Generative artificial intelligence in ophthalmology: multimodal retinal images for the diagnosis of Alzheimer's disease with convolutional neural networks
作者: I. R. Slootweg, M. Thach, K. R. Curro-Tafili, F. D. Verbraak, F. H. Bouwman, Y. A. L. Pijnenburg, J. F. Boer, J. H. P. de Kwisthout, L. Bagheriye, P. J. González
分类: eess.IV, cs.CV, cs.LG
发布日期: 2024-06-26
💡 一句话要点
利用生成式AI和多模态视网膜图像,结合卷积神经网络辅助诊断阿尔茨海默病
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式AI 视网膜图像 阿尔茨海默病 卷积神经网络 多模态融合
📋 核心要点
- 现有方法难以仅通过视网膜图像准确预测阿尔茨海默病,缺乏有效的特征提取和模态融合手段。
- 利用DDPM生成合成视网膜图像,预训练CNNs,并结合多模态信息和元数据,提升诊断性能。
- 实验表明,合成数据预训练在部分模态上提升了分类性能,多模态融合和元数据集成效果最佳。
📝 摘要(中文)
本研究旨在利用多模态视网膜成像和卷积神经网络(CNNs)预测淀粉样蛋白PET(AmyloidPET)状态,并通过合成数据预训练提高性能。研究使用了来自59名AmyloidPET阳性和108名AmyloidPET阴性受试者的328只眼睛的眼底自发荧光、光学相干断层扫描(OCT)和OCT血管造影图像进行分类。训练去噪扩散概率模型(DDPMs)生成合成图像,并使用合成数据预训练单模态CNNs,然后在真实数据上进行微调,或仅在真实数据上进行训练。开发多模态分类器,将四个单模态CNNs的预测与患者元数据相结合。单模态分类器的类激活图提供了网络对输入的关注区域的洞察。结果表明,DDPMs生成了多样且逼真的图像,没有记忆化。使用合成数据预训练单模态CNNs,AUPR最多从0.350提高到0.579。将元数据集成到多模态CNNs中,AUPR从0.486提高到0.634,这是总体上最好的分类器。类激活图突出了与AD相关的相关视网膜区域。结论是,我们生成和利用合成数据的方法有潜力改善基于多模态视网膜成像的AmyloidPET预测。DDPM可以生成逼真且独特的多模态合成视网膜图像。我们表现最佳的单模态和多模态分类器没有使用合成数据进行预训练,但是使用合成数据进行预训练略微改善了四种模态中两种的分类性能。
🔬 方法详解
问题定义:论文旨在解决阿尔茨海默病(AD)的早期诊断问题,具体是通过分析视网膜图像来预测AmyloidPET状态。现有方法的痛点在于,仅依赖真实视网膜图像数据量有限,且不同模态信息融合不足,导致诊断准确率不高。
核心思路:论文的核心思路是利用生成式AI(DDPM)生成大量的合成视网膜图像,用于预训练卷积神经网络(CNNs),从而提升模型在真实数据上的泛化能力。同时,结合多模态视网膜图像信息(眼底自发荧光、OCT、OCTA)以及患者的元数据,进一步提高诊断的准确性。
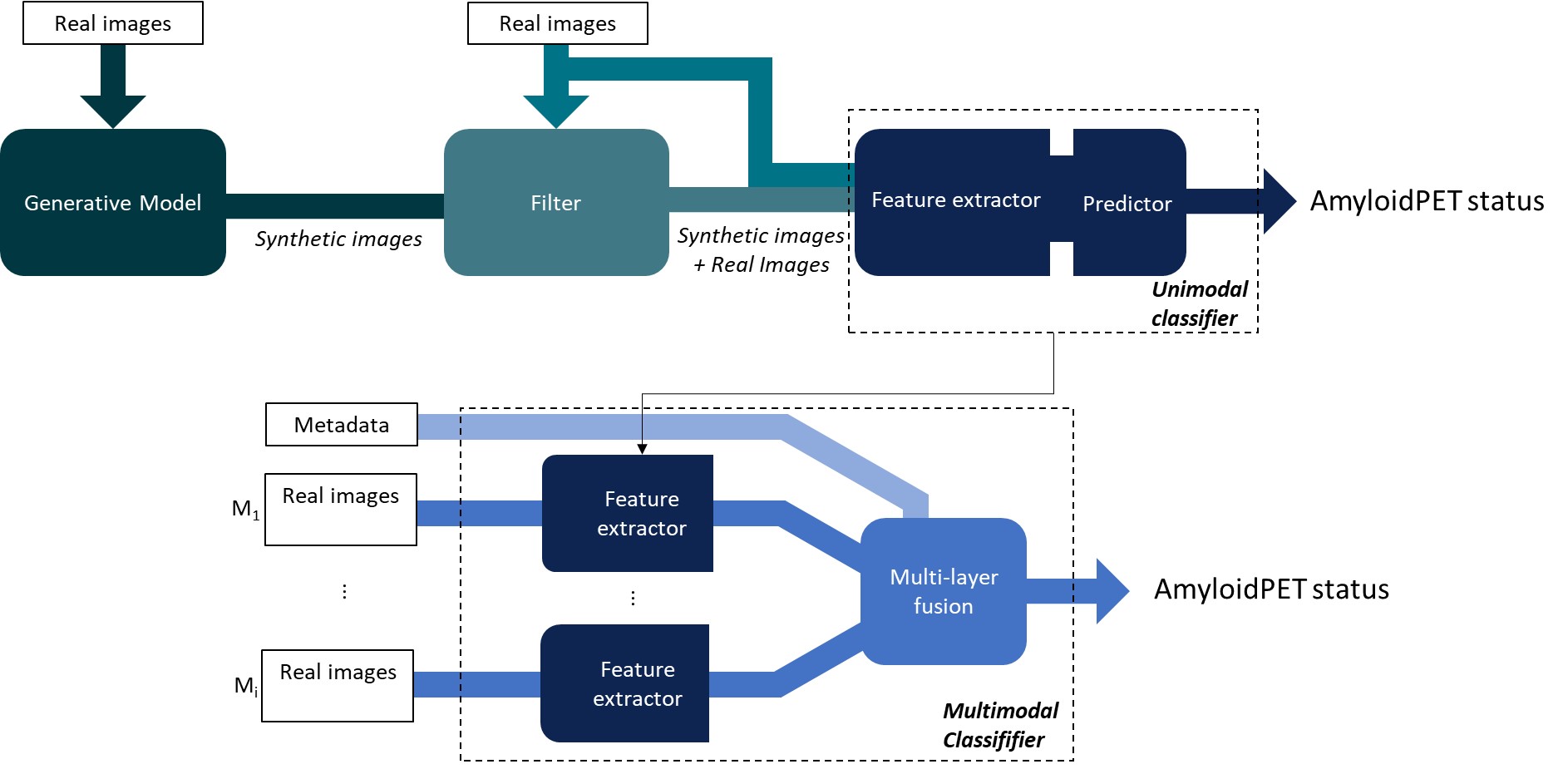
技术框架:整体框架包括以下几个主要模块:1) 使用DDPM生成合成视网膜图像;2) 使用合成数据预训练单模态CNNs;3) 在真实数据上微调或直接训练单模态CNNs;4) 构建多模态分类器,融合不同模态的预测结果和患者元数据。
关键创新:论文的关键创新在于将生成式AI应用于视网膜图像的合成,并利用合成数据进行预训练,以解决真实数据量不足的问题。此外,多模态信息的融合以及元数据的引入也提升了诊断的准确性。
关键设计:论文使用了Denoising Diffusion Probabilistic Models (DDPMs)来生成合成图像。对于CNNs,具体结构未知,但采用了预训练+微调的策略。多模态分类器如何融合不同模态的预测结果和元数据,论文中没有详细说明,但强调了元数据的重要性。损失函数和具体的网络结构等技术细节也未在摘要中提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用合成数据预训练单模态CNNs可以将AUPR最多从0.350提高到0.579。而将元数据集成到多模态CNNs中,AUPR从0.486提高到0.634,成为表现最佳的分类器。这表明合成数据预训练和多模态信息融合均能有效提升阿尔茨海默病的诊断性能。
