video-SALMONN: Speech-Enhanced Audio-Visual Large Language Models
作者: Guangzhi Sun, Wenyi Yu, Changli Tang, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Yuxuan Wang, Chao Zhang
分类: cs.CV
发布日期: 2024-06-22
备注: Accepted at ICML 2024. arXiv admin note: substantial text overlap with arXiv:2310.05863
🔗 代码/项目: GITHUB
💡 一句话要点
提出video-SALMONN以解决视频理解中的语音增强问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 音视频大语言模型 语音增强 多模态融合 深度学习
📋 核心要点
- 现有的音视频大语言模型在语音理解方面存在不足,未能充分利用音频和视觉信息的结合。
- 本文提出的video-SALMONN通过多分辨率因果Q-Former结构有效连接音视频编码器与大语言模型,提升语音理解能力。
- 实验结果显示,video-SALMONN在视频问答和音视频问答任务上均显著提高了准确率,展示了其卓越的理解与推理能力。
📝 摘要(中文)
语音理解作为视频理解中音视频大语言模型(av-LLMs)的一个重要但尚未充分研究的方面,本文提出了video-SALMONN,一个端到端的av-LLM用于视频处理,能够理解视觉帧序列、音频事件、音乐以及语音。为获取语音理解所需的细粒度时间信息,同时保持对其他视频元素的高效处理,本文提出了一种新颖的多分辨率因果Q-Former(MRC Q-Former)结构,连接预训练的音视频编码器和主干大语言模型。此外,提出了多样性损失和无配对音视频混合训练方案,以避免帧或模态的主导性。在引入的语音-音频-视频评估基准上,video-SALMONN在视频问答任务上实现了超过25%的绝对准确率提升,在包含人类语音的音视频问答任务上实现了超过30%的绝对准确率提升。
🔬 方法详解
问题定义:本文旨在解决现有音视频大语言模型在语音理解方面的不足,尤其是在处理视频内容时对语音信息的低效利用。现有方法往往无法有效整合音频、视觉和语音信息,导致理解能力受限。
核心思路:论文提出的video-SALMONN通过引入多分辨率因果Q-Former结构,旨在高效提取语音理解所需的细粒度时间信息,同时保持对其他视频元素的处理效率。该设计使得模型能够更好地融合多模态信息。
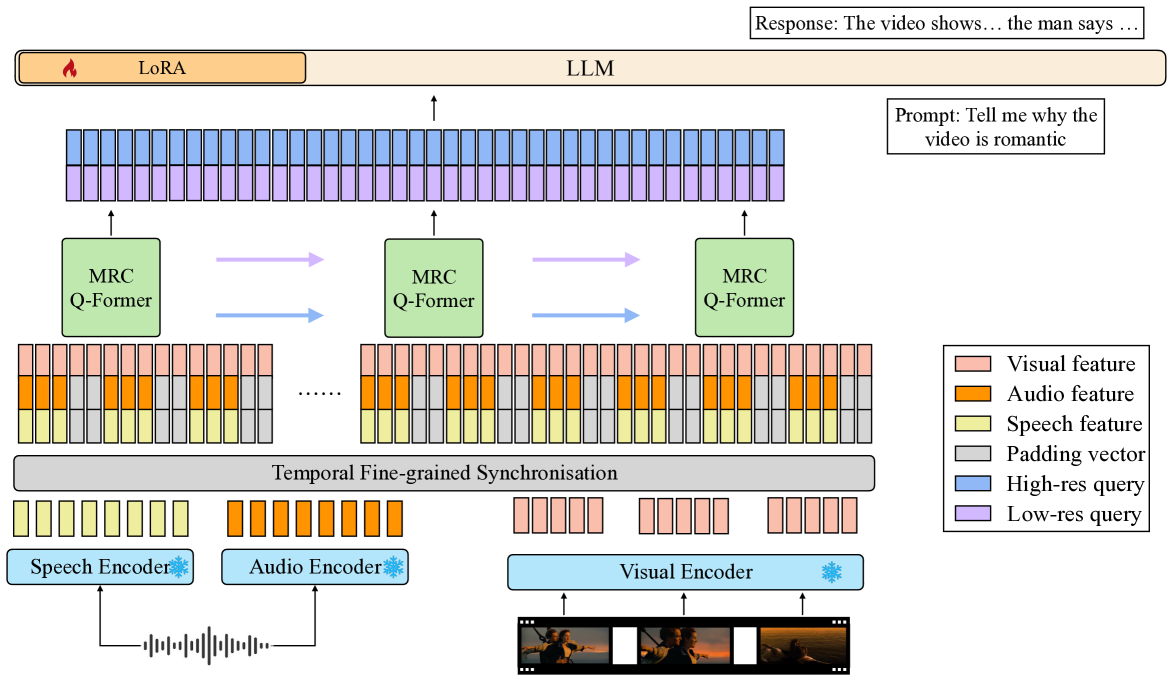
技术框架:video-SALMONN的整体架构包括多个模块:首先是预训练的音视频编码器,接着是多分辨率因果Q-Former,最后是主干大语言模型。该框架能够有效地处理视觉帧、音频事件和语音信息。
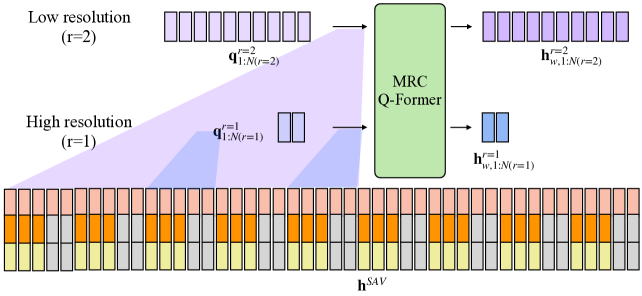
关键创新:最重要的技术创新在于多分辨率因果Q-Former的设计,它能够在不同分辨率下捕捉时间信息,显著提升了语音理解的准确性和效率。这一创新与现有方法在信息整合方式上有本质区别。
关键设计:在训练过程中,采用了多样性损失和无配对音视频混合训练方案,以避免模型在某一模态上的主导性。此外,MRC Q-Former的结构设计也考虑了如何在保持计算效率的同时提升模型的理解能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,video-SALMONN在视频问答任务上实现了超过25%的绝对准确率提升,而在包含人类语音的音视频问答任务上则实现了超过30%的绝对准确率提升。这些结果显著优于现有的音视频大语言模型,展示了其卓越的理解和推理能力。
