A Refer-and-Ground Multimodal Large Language Model for Biomedicine
作者: Xiaoshuang Huang, Haifeng Huang, Lingdong Shen, Yehui Yang, Fangxin Shang, Junwei Liu, Jia Liu
分类: cs.CV
发布日期: 2024-06-26 (更新: 2024-06-28)
备注: Accepted by MICCAI2024
💡 一句话要点
提出BiRD模型,首个用于生物医学图像Refer-and-Ground的多模态大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 生物医学图像 Refer-and-Ground 指令学习 医学影像分析
📋 核心要点
- 现有MLLM在生物医学领域应用受限,缺乏专门的生物医学图像Refer-and-Ground数据集是主要瓶颈。
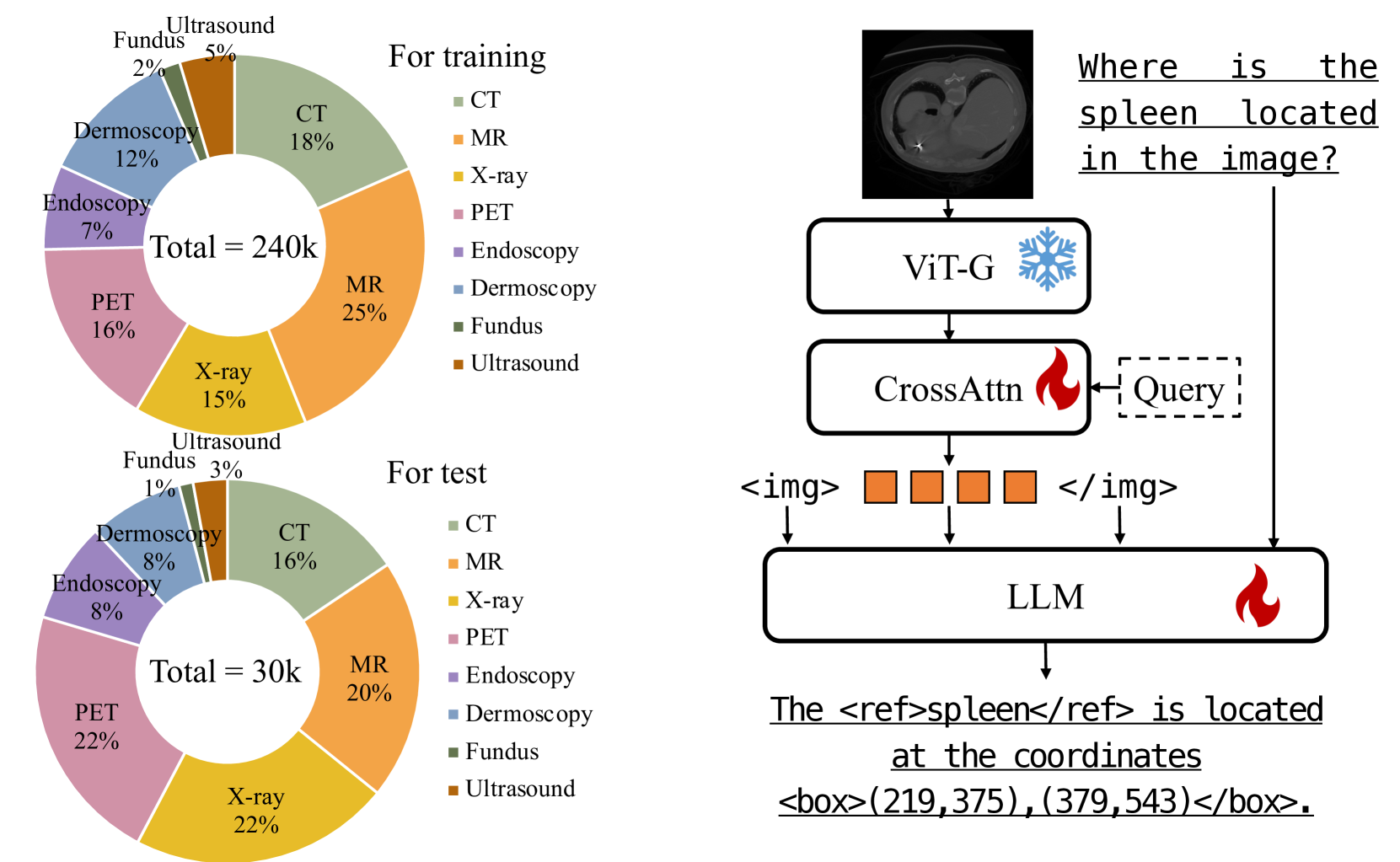
- 论文构建了Med-GRIT-270k数据集,并提出BiRD模型,实现生物医学图像的Refer-and-Ground交互。
- 实验验证了Med-GRIT-270k数据集的有效性,以及BiRD模型在多模态交互方面的优越性能。
📝 摘要(中文)
随着多模态大语言模型(MLLMs)的快速发展,特别是其通过Refer-and-Ground功能实现的视觉聊天能力,它们的重要性日益凸显。然而,生物医学领域在这方面存在显著差距,主要是由于缺乏专门用于生物医学图像的Refer-and-Ground数据集。为了解决这一挑战,我们设计了Med-GRIT-270k数据集,它包含27万个问答对,涵盖八种不同的医学成像模式。最重要的是,它是第一个专门针对生物医学领域并整合Refer-and-Ground对话的数据集。核心思想是从医学分割数据集中采样大规模的生物医学图像-掩码对,并使用chatGPT从文本生成指令数据集。此外,我们通过使用该数据集和多任务指令学习,引入了用于生物医学的Refer-and-Ground多模态大语言模型(BiRD)。大量的实验证实了Med-GRIT-270k数据集的有效性和BiRD模型的多模态、细粒度交互能力。这对于探索和开发智能生物医学助手具有重要的参考价值。
🔬 方法详解
问题定义:现有方法缺乏专门针对生物医学图像的Refer-and-Ground数据集,导致多模态大语言模型难以在该领域应用。现有的通用MLLM无法有效处理生物医学图像的细粒度信息和专业知识,限制了其在智能生物医学助手方面的潜力。
核心思路:论文的核心思路是构建一个大规模的生物医学图像Refer-and-Ground数据集(Med-GRIT-270k),并在此基础上训练一个专门的MLLM(BiRD)。通过指令学习,使BiRD模型能够理解和执行与生物医学图像相关的Refer-and-Ground任务。这样设计的目的是为了弥补现有方法在生物医学领域的不足,并为开发智能生物医学助手奠定基础。
技术框架:整体框架包含两个主要部分:数据集构建和模型训练。数据集构建阶段,从医学分割数据集中采样图像-掩码对,并利用ChatGPT生成问答对,构成Med-GRIT-270k数据集。模型训练阶段,使用Med-GRIT-270k数据集对BiRD模型进行多任务指令学习,使其具备Refer-and-Ground能力。
关键创新:最重要的技术创新点在于构建了首个专门用于生物医学图像的Refer-and-Ground数据集Med-GRIT-270k。该数据集的规模和多样性为训练高性能的生物医学MLLM提供了数据基础。此外,BiRD模型通过多任务指令学习,能够更好地理解和处理生物医学图像的细粒度信息。
