TraceNet: Segment one thing efficiently
作者: Mingyuan Wu, Zichuan Liu, Haozhen Zheng, Hongpeng Guo, Bo Chen, Xin Lu, Klara Nahrstedt
分类: cs.CV
发布日期: 2024-06-21 (更新: 2025-08-27)
备注: Best Student Paper in IEEE MIPR 2025
💡 一句话要点
TraceNet:高效单实例分割,通过用户点击驱动,专为移动端成像应用设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 单实例分割 用户交互 感受野追踪 移动端应用 高效分割
📋 核心要点
- 现有实例分割方法计算量大,难以在移动端实时应用,限制了移动成像应用的潜力。
- TraceNet通过用户点击定位目标实例,仅在相关区域进行计算,显著降低了计算成本。
- 实验表明,TraceNet在MS-COCO和LVIS数据集上实现了高效的单实例分割,兼顾了效率和交互性。
📝 摘要(中文)
本文提出了一种高效的单实例分割方法,旨在解决移动成像应用中(如拍摄或编辑)的性能瓶颈。现有移动应用通常将分割任务限定于人像或显著物体,这是由于计算资源的限制。尽管实例分割在网络效率方面有所进展,但由于需要在整张图像上进行计算以识别所有实例,其计算成本仍然很高。为了解决这个问题,我们提出了一种由用户点击驱动的单实例分割任务,即分割用户通过点击选择的单个实例。与分割一切的通用模型(如SAM)不同,该任务专注于高效地分割用户指定的单个实例。为此,我们提出了TraceNet,它通过感受野追踪显式地定位所选实例。TraceNet识别与用户点击相关的图像区域,并且仅在这些区域上执行高计算量的操作。因此,在推理过程中,总体计算成本和内存消耗得以降低。我们在MS-COCO和LVIS数据集上评估了TraceNet的性能,实验结果表明该方法在效率和交互性方面均表现出色,填补了高效移动端推理需求与多模态交互式分割模型研究趋势之间的空白。
🔬 方法详解
问题定义:现有实例分割方法需要在整张图像上进行计算以识别所有实例,计算量大,难以在移动端等资源受限的平台上实时应用。这限制了移动成像应用中诸如目标编辑等功能的实现。因此,如何在保证分割质量的前提下,降低计算复杂度,是本文要解决的核心问题。
核心思路:本文的核心思路是利用用户交互(点击)来引导分割过程,从而避免对整张图像进行密集计算。通过用户点击,可以快速定位到感兴趣的实例,然后仅在该实例相关的区域进行精细分割。这种“按需分割”的方式可以显著降低计算量,提高分割效率。
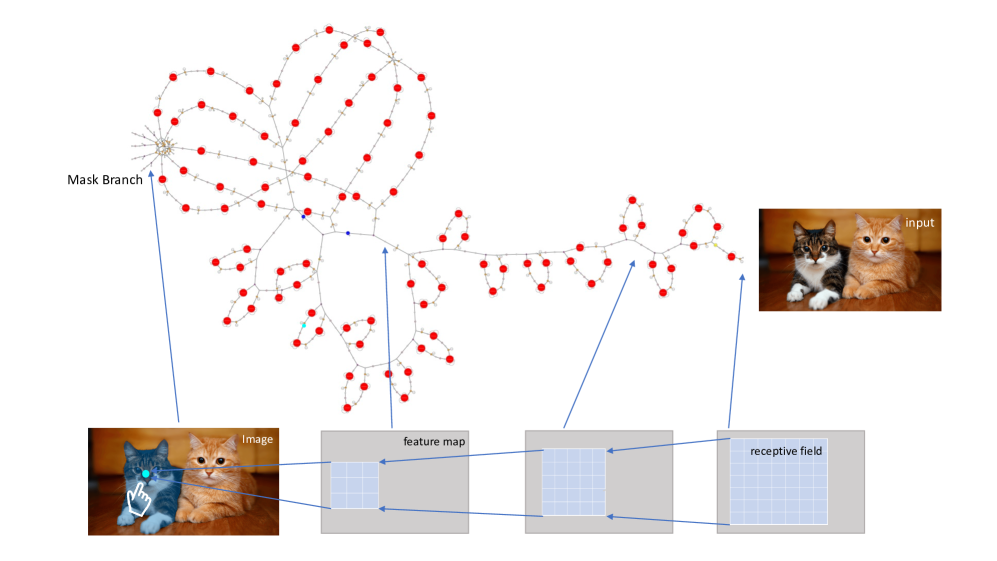
技术框架:TraceNet的整体框架包含以下几个主要步骤:1) 用户在图像上进行点击,指定要分割的实例;2) TraceNet利用感受野追踪技术,根据用户点击的位置,确定与该实例相关的图像区域;3) 在确定的图像区域上进行高精度的实例分割;4) 输出分割结果。该框架的关键在于感受野追踪模块,它负责根据用户点击定位相关区域。
关键创新:TraceNet的关键创新在于将用户交互与感受野追踪技术相结合,实现了高效的单实例分割。与传统的实例分割方法相比,TraceNet不需要对整张图像进行计算,而是通过用户点击和感受野追踪,将计算量集中在与目标实例相关的区域。这种“按需计算”的方式显著降低了计算复杂度,提高了分割效率。
关键设计:TraceNet的具体实现细节包括:1) 感受野追踪模块的设计,需要精确地确定与用户点击相关的图像区域;2) 分割网络的结构,需要在保证分割精度的前提下,尽可能地降低计算量;3) 损失函数的设计,需要同时考虑分割精度和计算效率。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
TraceNet在MS-COCO和LVIS数据集上进行了实验验证,结果表明该方法在保证分割精度的前提下,显著降低了计算量。具体来说,TraceNet能够在移动端实现实时的单实例分割,并且分割精度与现有的实例分割方法相当。实验结果还表明,TraceNet对用户点击位置具有较强的鲁棒性,即使点击位置略有偏差,也能准确地分割出目标实例。
🎯 应用场景
TraceNet具有广泛的应用前景,尤其是在移动成像领域。它可以用于移动端的图像编辑应用,例如快速抠图、目标替换等。此外,TraceNet还可以应用于增强现实(AR)和虚拟现实(VR)等领域,实现对用户感兴趣物体的实时分割和交互。该研究的未来影响在于推动移动端智能图像处理技术的发展,提升用户体验。
📄 摘要(原文)
Efficient single instance segmentation is essential for unlocking features in the mobile imaging applications, such as capture or editing. Existing on-the-fly mobile imaging applications scope the segmentation task to portraits or the salient subject due to the computational constraints. Instance segmentation, despite its recent developments towards efficient networks, is still heavy due to the cost of computation on the entire image to identify all instances. To address this, we propose and formulate a one tap driven single instance segmentation task that segments a single instance selected by a user via a positive tap. This task, in contrast to the broader task of segmenting anything as suggested in the Segment Anything Model \cite{sam}, focuses on efficient segmentation of a single instance specified by the user. To solve this problem, we present TraceNet, which explicitly locates the selected instance by way of receptive field tracing. TraceNet identifies image regions that are related to the user tap and heavy computations are only performed on selected regions of the image. Therefore overall computation cost and memory consumption are reduced during inference. We evaluate the performance of TraceNet on instance IoU average over taps and the proportion of the region that a user tap can fall into for a high-quality single-instance mask. Experimental results on MS-COCO and LVIS demonstrate the effectiveness and efficiency of the proposed approach. TraceNet can jointly achieve the efficiency and interactivity, filling in the gap between needs for efficient mobile inference and recent research trend towards multimodal and interactive segmentation models.