CLIP-Decoder : ZeroShot Multilabel Classification using Multimodal CLIP Aligned Representation
作者: Muhammad Ali, Salman Khan
分类: cs.CV
发布日期: 2024-06-21
备注: Accepted at ICCVW- VLAR
💡 一句话要点
提出CLIP-Decoder,利用多模态对齐表征实现零样本多标签分类
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 多标签分类 CLIP模型 多模态学习 特征对齐 ML-Decoder 图像分类
📋 核心要点
- 现有多标签零样本学习方法在处理未见类别时,存在语义鸿沟和特征对齐问题。
- CLIP-Decoder通过多模态表征学习,对齐图像和文本特征,减少语义不匹配。
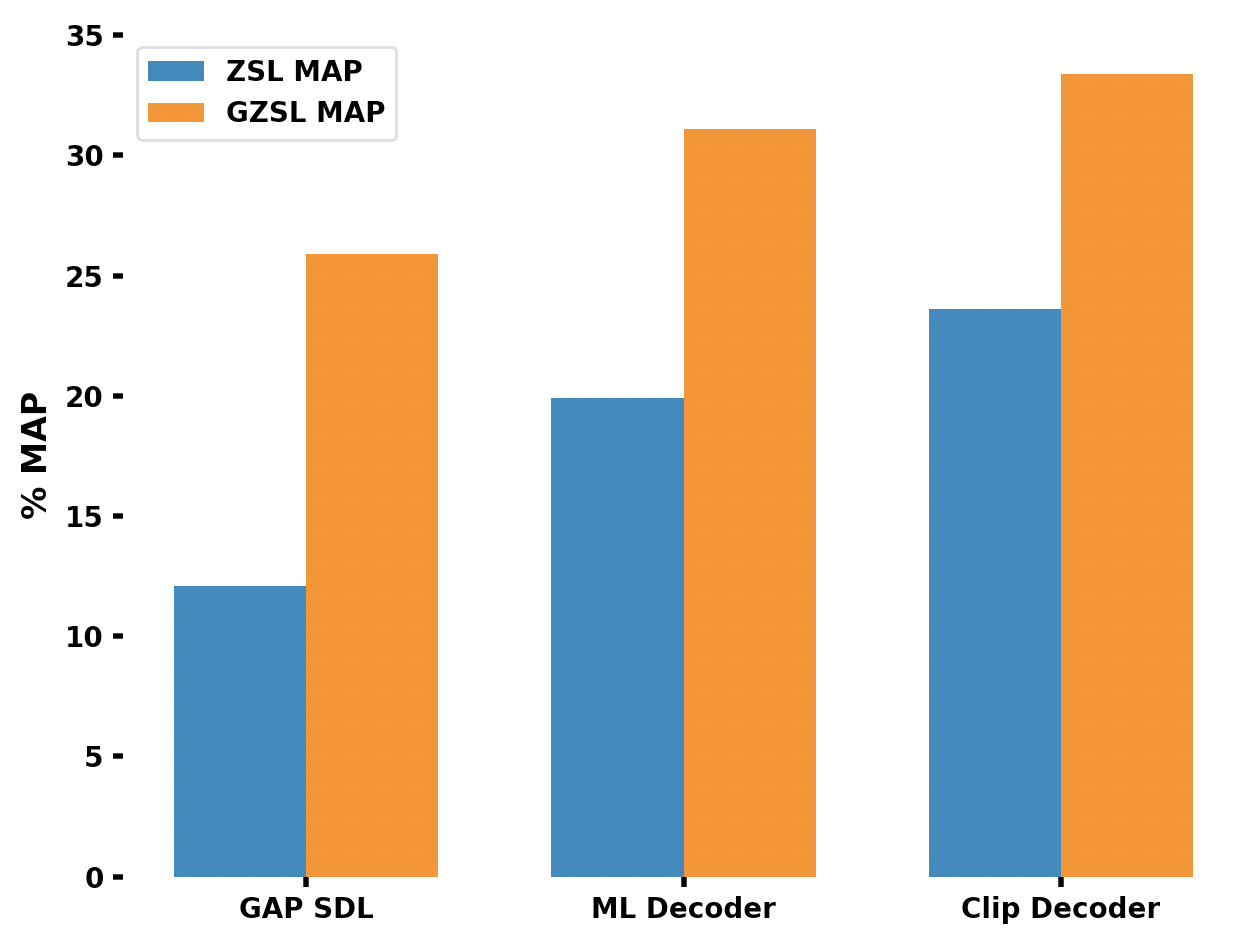
- 实验结果表明,CLIP-Decoder在零样本多标签分类任务上显著优于现有方法。
📝 摘要(中文)
多标签分类是现实世界中广泛应用的重要任务。多标签零样本学习是一种将图像分类到多个未见过的类别中的方法,而无需任何训练数据。本文提出了一种基于最先进的ML-Decoder注意力头的CLIP-Decoder新方法。CLIP-Decoder引入了多模态表征学习,利用文本编码器提取文本特征,图像编码器提取图像特征。此外,通过对齐图像和单词嵌入到相同的维度,并使用包含分类损失和CLIP损失的组合损失比较它们各自的表征,从而最小化语义不匹配。该策略优于其他方法,并在使用CLIP-Decoder的零样本多标签分类任务中取得了最先进的结果。与现有的零样本学习多标签分类任务方法相比,我们的方法在性能上绝对提高了3.9%。此外,在广义零样本学习多标签分类任务中,我们的方法表现出令人印象深刻的近2.3%的增长。
🔬 方法详解
问题定义:论文旨在解决零样本多标签分类问题,即在没有见过标签的训练数据的情况下,将图像准确地分类到多个标签。现有方法通常难以有效利用图像和文本信息,存在语义鸿沟,导致分类性能不佳。
核心思路:论文的核心思路是利用CLIP模型强大的多模态表征能力,将图像和文本特征映射到同一语义空间,并通过对齐图像和文本嵌入来减少语义不匹配。通过这种方式,模型可以更好地理解图像内容,并将其与未见过的标签关联起来。
技术框架:CLIP-Decoder的整体框架包括以下几个主要模块:1) 图像编码器:使用CLIP的图像编码器提取图像的视觉特征。2) 文本编码器:使用CLIP的文本编码器提取标签文本的语义特征。3) 特征对齐模块:将图像和文本特征映射到同一维度空间,并计算它们之间的相似度。4) ML-Decoder:使用ML-Decoder注意力头进行多标签分类。5) 损失函数:使用分类损失和CLIP损失的组合损失来训练模型。
关键创新:论文的关键创新在于将CLIP模型与ML-Decoder相结合,并引入了多模态表征学习和特征对齐机制。通过这种方式,模型可以更好地利用图像和文本信息,减少语义不匹配,从而提高零样本多标签分类的性能。与现有方法相比,CLIP-Decoder能够更有效地利用预训练的CLIP模型的知识,并将其迁移到零样本多标签分类任务中。
关键设计:论文的关键设计包括:1) 使用CLIP的预训练图像和文本编码器,以获得高质量的图像和文本特征。2) 使用线性层将图像和文本特征映射到同一维度空间。3) 使用余弦相似度计算图像和文本特征之间的相似度。4) 使用二元交叉熵损失作为分类损失。5) 使用CLIP损失来对齐图像和文本特征。
