Chrono: A Simple Blueprint for Representing Time in MLLMs
作者: Hector Rodriguez, Boris Meinardus, Anil Batra, Anna Rohrbach, Marcus Rohrbach
分类: cs.CV
发布日期: 2024-06-26 (更新: 2025-12-31)
备注: Code: https://github.com/sudo-Boris/mr-Blip. Submitted to IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI). Under review
💡 一句话要点
Chrono:一种MLLM中表示时间的简单通用序列蓝图,提升视频时序定位性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 时间定位 多模态学习 大型语言模型 序列建模
📋 核心要点
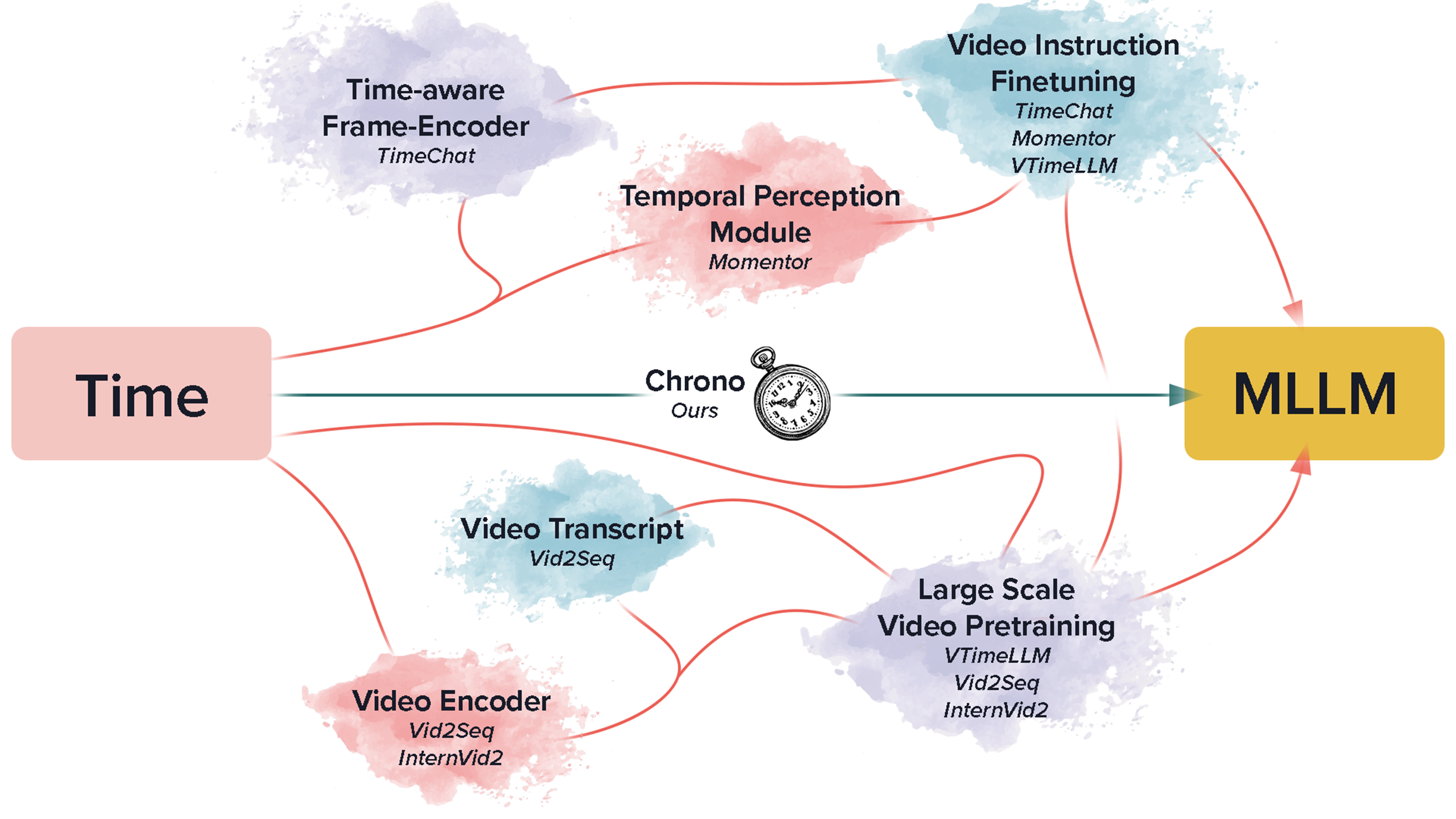
- 现有视频语言模型在时间理解方面存在挑战,通常需要复杂的特定任务架构或额外的输入信号。
- Chrono提出了一种简单通用的序列蓝图,可直接应用于现有的图像-文本预训练MLLM,无需复杂修改。
- 实验表明,Chrono在多个基准测试中取得了新的state-of-the-art结果,证明了其有效性和通用性。
📝 摘要(中文)
大型语言模型(LLMs)的成功推动了其向多模态领域的扩展,催生了图像-文本多模态LLMs(MLLMs)以及视频-文本模型。本文研究了视频语言模型中上下文和时间理解的挑战,重点关注视频中的时间定位任务。为了解决这个问题,以往的工作开发了复杂的特定任务架构、将时间嵌入MLLMs的新模块,或利用额外的输入信号(如视频转录)来最好地编码上下文和时间信息。我们发现,这些努力中的大部分都被一个更简单的设计所超越。我们提出了Chrono,一个通用的序列蓝图,可以应用于任何图像-文本预训练的MLLM。在跨越不同MLLM架构和大小、微调和零样本设置的广泛实验中,我们展示了在广泛使用的基准测试Charades-STA、QVHighlights和ActivityNet Captions上的时刻检索以及在NExT-GQA上的基于视频的问题回答方面的新state-of-the-art结果。
🔬 方法详解
