3D Feature Distillation with Object-Centric Priors
作者: Georgios Tziafas, Yucheng Xu, Zhibin Li, Hamidreza Kasaei
分类: cs.CV, cs.RO
发布日期: 2024-06-26 (更新: 2025-08-25)
💡 一句话要点
提出基于物体中心先验的3D特征蒸馏方法,提升单视角RGB-D图像的语言引导机器人操作性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D特征蒸馏 物体中心先验 多视角融合 机器人操作 单视角RGB-D
📋 核心要点
- 现有3D特征蒸馏方法泛化性差,或依赖多视角数据,不适用于单视角机器人操作场景。
- 利用物体中心先验,通过实例分割掩码在物体级别融合特征,消除无信息量的视角。
- 构建大规模合成数据集,实验证明该方法提升了3D特征的定位能力和空间一致性。
📝 摘要(中文)
本文提出了一种基于物体中心先验的3D特征蒸馏方法,旨在提升自然语言在物理世界中的定位能力,尤其是在机器人操作场景中。现有方法通常依赖于场景特定的神经场或需要多视角图像,且在像素级别融合特征,忽略了不同视角的信息量差异。为了解决这些问题,本文提出了一种多视角特征融合策略,利用物体中心先验,基于语义信息消除无信息量的视角,并通过实例分割掩码在物体级别融合特征。此外,本文构建了一个大规模合成多视角数据集,包含15k个场景和3300多个独特物体实例。实验结果表明,该方法能够重建具有改进的定位能力和空间一致性的3D CLIP特征,且仅需单视角RGB-D图像。该方法还可推广到新的桌面领域,并用于3D实例分割和语言引导的机器人抓取。
🔬 方法详解
问题定义:现有方法在将2D CLIP特征提升到3D时,存在以下痛点:一是场景泛化能力不足,依赖于场景特定的神经场;二是需要多视角图像,不适用于单视角机器人操作场景;三是在像素级别融合特征,忽略了不同视角的信息量差异,导致次优的3D特征。
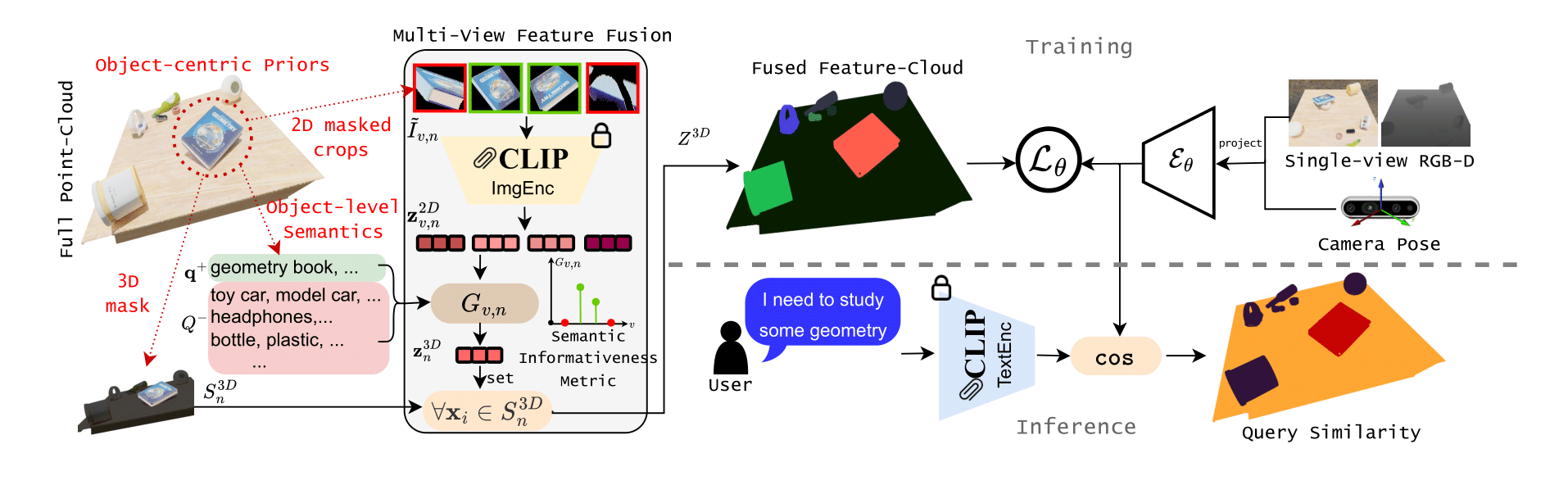
核心思路:本文的核心思路是利用物体中心先验,通过实例分割掩码将特征融合限制在相关的物体区域,并根据语义信息选择信息量大的视角进行融合。这种方法可以减少噪声,提高特征的空间一致性和定位精度。
技术框架:该方法主要包含以下几个阶段:1. 输入单视角RGB-D图像;2. 使用实例分割模型提取物体级别的掩码;3. 使用2D CLIP模型提取图像特征;4. 基于物体中心先验,选择信息量大的视角,并使用实例分割掩码在物体级别融合特征;5. 将融合后的特征蒸馏到3D空间。
关键创新:最重要的技术创新点在于使用物体中心先验进行多视角特征融合。与现有方法直接在像素级别融合所有视角的信息不同,该方法根据语义信息选择信息量大的视角,并使用实例分割掩码将特征融合限制在相关的物体区域,从而提高了特征的质量。
关键设计:该方法的关键设计包括:1. 大规模合成数据集的构建,用于训练和评估模型;2. 物体中心先验的定义和使用,用于选择信息量大的视角;3. 实例分割掩码的使用,用于在物体级别融合特征;4. 损失函数的设计,用于保证蒸馏后的3D特征具有良好的定位能力和空间一致性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在3D特征重建方面取得了显著的提升,尤其是在定位能力和空间一致性方面。此外,该方法还能够推广到新的桌面领域,并用于3D实例分割和语言引导的机器人抓取,无需进行额外的微调。这表明该方法具有良好的泛化能力和实用价值。
🎯 应用场景
该研究成果可广泛应用于机器人操作、增强现实、虚拟现实等领域。例如,在机器人操作中,该方法可以帮助机器人理解自然语言指令,并准确地定位和抓取目标物体。在增强现实和虚拟现实中,该方法可以用于构建更加逼真的3D场景,并实现更加自然的交互。
📄 摘要(原文)
