Mamba or RWKV: Exploring High-Quality and High-Efficiency Segment Anything Model
作者: Haobo Yuan, Xiangtai Li, Lu Qi, Tao Zhang, Ming-Hsuan Yang, Shuicheng Yan, Chen Change Loy
分类: cs.CV
发布日期: 2024-06-27
备注: 16 pages; 8 figures
💡 一句话要点
提出RWKV-SAM:一种高效且高质量的Segment Anything模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图像分割 线性注意力 RWKV Mamba 高效推理 Segment Anything 混合架构
📋 核心要点
- Transformer分割模型处理高分辨率图像时效率低,是当前面临的核心问题。
- 论文提出混合卷积和RWKV操作的骨干网络,并设计高效解码器,兼顾精度与效率。
- RWKV-SAM在效率和分割质量上优于Transformer和Mamba,加速超2倍,性能更优。
📝 摘要(中文)
基于Transformer的分割方法在高分辨率图像处理时面临推理效率的挑战。最近,诸如Mamba和RWKV等线性注意力架构因其高效处理长序列的能力而备受关注。本文着重于通过探索这些不同的架构来设计一种高效的Segment Anything模型。具体而言,我们设计了一种包含卷积和RWKV操作的混合骨干网络,从而在准确性和效率之间实现了最佳平衡。此外,我们设计了一种高效的解码器,以利用多尺度token来获得高质量的掩码。我们将我们的方法命名为RWKV-SAM,它为类SAM模型提供了一个简单、有效且快速的基线。此外,我们构建了一个包含各种高质量分割数据集的基准,并使用该基准联合训练一个高效且高质量的分割模型。基于基准测试结果,与Transformer和其他线性注意力模型相比,我们的RWKV-SAM在效率和分割质量方面均表现出色。例如,与相同规模的Transformer模型相比,RWKV-SAM实现了超过2倍的加速,并且可以在各种数据集上实现更好的分割性能。此外,RWKV-SAM在分类和语义分割结果方面优于最近的视觉Mamba模型。代码和模型将公开。
🔬 方法详解
问题定义:现有基于Transformer的分割方法在处理高分辨率图像时,计算复杂度高,推理效率低,难以满足实际应用的需求。线性注意力机制(如Mamba和RWKV)虽然在处理长序列上具有优势,但如何将其有效应用于图像分割任务,并达到与Transformer相当甚至更高的性能,是一个挑战。
核心思路:论文的核心思路是利用RWKV的线性注意力机制来替代Transformer中的自注意力机制,从而降低计算复杂度,提高推理效率。同时,通过混合卷积和RWKV操作,结合两者的优势,在保证分割精度的前提下,显著提升模型的运行速度。
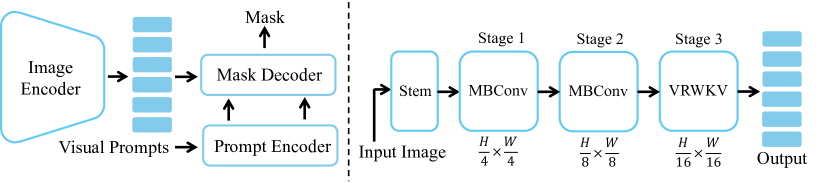
技术框架:RWKV-SAM的整体架构包含一个混合骨干网络和一个高效解码器。骨干网络由卷积层和RWKV层交替堆叠而成,用于提取图像的多尺度特征。解码器则利用这些多尺度特征来生成高质量的分割掩码。整个流程类似于SAM(Segment Anything Model),但使用了更高效的线性注意力机制。
关键创新:该论文的关键创新在于将RWKV架构引入到Segment Anything模型中,并设计了一种混合卷积和RWKV操作的骨干网络。这种混合结构能够充分利用卷积的局部特征提取能力和RWKV的全局依赖建模能力,从而在精度和效率之间取得平衡。
关键设计:骨干网络的关键设计在于卷积层和RWKV层的比例和排列方式,需要根据具体的任务和数据集进行调整。解码器的设计也至关重要,需要有效地融合多尺度特征,并生成高质量的分割掩码。此外,论文还构建了一个包含多个高质量分割数据集的基准,用于联合训练和评估模型。
🖼️ 关键图片
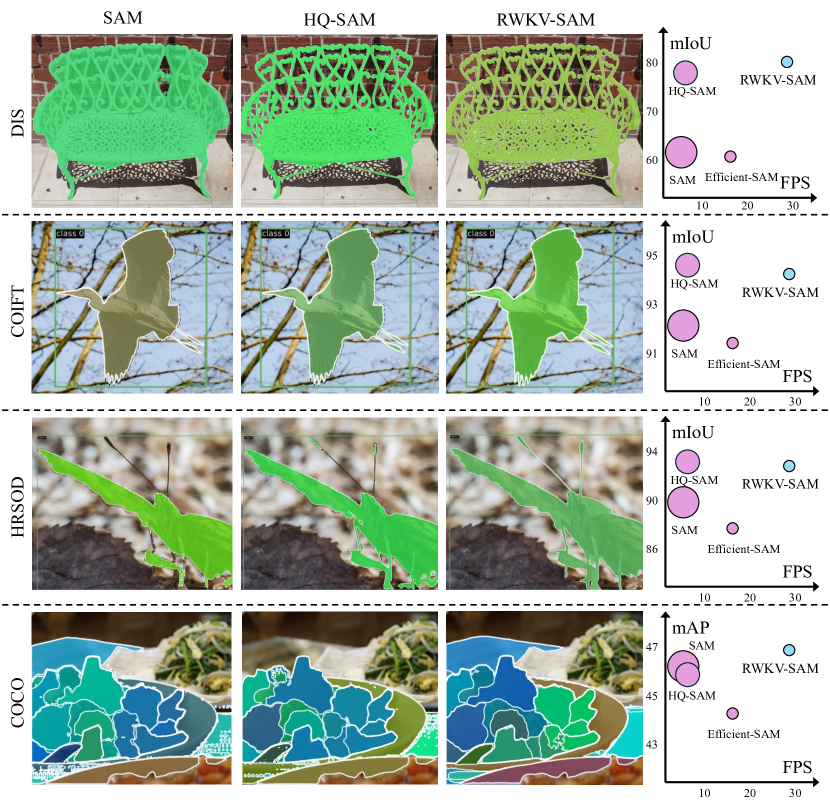
