VDG: Vision-Only Dynamic Gaussian for Driving Simulation
作者: Hao Li, Jingfeng Li, Dingwen Zhang, Chenming Wu, Jieqi Shi, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, Junwei Han
分类: cs.CV
发布日期: 2024-06-26
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出VDG:一种仅使用视觉信息的动态高斯模型,用于驾驶仿真。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态场景重建 高斯溅射 视觉里程计 自监督学习 驾驶仿真
📋 核心要点
- 现有动态高斯方法依赖预计算位姿和SfM初始化,限制了其在动态驾驶场景中的应用。
- VDG通过集成自监督VO到动态高斯模型中,实现了无位姿的动态场景重建,提升了初始化质量。
- 实验表明,VDG仅使用RGB图像即可高效构建大规模动态场景,性能优于现有动态视角合成方法。
📝 摘要(中文)
动态高斯溅射技术在场景重建和新视角图像合成方面取得了显著进展。然而,现有方法严重依赖于预先计算的位姿,以及通过运动结构(SfM)算法或昂贵传感器进行的高斯初始化。本文首次通过将自监督视觉里程计(VO)集成到我们的无位姿动态高斯方法(VDG)中来解决这个问题,以提升位姿和深度初始化以及静态-动态分解。此外,VDG仅使用RGB图像输入即可工作,并能以更快的速度和更大的场景构建动态场景,优于无位姿动态视角合成方法。通过广泛的定量和定性实验,我们证明了该方法的鲁棒性。结果表明,我们的方法优于最先进的动态视角合成方法。额外的视频和源代码将在我们的项目页面上发布。
🔬 方法详解
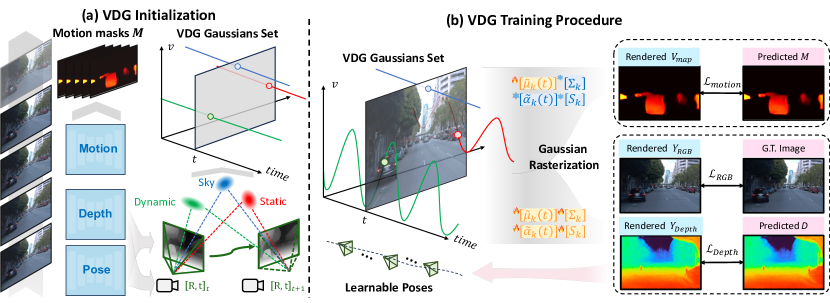
问题定义:现有动态高斯模型方法依赖于预先计算的相机位姿和通过SfM算法或昂贵传感器进行的高斯初始化。这限制了它们在动态驾驶场景等复杂环境中的应用,因为这些场景通常缺乏精确的位姿信息,且难以进行准确的SfM初始化。因此,如何仅使用视觉信息,实现动态场景的快速、准确重建,是本文要解决的核心问题。
核心思路:VDG的核心思路是将自监督视觉里程计(VO)集成到动态高斯模型中。VO负责估计相机的运动轨迹和场景深度,为高斯模型的初始化提供先验信息。通过自监督学习,VO可以在没有外部位姿信息的情况下进行训练,从而摆脱了对预计算位姿的依赖。同时,VO提供的深度信息可以辅助进行静态-动态分解,从而更好地处理动态场景。
技术框架:VDG的整体框架包括以下几个主要模块:1) 自监督视觉里程计(VO)模块:负责从RGB图像序列中估计相机的运动轨迹和场景深度。2) 动态高斯模型模块:使用3D高斯分布来表示场景,并根据相机位姿和深度信息进行初始化。3) 静态-动态分解模块:将场景分解为静态和动态部分,分别进行建模。4) 渲染模块:将高斯模型渲染成图像,并与真实图像进行比较,计算损失函数,从而优化模型参数。
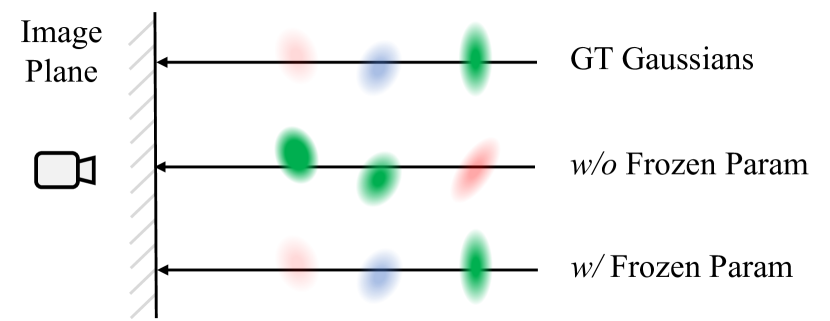
关键创新:VDG的关键创新在于将自监督VO与动态高斯模型相结合,实现了无位姿的动态场景重建。这与现有方法依赖预计算位姿或SfM初始化形成了本质区别。此外,VDG还提出了一种新的静态-动态分解方法,可以更好地处理动态场景。
关键设计:VDG的关键设计包括:1) 使用深度神经网络来实现自监督VO,并采用光度一致性损失和深度一致性损失进行训练。2) 使用3D高斯分布来表示场景,并采用可微分渲染技术进行优化。3) 设计了一种基于运动信息的静态-动态分解方法,将场景分解为静态和动态部分。4) 采用了一种自适应学习率策略,以加速模型训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VDG在动态场景重建方面取得了显著的性能提升。与最先进的动态视角合成方法相比,VDG在重建质量和速度方面均有优势。具体而言,VDG可以在更大的场景中进行重建,并且重建速度更快。此外,VDG仅使用RGB图像作为输入,无需额外的深度信息或位姿信息。
🎯 应用场景
VDG在驾驶仿真、自动驾驶、机器人导航等领域具有广泛的应用前景。它可以用于生成逼真的驾驶场景,为自动驾驶算法的训练和测试提供数据。此外,VDG还可以用于机器人导航,帮助机器人在动态环境中进行定位和路径规划。该研究的实际价值在于降低了动态场景重建的成本和难度,为相关领域的研究和应用提供了新的思路。
📄 摘要(原文)
Dynamic Gaussian splatting has led to impressive scene reconstruction and image synthesis advances in novel views. Existing methods, however, heavily rely on pre-computed poses and Gaussian initialization by Structure from Motion (SfM) algorithms or expensive sensors. For the first time, this paper addresses this issue by integrating self-supervised VO into our pose-free dynamic Gaussian method (VDG) to boost pose and depth initialization and static-dynamic decomposition. Moreover, VDG can work with only RGB image input and construct dynamic scenes at a faster speed and larger scenes compared with the pose-free dynamic view-synthesis method. We demonstrate the robustness of our approach via extensive quantitative and qualitative experiments. Our results show favorable performance over the state-of-the-art dynamic view synthesis methods. Additional video and source code will be posted on our project page at https://3d-aigc.github.io/VDG.