Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
作者: Nikolaos Dionelis, Casper Fibaek, Luke Camilleri, Andreas Luyts, Jente Bosmans, Bertrand Le Saux
分类: cs.CV, cs.LG
发布日期: 2024-06-26
备注: 5 pages, 2 figures, Submitted
💡 一句话要点
提出地球观测基础模型评估基准,提升遥感任务的标签效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 地球观测 基础模型 遥感 地理空间AI 评估基准
📋 核心要点
- 现有遥感任务模型通常是特定问题定制,泛化能力弱,难以适应新的地理区域或数据分布。
- 本文提出利用基础模型解决遥感问题,并构建评估基准,以促进不同基础模型在地球观测领域的公平比较。
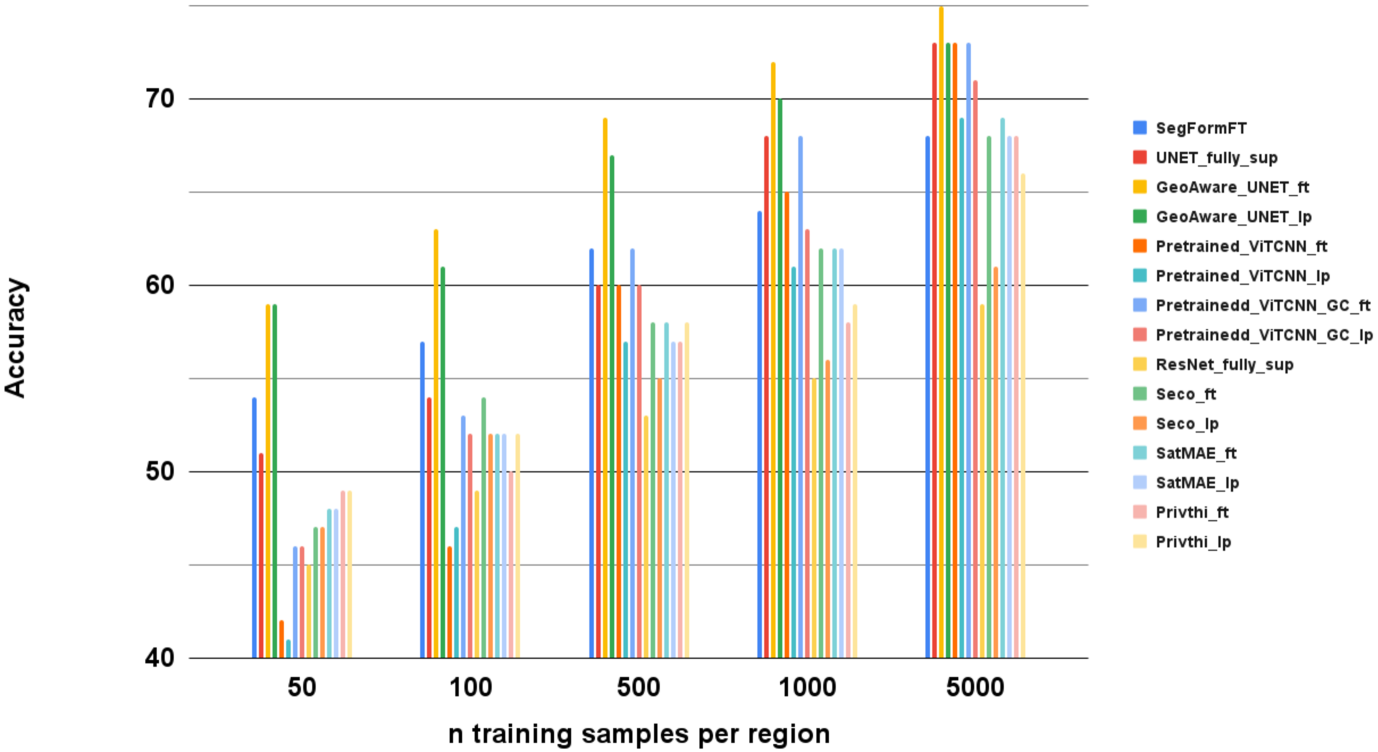
- 实验结果表明,基础模型在有限标注数据下,相比特定任务模型表现更优,验证了其在遥感任务中的标签效率。
📝 摘要(中文)
本文研究了地球观测(EO)和地理空间AI领域的基础模型,旨在解决土地覆盖分类、作物类型映射、洪水分割、建筑密度估计和道路回归分割等重要问题。研究表明,在有限的标注数据下,基础模型相比于特定任务模型能够取得更好的性能。此外,本文提出了一个用于评估EO基础模型的基准,旨在标准化不同模型之间的公平比较。实验结果表明,基础模型在下游任务中具有标签高效性,有助于解决EO和遥感领域的问题。
🔬 方法详解
问题定义:论文旨在解决地球观测和地理空间AI领域中,特定任务模型泛化能力不足的问题。现有方法通常针对特定应用场景进行优化,难以适应新的地理区域、数据分布或任务类型,需要大量的标注数据进行重新训练,成本高昂。
核心思路:论文的核心思路是利用预训练的基础模型,通过少量标注数据进行微调,从而实现快速适应新的遥感任务。基础模型通过在大规模数据集上进行预训练,学习到通用的图像特征表示,从而具备较强的泛化能力。
技术框架:论文提出了一个用于评估地球观测基础模型的基准。该基准包含多个遥感数据集和任务,涵盖土地覆盖分类、作物类型映射、洪水分割、建筑密度估计和道路回归分割等。研究者可以使用该基准来评估不同基础模型在遥感任务上的性能,并进行公平比较。
关键创新:论文的关键创新在于提出了一个专门针对地球观测领域的基础模型评估基准。该基准考虑了遥感数据的特殊性,例如高分辨率、多光谱等特点,能够更准确地评估基础模型在遥感任务上的性能。此外,论文还验证了基础模型在遥感任务中的标签效率,即在少量标注数据下即可取得较好的性能。
关键设计:论文没有详细描述具体的基础模型架构或训练细节,而是侧重于评估基准的设计和实验结果的分析。评估基准的关键在于选择具有代表性的遥感数据集和任务,并设计合理的评估指标。论文使用了常用的分类和分割指标,例如准确率、F1-score、IoU等,来评估基础模型的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基础模型在有限标注数据下,相比于特定任务模型能够取得更好的性能。这表明基础模型在遥感任务中具有标签高效性,可以减少对大量标注数据的依赖。论文提出的评估基准为遥感领域的基础模型研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于多种遥感应用场景,例如精准农业、城市规划、灾害监测等。通过利用基础模型,可以减少对大量标注数据的依赖,降低遥感应用的开发成本,并提高模型的泛化能力,从而更好地服务于社会经济发展。
📄 摘要(原文)
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.