🎯 应用场景
该研究成果可应用于阿尔茨海默病的早期筛查和诊断,通过分析视网膜图像,可以无创、快速地评估患者的患病风险。这有助于提前进行干预,延缓疾病进展,提高患者的生活质量。未来,该技术有望集成到眼科检查设备中,实现自动化诊断。
📄 摘要(原文)
Background/Aim. This study aims to predict Amyloid Positron Emission Tomography (AmyloidPET) status with multimodal retinal imaging and convolutional neural networks (CNNs) and to improve the performance through pretraining with synthetic data. Methods. Fundus autofluorescence, optical coherence tomography (OCT), and OCT angiography images from 328 eyes of 59 AmyloidPET positive subjects and 108 AmyloidPET negative subjects were used for classification. Denoising Diffusion Probabilistic Models (DDPMs) were trained to generate synthetic images and unimodal CNNs were pretrained on synthetic data and finetuned on real data or trained solely on real data. Multimodal classifiers were developed to combine predictions of the four unimodal CNNs with patient metadata. Class activation maps of the unimodal classifiers provided insight into the network's attention to inputs. Results. DDPMs generated diverse, realistic images without memorization. Pretraining unimodal CNNs with synthetic data improved AUPR at most from 0.350 to 0.579. Integration of metadata in multimodal CNNs improved AUPR from 0.486 to 0.634, which was the best overall best classifier. Class activation maps highlighted relevant retinal regions which correlated with AD. Conclusion. Our method for generating and leveraging synthetic data has the potential to improve AmyloidPET prediction from multimodal retinal imaging. A DDPM can generate realistic and unique multimodal synthetic retinal images. Our best performing unimodal and multimodal classifiers were not pretrained on synthetic data, however pretraining with synthetic data slightly improved classification performance for two out of the four modalities.