级操作,从而实现更加智能和灵活的人机交互。此外,该模型还可以用于辅助机器人理解周围环境,从而实现更加智能的导航和控制。
📄 摘要(原文)
Current universal segmentation methods demonstrate strong capabilities in pixel-level image and video understanding. However, they lack reasoning abilities and cannot be controlled via text instructions. In contrast, large vision-language multimodal models exhibit powerful vision-based conversation and reasoning capabilities but lack pixel-level understanding and have difficulty accepting visual prompts for flexible user interaction. This paper proposes OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation method as the visual encoder, integrating image information, perception priors, and visual prompts into visual tokens provided to the LLM. The LLM is responsible for understanding the user's text instructions and providing text responses and pixel-level segmentation results based on the visual information. We propose perception prior embedding to better integrate perception priors with image features. OMG-LLaVA achieves image-level, object-level, and pixel-level reasoning and understanding in a single model, matching or surpassing the performance of specialized methods on multiple benchmarks. Rather than using LLM to connect each specialist, our work aims at end-to-end training on one encoder, one decoder, and one LLM. The code and model have been released for further research.