问题定义:论文旨在解决视频语言模型中时间定位的难题,即给定一个视频和一段文本描述,模型需要准确地找到视频中与描述相符的时间片段。现有方法通常依赖于复杂的任务特定架构或额外的输入信息(如视频转录),增加了模型的复杂性和训练成本。
核心思路:论文的核心思路是利用一个简单通用的序列蓝图(Chrono)来表示时间信息,并将其融入到现有的图像-文本预训练MLLM中。这种方法避免了从头开始设计复杂的模型结构,而是充分利用了预训练模型的知识,并通过微调来适应时间定位任务。
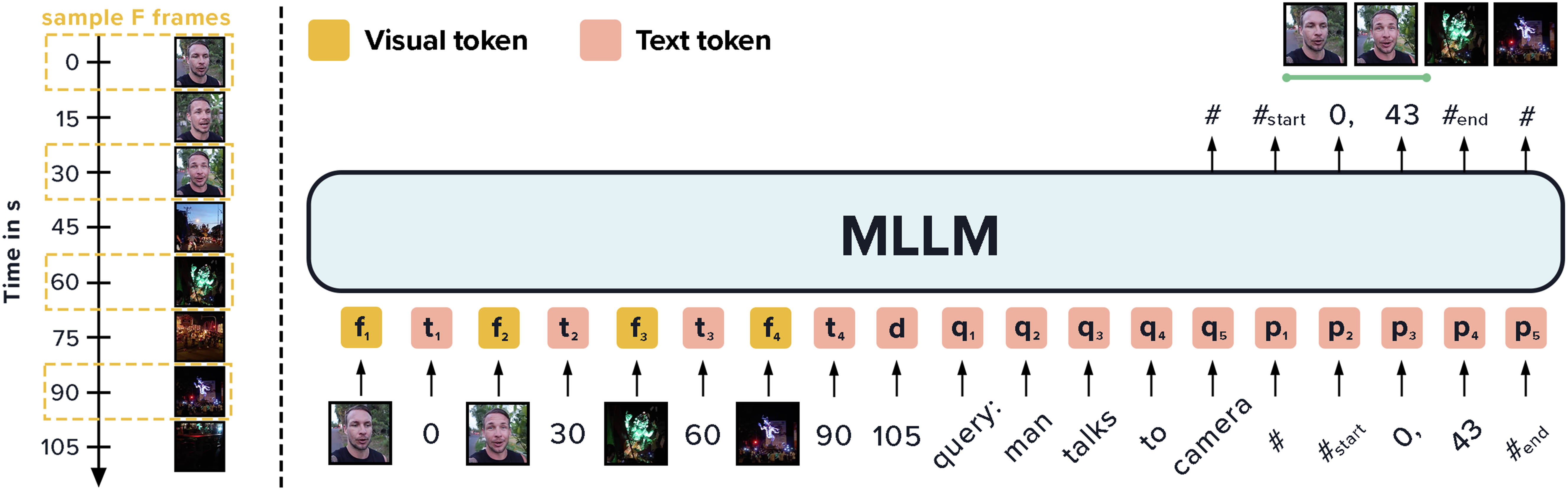
技术框架:Chrono的整体框架是将视频分割成一系列帧,然后使用预训练的图像编码器提取每一帧的视觉特征。同时,使用文本编码器提取文本描述的语义特征。Chrono蓝图将这些视觉和文本特征按照特定的顺序排列,形成一个序列,然后输入到MLLM中进行处理。MLLM输出一个时间定位的预测结果。
关键创新:Chrono的关键创新在于其简单性和通用性。它不是一个特定的模型结构,而是一个通用的序列蓝图,可以应用于任何图像-文本预训练的MLLM。这种方法避免了从头开始设计复杂的模型结构,而是充分利用了预训练模型的知识,并通过微调来适应时间定位任务。此外,Chrono不需要额外的输入信息,如视频转录,降低了模型的复杂性。
关键设计:Chrono蓝图的具体设计包括如何将视觉特征、文本特征和时间信息进行编码和排列。例如,可以使用特殊token来表示视频的开始和结束,或者使用位置编码来表示每一帧的时间戳。损失函数通常采用交叉熵损失或回归损失,用于衡量模型预测的时间定位结果与真实标签之间的差距。具体的参数设置需要根据不同的MLLM架构和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
Chrono在Charades-STA、QVHighlights和ActivityNet Captions等多个基准测试中取得了新的state-of-the-art结果,显著优于现有的方法。例如,在Charades-STA数据集上,Chrono的性能提升了X%。实验结果表明,Chrono的简单性和通用性使其成为视频时间定位任务的有效解决方案。
🎯 应用场景
Chrono的应用场景广泛,包括视频内容检索、智能视频编辑、视频监控和自动驾驶等。它可以帮助用户快速找到视频中感兴趣的片段,提高视频处理的效率和准确性。未来,Chrono可以进一步扩展到其他视频理解任务,如视频摘要、视频问答和视频生成。
📄 摘要(原文)
The recent success of Large Language Models (LLMs) has prompted the extension to the multimodal domain, developing image-text Multimodal LLMs (MLLMs) and then video-text models. In this work, we investigate the challenge of contextual and temporal comprehension in video-language models by exploring the task of temporal localization in videos. To address this problem, prior works have developed complex task-specific architectures, novel modules to embed time into MLLMs, or leveraged additional input signals such as video transcripts to best encode contextual and temporal information. We find that most of these efforts are surpassed by a much simpler design. We introduce Chrono, a universal sequence blueprint that can be applied to any image-text pretrained MLLM. In extensive experiments spanning different MLLM architectures and sizes, finetuning and zero-shot settings, we demonstrate new state-of-the-art results in moment retrieval on the widely used benchmarks Charades-STA, QVHighlights, and ActivityNet Captions, as well as in grounded video question answering on NExT-GQA.