关键设计:Med-GRIT-270k数据集包含27万个问答对,涵盖八种不同的医学成像模式。数据集的构建过程中,使用了ChatGPT进行数据增强和指令生成。BiRD模型采用多任务学习框架,同时学习Refer-and-Ground任务和其他相关的视觉语言任务。具体的网络结构和损失函数等细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文构建的Med-GRIT-270k数据集包含27万个问答对,涵盖八种医学成像模式,是首个生物医学图像Refer-and-Ground数据集。BiRD模型在Med-GRIT-270k数据集上进行了有效训练,展现了强大的多模态交互能力,为生物医学领域的智能助手开发提供了重要参考。
🎯 应用场景
该研究成果可应用于智能生物医学助手开发,辅助医生进行疾病诊断、治疗方案制定和医学图像分析。例如,医生可以通过自然语言与模型交互,指定图像中的特定区域,并询问相关信息。未来,该技术有望提升医疗效率,改善患者护理质量,并促进医学研究的进展。
📄 摘要(原文)
With the rapid development of multimodal large language models (MLLMs), especially their capabilities in visual chat through refer and ground functionalities, their significance is increasingly recognized. However, the biomedical field currently exhibits a substantial gap in this area, primarily due to the absence of a dedicated refer and ground dataset for biomedical images. To address this challenge, we devised the Med-GRIT-270k dataset. It comprises 270k question-and-answer pairs and spans eight distinct medical imaging modalities. Most importantly, it is the first dedicated to the biomedical domain and integrating refer and ground conversations. The key idea is to sample large-scale biomedical image-mask pairs from medical segmentation datasets and generate instruction datasets from text using chatGPT. Additionally, we introduce a Refer-and-Ground Multimodal Large Language Model for Biomedicine (BiRD) by using this dataset and multi-task instruction learning. Extensive experiments have corroborated the efficacy of the Med-GRIT-270k dataset and the multi-modal, fine-grained interactive capabilities of the BiRD model. This holds significant reference value for the exploration and development of intelligent biomedical assistants.