🖼️ 关键图片

📊 实验亮点
CLIP-Decoder在零样本多标签分类任务上取得了显著的性能提升。在标准零样本学习设置下,该方法比现有方法提高了3.9%。在广义零样本学习设置下,该方法提高了2.3%。这些结果表明,CLIP-Decoder能够有效地利用多模态信息,并将其迁移到未见过的类别中。
🎯 应用场景
该研究成果可应用于图像检索、内容审核、自动标注等领域。例如,在电商平台上,可以利用该技术自动识别商品的多个属性标签,提高搜索效率和用户体验。在医疗领域,可以辅助医生诊断疾病,例如根据医学影像识别多种病灶。该技术具有广泛的应用前景,并有望推动人工智能在多标签分类任务中的发展。
📄 摘要(原文)
Multi-label classification is an essential task utilized in a wide variety of real-world applications. Multi-label zero-shot learning is a method for classifying images into multiple unseen categories for which no training data is available, while in general zero-shot situations, the test set may include observed classes. The CLIP-Decoder is a novel method based on the state-of-the-art ML-Decoder attention-based head. We introduce multi-modal representation learning in CLIP-Decoder, utilizing the text encoder to extract text features and the image encoder for image feature extraction. Furthermore, we minimize semantic mismatch by aligning image and word embeddings in the same dimension and comparing their respective representations using a combined loss, which comprises classification loss and CLIP loss. This strategy outperforms other methods and we achieve cutting-edge results on zero-shot multilabel classification tasks using CLIP-Decoder. Our method achieves an absolute increase of 3.9% in performance compared to existing methods for zero-shot learning multi-label classification tasks. Additionally, in the generalized zero-shot learning multi-label classification task, our method shows an impressive increase of almost 2.3%.