🎯 应用场景
该研究的潜在应用领域包括智能视频分析、自动字幕生成、视频内容检索等。通过提升视频理解中的语音处理能力,video-SALMONN能够为多模态交互系统提供更为精准的理解与响应,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Speech understanding as an element of the more generic video understanding using audio-visual large language models (av-LLMs) is a crucial yet understudied aspect. This paper proposes video-SALMONN, a single end-to-end av-LLM for video processing, which can understand not only visual frame sequences, audio events and music, but speech as well. To obtain fine-grained temporal information required by speech understanding, while keeping efficient for other video elements, this paper proposes a novel multi-resolution causal Q-Former (MRC Q-Former) structure to connect pre-trained audio-visual encoders and the backbone large language model. Moreover, dedicated training approaches including the diversity loss and the unpaired audio-visual mixed training scheme are proposed to avoid frames or modality dominance. On the introduced speech-audio-visual evaluation benchmark, video-SALMONN achieves more than 25\% absolute accuracy improvements on the video-QA task and over 30\% absolute accuracy improvements on audio-visual QA tasks with human speech. In addition, video-SALMONN demonstrates remarkable video comprehension and reasoning abilities on tasks that are unprecedented by other av-LLMs. Our training code and model checkpoints are available at \texttt{\url{https://github.com/bytedance/SALMONN/}}.