Grounding natural language to the physical world is a ubiquitous topic with a wide range of applications in computer vision and robotics. Recently, 2D vision-language models such as CLIP have been widely popularized, due to their impressive capabilities for open-vocabulary grounding in 2D images. Recent works aim to elevate 2D CLIP features to 3D via feature distillation, but either learn neural fields that are scene-specific and hence lack generalization, or focus on indoor room scan data that require access to multiple camera views, which is not practical in robot manipulation scenarios. Additionally, related methods typically fuse features at pixel-level and assume that all camera views are equally informative. In this work, we show that this approach leads to sub-optimal 3D features, both in terms of grounding accuracy, as well as segmentation crispness. To alleviate this, we propose a multi-view feature fusion strategy that employs object-centric priors to eliminate uninformative views based on semantic information, and fuse features at object-level via instance segmentation masks. To distill our object-centric 3D features, we generate a large-scale synthetic multi-view dataset of cluttered tabletop scenes, spawning 15k scenes from over 3300 unique object instances, which we make publicly available. We show that our method reconstructs 3D CLIP features with improved grounding capacity and spatial consistency, while doing so from single-view RGB-D, thus departing from the assumption of multiple camera views at test time. Finally, we show that our approach can generalize to novel tabletop domains and be re-purposed for 3D instance segmentation without fine-tuning, and demonstrate its utility for language-guided robotic grasping in clutter.