📊 实验亮点
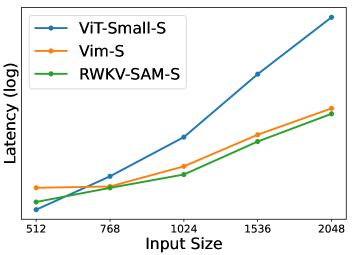
RWKV-SAM在多个分割数据集上取得了优异的性能,与相同规模的Transformer模型相比,实现了超过2倍的加速,并且在分割精度上有所提升。此外,RWKV-SAM在分类和语义分割任务上也优于最近的视觉Mamba模型,证明了其在视觉任务上的通用性。
🎯 应用场景
RWKV-SAM具有广泛的应用前景,包括自动驾驶、医学图像分析、遥感图像处理等领域。其高效的推理能力使其能够应用于实时性要求较高的场景,例如实时视频分割。该研究有助于推动分割模型在资源受限设备上的部署,并促进相关技术的普及。
📄 摘要(原文)
Transformer-based segmentation methods face the challenge of efficient inference when dealing with high-resolution images. Recently, several linear attention architectures, such as Mamba and RWKV, have attracted much attention as they can process long sequences efficiently. In this work, we focus on designing an efficient segment-anything model by exploring these different architectures. Specifically, we design a mixed backbone that contains convolution and RWKV operation, which achieves the best for both accuracy and efficiency. In addition, we design an efficient decoder to utilize the multiscale tokens to obtain high-quality masks. We denote our method as RWKV-SAM, a simple, effective, fast baseline for SAM-like models. Moreover, we build a benchmark containing various high-quality segmentation datasets and jointly train one efficient yet high-quality segmentation model using this benchmark. Based on the benchmark results, our RWKV-SAM achieves outstanding performance in efficiency and segmentation quality compared to transformers and other linear attention models. For example, compared with the same-scale transformer model, RWKV-SAM achieves more than 2x speedup and can achieve better segmentation performance on various datasets. In addition, RWKV-SAM outperforms recent vision Mamba models with better classification and semantic segmentation results. Code and models will be publicly available.